Subword Tokenization Algorithms
Overview
Although NLP is sometimes taken for granted, it's important to remember that machines only understand numbers, not letters, words, or phrases. Therefore, text manipulation and cleaning—what we often refer to in NLP as text pre-processing—are necessary if we work with the vast amount of text data freely available on the internet. Preprocessing is a multi-stage procedure in and of itself. Pre-processing is the first stage in dealing with text and creating a model to address our business challenge. We will mainly discuss Tokenization and tokenizer.
Introduction
Linguistics and mathematics combine in natural language processing (NLP) to link human and computer languages. Working with natural language has several challenges, particularly when dealing with people who need to be used to modifying their speech for algorithms. Humans won't obey the norms for speech and writing, even if we can build programs around them. Linguistics is the study of language's formal and informal norms. The area of computational linguistics is expanding due to the limits of formal linguistics. Linguists can learn more about how human language functions using enormous datasets, and they can apply this knowledge to improve natural language processing.
This branch of NLP, statistical NLP, has become the industry standard in this area. Statistical NLP fills the gap between how language should be used and how it is used using statistics collected from a lot of data.
What is Tokenization?
Tokenization is dividing a phrase, sentence, paragraph, or one or more text documents into smaller components which are known as tokens. These tokens could be a word, a subword, or simply a single character. Tokenization is carried out by several algorithms using various procedures. However, the example below will give you a broad understanding of how these three differ.
Take a look at the following statement:
"Don't waste food."
The sentence will be divided into words by a tokenization algorithm based on words. The most typical splitting is based on available space.
["Don't", "waste", "food"]
The sentence will be divided into subwords tokenization algorithm based on subwords.
["Do", "n't", "waste", "food"]
The sentence will be divided into characters by a character-based tokenization technique.
["D", "o", "n"," ' ", "t", "w", "a", "s", "t", "e", "f", "o", "o", "d"]
All NLP models operate at the token level while processing raw text. The vocabulary, a collection of certain tokens in a corpus(a dataset in NLP), is created using these tokens. Then, this vocabulary is transformed into numbers (IDs), which aids in modeling.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Word-based Tokenization
Based on a delimiter, it divides a text block into words. Space is the most widely used delimiter. Additionally, you can divide your content using punctuation and space as additional delimiters. You will receive several word-level tokens depending on the delimiter selected.
Word-based Tokenization is simple to implement using a customized RegEx or Python's split() method. NLTK, spaCy, Keras, and Gensim are Python modules that may simplify Tokenization. Consider the below statement:
"Don't stop until you're proud."
Perform word-based Tokenization with delimiter as space we get:
["Don't", "stop", "until", "you're", "proud."]
Because we don't want our model to learn various representations of the same word with every potential punctuation, we need to consider punctuation while conducting Tokenization. If we permit our model to accomplish this, the make representations of the model (each word's number of punctuation marks in a language) will blow our minds. Let's consider punctuation, then.
["Don", " ' ", "t", "until", "you", " ' ", "re", "proud", " . "]
If the model had seen the word "doesn't", it would have to tokenize it into "does" and "n't," and since the model would have previously learned about "n't" in the past, it would have used its knowledge here. Better Tokenization of "don't" would have been "do" and "n't." Although the issue appears difficult, it is manageable by following basic criteria. But as we can see, the word "don't" now comprises three tokens: "don", " ' ", and "t".
Modern NLP models have their tokenizers since each does its Tokenization differently and uses spaces in its Tokenization. As a result, different NLP models' tokenizers can produce various tokens for the same text. Word-based Tokenization uses, for instance, space and punctuation and rule-based Tokenization.
Additionally, this Tokenization provides distinct IDs for words like "boy" and "boys," essential synonyms in the English language. We want our model to understand that similar-sounding phrases exist. We can restrict the number of words added to the vocabulary to address this huge vocabulary issue. For instance, we can limit our vocabulary to only the 5,000 words used the most frequently.
Regarding the misspelled words, there is one more drawback. The model will give the word an OOV token (Out Of Vocabulary) if "knowledge" is misspelled in the corpora as "knowldge."
Character-based Tokenization
Tokenizers that use characters separate the raw text into its characters. This Tokenization is justified because a language has a fixed number of characters but many terms. As a result, the vocabulary is extremely limited.
For instance, there are over 170,000 words in the English language's vocabulary, yet we only utilize 256 distinct characters (letters, numerals, and special characters). So, compared to word-based Tokenization, character-based Tokenization will employ fewer tokens.
Character-based Tokenization has a significant advantage in that there won't be any or very few unfamiliar OOV words. Using the representation for each character, it may then construct a representation of the unknown words (words not encountered during training). Another benefit is that the model can easily correct incorrectly written words rather than being marked as OOV tokens and losing data.
Despite certain drawbacks, character-based Tokenization has mostly resolved word-based Tokenization's challenges. Let's find a solution to the problems character-based Tokenization also has.
Subword-based Tokenization
Subword-based tokenization, which bridges the gap between word- and character-based tokenization, is another widely used tokenization technique. This technique was mainly developed to solve the problems faced by the other two tokenization techniques:
- Huge vocabulary size.
- Numerous OOV tokens.
- The inconsistent meaning of similar phrases.
- Very long sequences.
- Less meaningful individual tokens.
These guidelines guide the subword-based tokenization methods. Avoid breaking up common words into tiny subwords and Divide the uncommon words into more manageable, reasonable subwords.
If we consider the word "tokenization", we can see that "token" is the root word, and "ization" is the second subword that adds additional information to the root word. This subword splitting helps the model to understand the words with similar meanings. Also, this method makes the model understand that the words "tokenization" and modernization" are made up of two different root word and has the same suffix "ization."
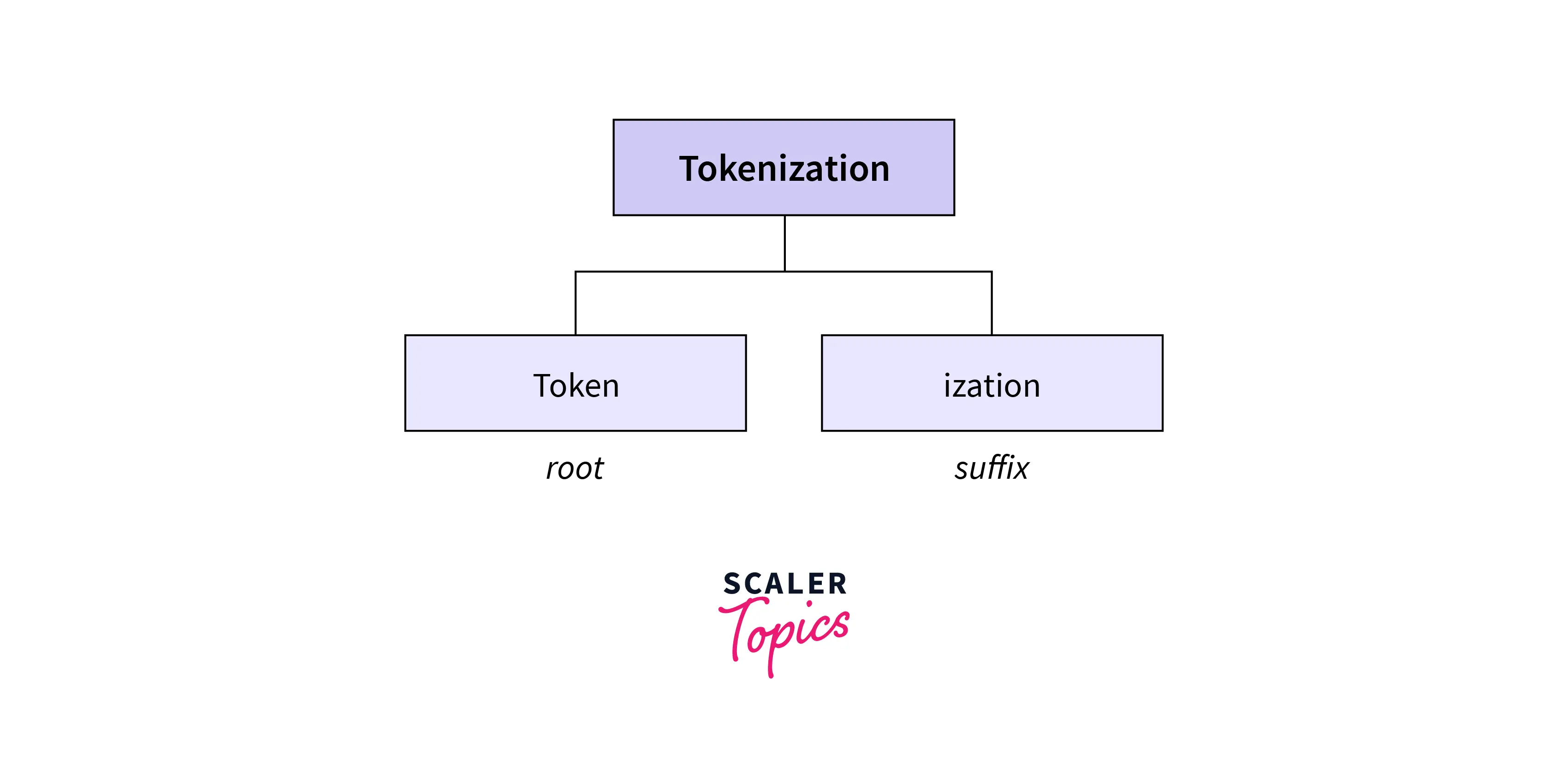
This tokenization algorithm uses special symbols to represent the start and end of the particular token. For example, "modernization" can be split into "modern" and "##ization." Different NLP model uses different symbols. The BERT model used "##" for the second subword of the token.
WordPiece by BERT and DistilBERT, Unigram by XLNet and ALBERT, and Bye-Pair Encoding by GPT-2 and RoBERTa are popular subword-based tokenization methods.
Turn Learning into Career Growth
How to Deal with Rare Words?
When the input raw text goes through the tokenization process, the input is split into tokens by splitting the whitespaces and punctuations. The unique tokens that the NLP operates are called vocabulary.
To search up the embeddings in a mapping table while feeding the input text into a neural network, you typically tokenize the text before feeding it in. we cannot search an input token's ID if it is not a part of the vocabulary. These tokens are referred to as OOV, or Out-Of-Vocabulary, tokens.
Low-frequency terms are more likely to be out of vocabulary because a vocabulary is often a set of words that regularly appear in a corpus. Any tokens outside the set vocabulary used by traditional NLP systems are compressed into the unique token " UNK" (unknown). Let's consider the word balance is OOV in the example above:
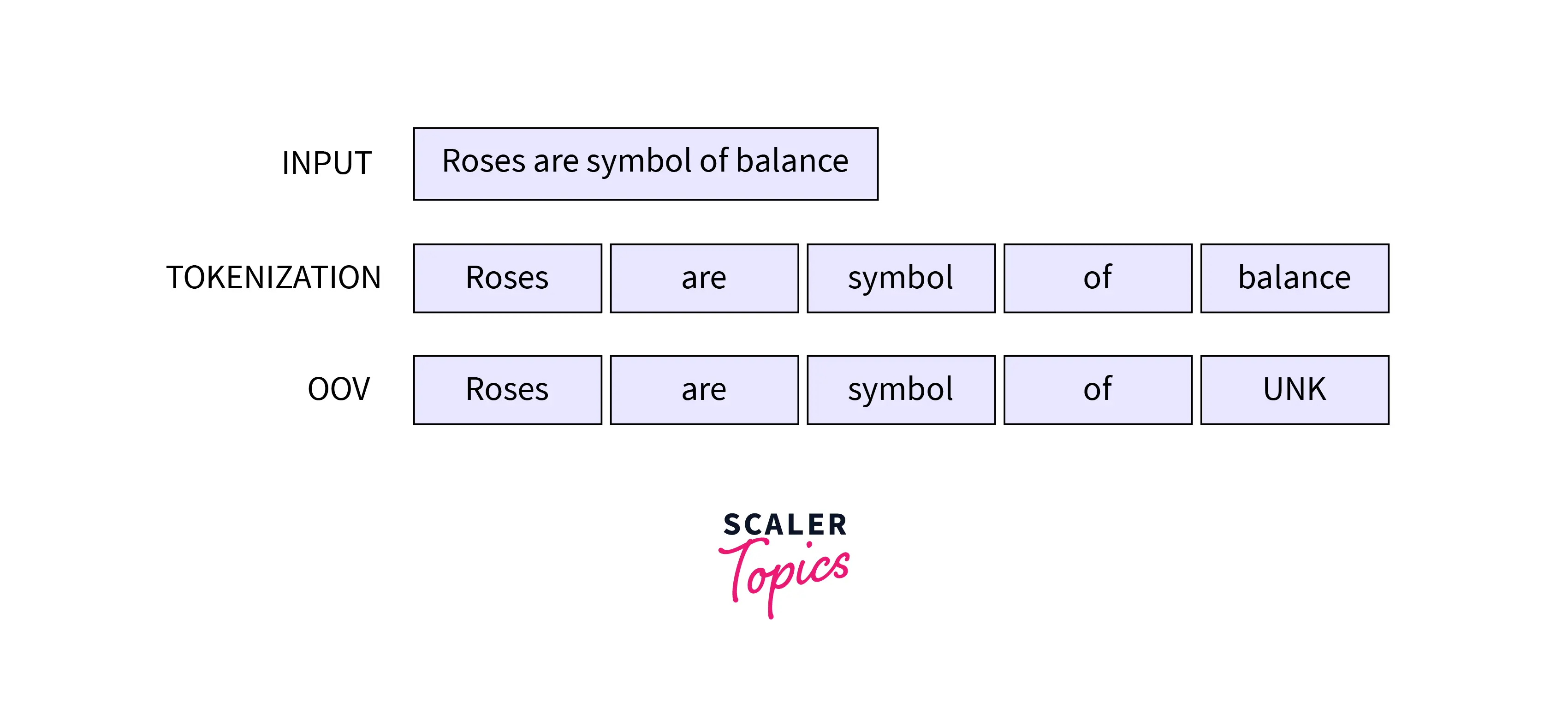
Giving up on tokenizing completely and separating everything into individual characters is one way to fix this. Character-based Tokenization is an exemplary method for translating, for instance, Chinese, a language in which individual characters have some value.
A drawback of this is the computational expense; by breaking things into separate characters, sequences become lengthy, requiring more memory and computing time.
WordPiece - The Original Subword Model
The first and original subword tokenization model proposed was "WordPieceModel". As discussed above, the model keeps the high-frequency words, such as in English "the" and "is" as whole words, while splitting low-frequency and complex words into tokens.
WordPiece begins with a limited vocabulary that includes the model's unique tokens and the basic alphabet. Each word is originally divided by adding that prefix to all the characters inside it since it recognizes subwords by adding a prefix (like ## for BERT). Following that, WordPiece learns merge rules, the same as BPE. The main difference is the method used to choose the pair that the WordPiece model will combine. Rather than picking the most frequent pair.
BPE training example:
The splits done will be:
As a result, the first words in the vocabulary list will be ["l", "r", "f", "##g", "##n", "##s," "##u"]. The most frequent pair is (##u, ##g - 20 occurrences); however, since "##u" has a relatively high individual frequency, its score is not the highest (1 / 36). The best score belongs to the pair ("##g", "##s"), the only one without a "##u," at 1 / 20, and the first merge learnt is ("##g", "##s") -> ("##gs"). In reality, all pairs with a "##u" share that same score (1 / 36).
Since "##u" is now present in every single combination that might exist, each one receives the same grade. Say the first pair is combined in this instance, resulting in the transformation "l", "##u" -> "lu":
Next, ("lu", "##g") and ("lu", "##gs") share the next-best score (1/15 compared to 1/21 for all the other pairs). Therefore the first pair with the highest score is combined. Then Till we have the appropriate vocabulary size, we proceed in this manner. Vocabulary: ["b", "h", "p", "##g", "##n", "##s", "##u", "##gs", "hu", "hug"] **Corpus:** ("hug", 10), ("p" "##u" "##g", 5), ("p" "##u" "##n", 12), ("b" "##u" "##n", 4), ("hu" "##gs", 5)
The WordPiece method first develops a language model on the base vocabulary, chooses the pair with the best probability, incorporates it into the vocabulary, and repeats the process until the required vocabulary size or likelihood threshold is reached.
Byte-pair Encoding (BPE) — the King of Subword Tokenization
Byte pair encoding is a data compression method that substitutes a different byte for the most frequent pair of consecutive bytes in the input data.
Let's say we have data that needs to be encoded, aaabdaaabac (compressed). Since the byte combination aa occurs the most frequently, we will swap it out with X since X does not appear in our data. With X = aa, we now get XabdXabac. Let's swap out ab for Y because that is the frequent byte pair. With X = aa and Y = ab, we now get **XYdXYac**. We won't encode ac because it appears to be only one byte and is the last remaining byte pair. XY can be encoded as Z using recursive byte pair encoding. The new form of our data is ZdZac, where Z = XY, Y = ab, and X = aa. There are no byte pairs that appear more than once. Hence it cannot be compressed any further. After replacing the data in reverse order, we decompress the data.
Consider the paragraph
" FloydHub is the fastest way to build, train and deploy deep learning models. Build deep learning models in the cloud. Train deep learning models. "
At its 1st iteration merging:
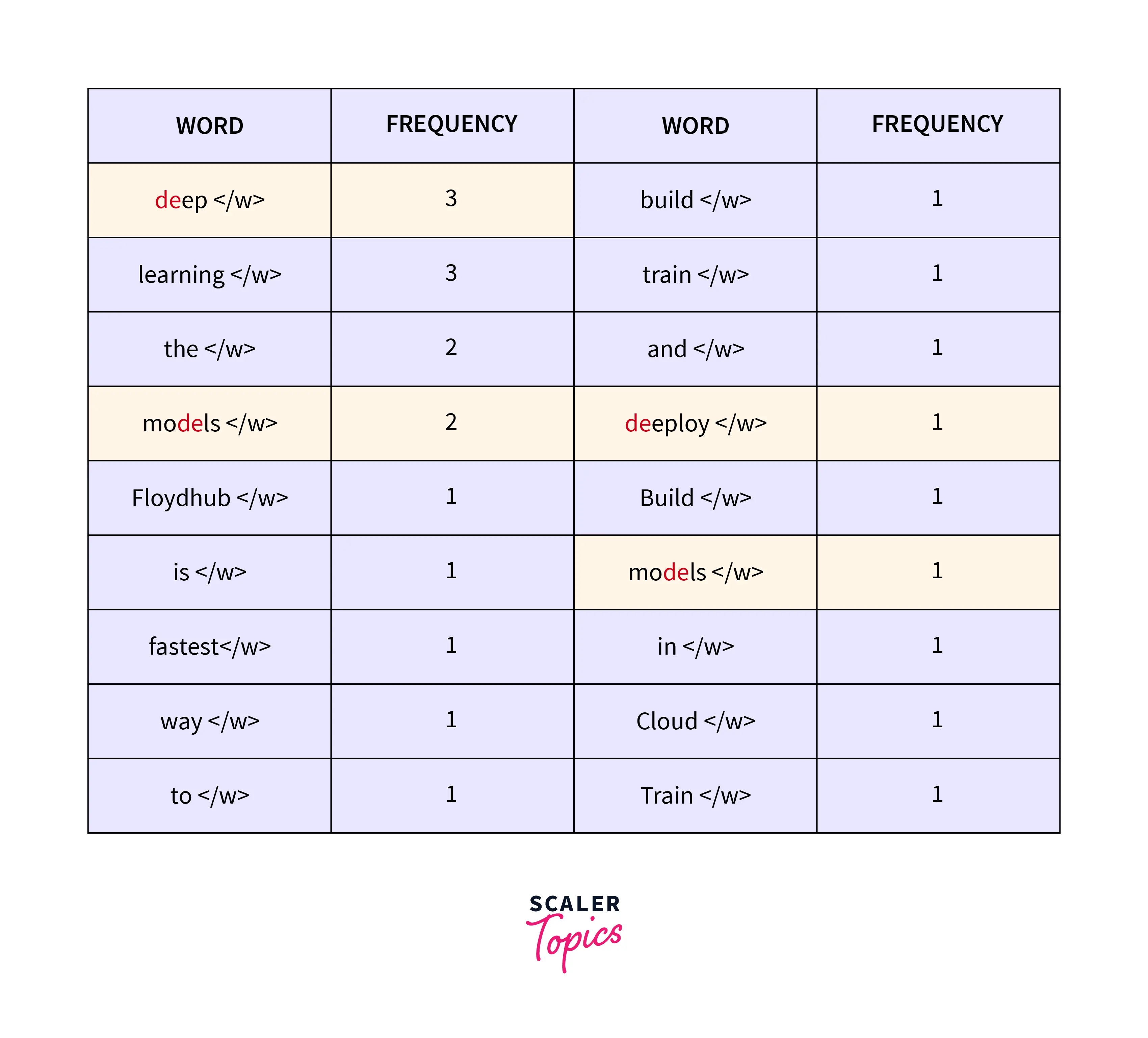
The algorithm can determine where each word ends by adding the **"</w>"** token at the end of each word. This aids the algorithm's search for the character pairings that occur most frequently after going through each character. When we incorporate **"</w>"** in our byte-pairs later, I will go into more depth about this portion.
After that, we will decompose each word into characters and count the instances. The starting tokens will be all the input characters and the "</w>" token. The next stage in the Byte pair encoding process is to find the most common pairing, merge them, and keep doing this until we approach our token limit or iteration limit.
The basic objective of the Byte pair encoding algorithm, i.e., data compression, is made possible by merging, which enables the representation of the corpus with the fewest amount of tokens. Byte pair encoding searches for the most frequently represented byte pairs before merging them. In this case, we treat a character as equivalent to a byte. This is an example in English, although it might look different in other languages. The most frequent bye pairs will now be combined into a single token and added to the list of tokens, and the model will recalculate the frequency of occurrence of each token.
Unigram Language Models and SentencePiece
The term "subword regularisation", a regularisation strategy for machine translation, was initially proposed by Kudo 2018, which describes subword Tokenization with a unigram language model.
The key idea of the unigram language model is that we have more probabilistic ways to tokenize a single text into subwords with the same lexicon. The difference depends on the split position and orders. However, BRE operates by merging the recurring character pairs; it's more complex to sample subwords.
The software application that combines byte-pair encoding and unigram language model segmentation is called SentencePiece. But it is typically employed to train and operate the unigram language model segmentation.
Detokenization, which is a reverse action of Tokenization (moving from "Hello/world/." to "Hello world. "), is given particular attention. This seems simple in languages like English—you concatenate tokens back with whitespace in between. However, you must remember that algorithm should only insert whitespace after punctuation to recreate "Hello world." There are many more factors to consider; how about double quote marks? Ampersands? Etc. These linguistic norms may be exceedingly intricate. SentencePiece, on the other hand, treats whitespaces as a regular alphabet and escapes them, which makes things simpler and makes de-tokenization simple in a language-independent manner.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
BPE-dropout — Regularization Method with BPE
Byte-pair encoding dropout, which significantly alters the BPE algorithm. When BPE combines two successive units, potential merge operations are eliminated (or rejected) with a low probability, such as p = 0.1. This will have the same result as the subword mentioned above, regularisation if done during model training. To obtain deterministic results, you can use the standard BPE approach at the inference time without dropping merges.
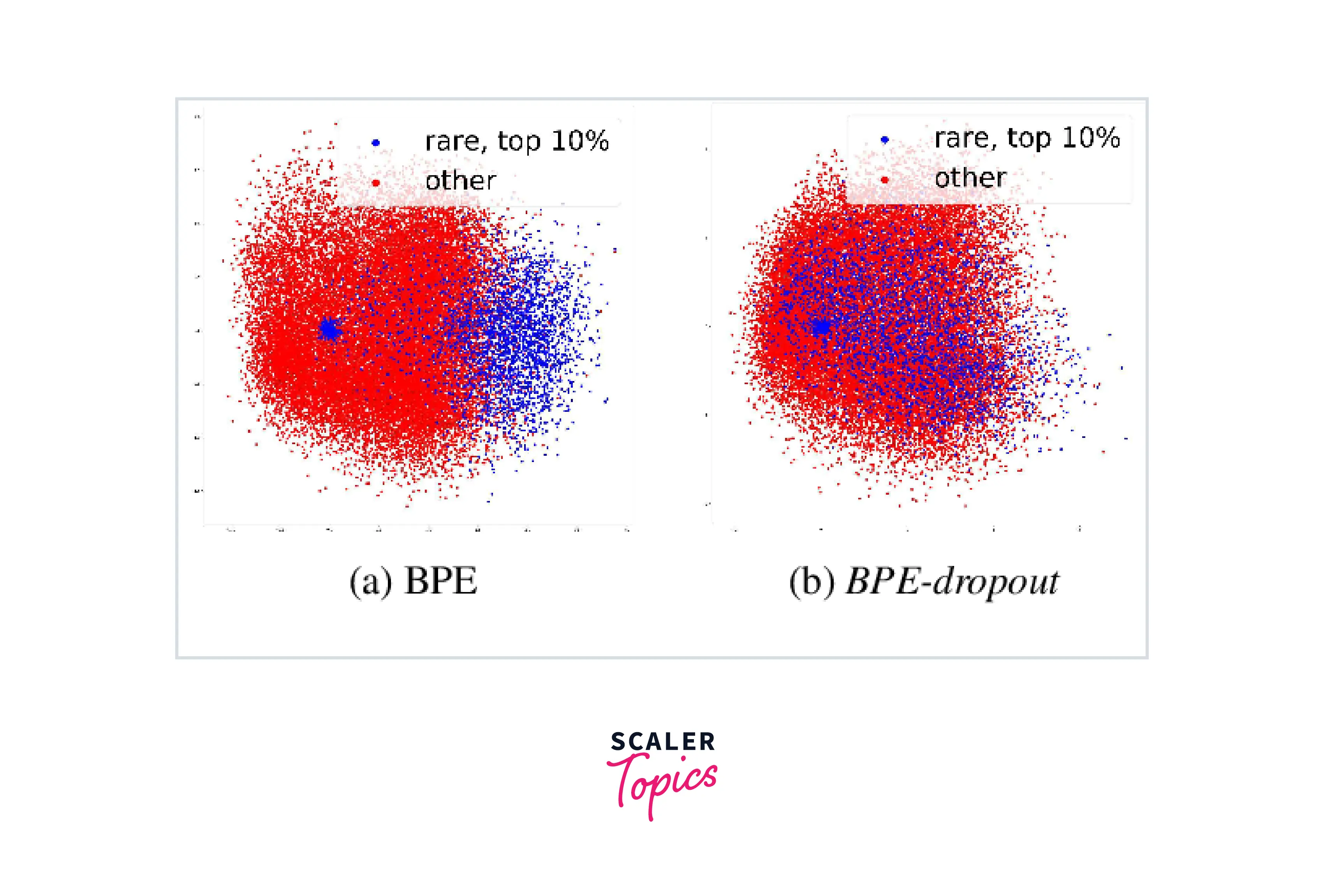
The segmentation technique and vocabulary can be used almost exactly as-is using BPE-dropout, which doesn't need further training or inference steps as the unigram LM tokenization needs. The trials revealed that BPE dropout significantly outperformed the alternative strategy of improving machine translation performance.
Conclusion
- Knowing the fundamentals of subword tokenizers will help you quickly grasp the most recent advancements in Language processing areas.
- Byte-pair encoding examines every feasible merging alternative at each iteration by examining corpus frequency, and it follows the greedy approach to optimize the solution.
- Tokenization and word segmentation are becoming increasingly language-independent as neural models are used more frequently.