tBERT – Topic BERT in NLP
Overview
The data sets that we generally use for training a model is in the form of letter or words, so we use BERT to convert our data into numbers and digits. BERT (Bidirectional Encoder Representations from Transformers) is a bi-directional learning algorithm that was developed by Google in the year 2018. BERT learns to predict the text that might come before or after the other text. The main aim of the development of the BERT was to improve the contextual understanding of the unlabeled text. BERT uses a transformer to learn the contextual relations existing between the provided words or sub-words of a text.
BERT models are pre-trained with large volumes of data that help it to understand the relationship better.
Introduction
Before learning about the BERT topic modeling in NLP, let us first learn some basics about NLP itself.
- NLP stands for Natural Language Processing. In NLP, we analyze and synthesize the input, and the trained NLP model then predicts the necessary output.
- NLP is the backbone of technologies like Artificial Intelligence and Deep Learning.
- In basic terms, we can say that NLP is nothing but the computer program's ability to process and understand the provided human language.
- The NLP process first converts our input text into a series of tokens (called the Doc object) and then performs several operations of the Doc object.
- A typical NLP processing process consists of stages like tokenizer, tagger, lemmatizer, parser, and entity recognizer. In every stage, the input is the Doc object, and the output is the processed Doc.
- Every stage makes some kind of respective change to the Doc object and feeds it to the subsequent stage of the process.
As we all know that we need to train our machine learning models, neural network models, natural language processing models, etc. to predict the accurate output for our input. These models usually take the input in the form of digits or numbers. The data sets that we generally use for training a model is in the form of letter or words, so we use BERT to convert our data into numbers and digits.
Let us now learn about BERT in detail in the next section.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
What is BERT?
Bidirectional Encoder Representations from Transformers or BERT is a bi-directional learning algorithm that was developed by Google in the year 2018. We can also say that BERT is an ML (machine learning) framework that is used in NLP. BERT learns to predict the text that might come before or after the other text. The main aim of the development of the BERT was to improve the contextual understanding of the unlabeled text.
In more theoretical terms, we can visualize the BERT as a deep bidirectional (as it can process or analyze the text from right to left and from left to right) pre-trained machine learning model that delivers state-of-the-art results in NLP. BERT models are pre-trained with large volumes of data that help it to understand the relationship better. Internally, BERT uses the encoder segment and state-of-the-art techniques, making it quite fast and easy to use.
Let us now look at the various areas where BERT is widely used:
- To check whether the review of a particular thing is positive or negative.
- To help the chatbots to answer some of the common questions.
- In predicting the further text during email writing and message writing.
- In summarizing the long legal contracts rapidly.
- In differentiating the words that have multiple meanings. It is done by analyzing the before and after the text.
- In various other language-related tasks.
- It is also used by the Google search engine to auto-complete and predict our search queries.
- Google uses it to analyze and understand human sentiments.
BERT is widely used by applications like Google Docs, Smart Compose, Voice Assistance, Gmail, etc.
Another important technique that involves BERT is the BERT topic modeling in NLP. It uses the concepts of a class-based TF-IDF (term frequency-inverse document frequency) and BERT embeddings to create clusters (dense clusters) that allow easily interpretable topics while keeping the other important words in the description of the topic.
Transformer Architecture
BERT uses a transformer to learn the contextual relations existing between the provided words or sub-words of a text. A transformer has two parts that perform two different mechanisms, i.e. encoding and decoding. The encoding is done by an encoder, and its main work is to read the input text. On the other hand, the decoding part is handled by a decoder whose main work is to decode and predict the output of our task. As we know that a BERT is mainly used to create a language mode and train it for further usage, so the encoder mechanism is mainly necessary.
Please refer to the diagram provided below for more clarity.
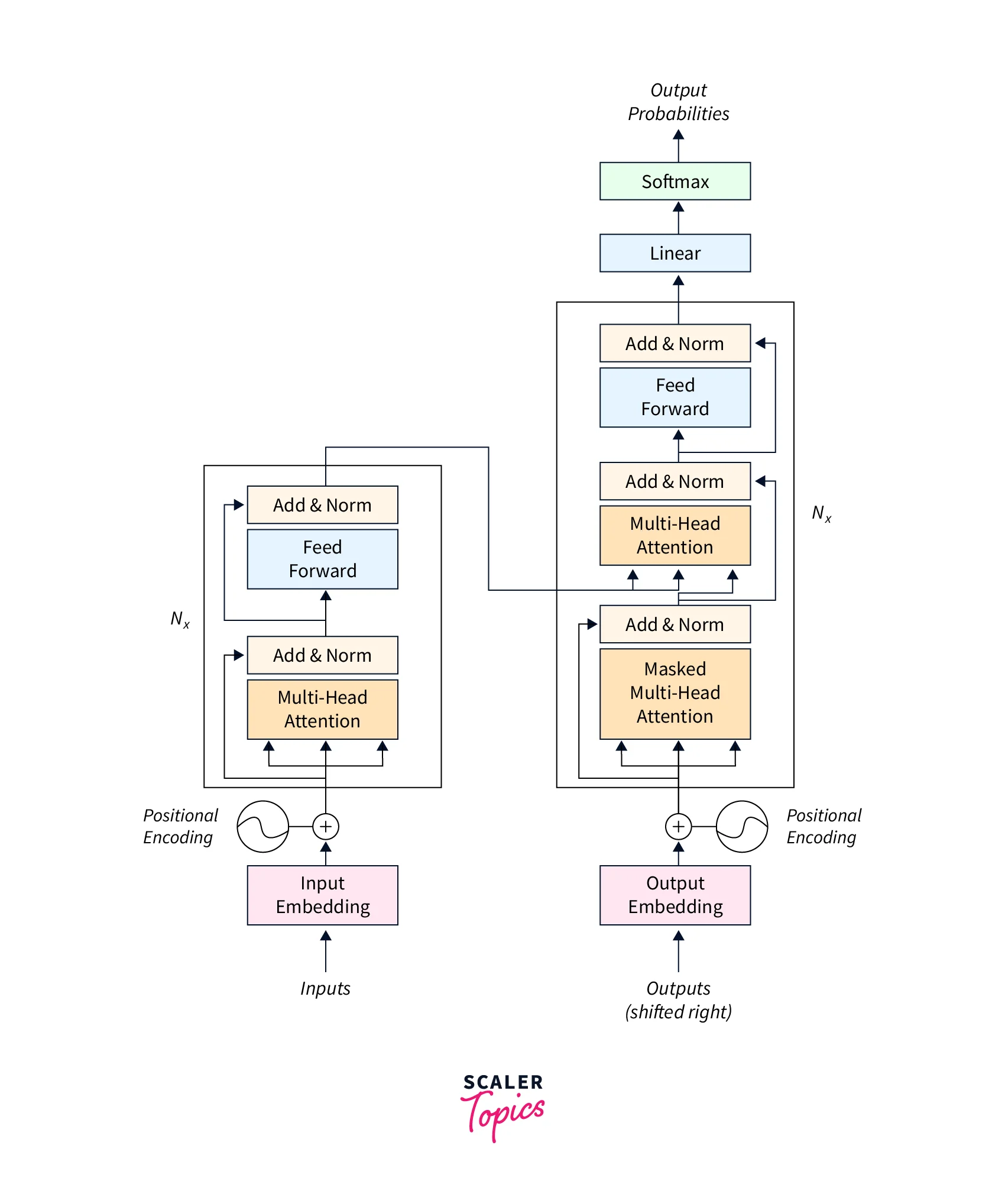
The transformer does not work sequentially. It reads the entire input in one go (entire words at a time), that is the reason why we call the transformers bidirectional (If we say one directional, then it means that the data is being read sequentially either from left to right or from right to left). This great reading quality of the transformers allows it to analyze the data based on its surroundings (previous and next words).
The encoder of the transformer takes the input as a sequence of tokens, the tokens are first embedded into the vectors, and then the vectors are processed in the neural network. Similarly, the output is also a vector sequence denoted by H. Each element of the input vector corresponds to an output vector element.
What is tBERT?
As we know, Semantic similarity detection is a fundamental and one of the most important tasks in natural language understanding. tBERT is a simple architecture formed by combining the topics with the BERT. It gives us better semantic similarity predictions.
Turn Learning into Career Growth
Architecture
In the BERT topic modeling architecture, we use a Topic Model along with the normal BERT for data processing and output prediction. To understand the architecture, let us suppose that we have two sentences, S1 having the length N, and another sentence S2 having the length M. We have a vector C that has come from the final layer of BERT (as output which corresponds to the CLS token present in the input). So, now the sentence pair can be represented as:
Here d represents the hidden internal size of the BERT. It comes out to be 768 for the BERT(base).
Please refer to the diagram provided below for more clarity.
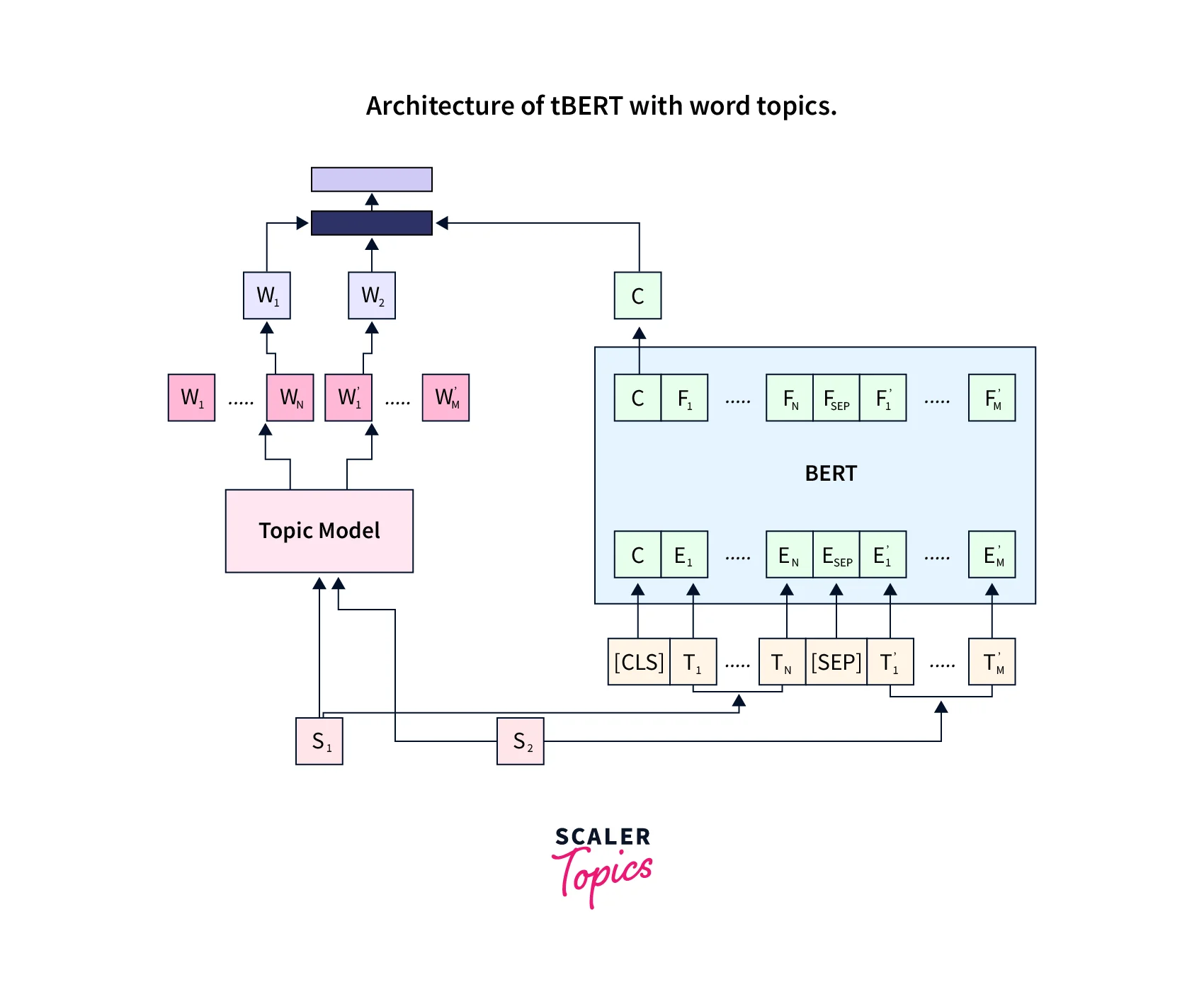
Choice of Topic Model
Let us now learn about the topic model and its associated terms.
Topic number and alpha value:
The topic number and the alpha value are very important parameters involved in BERT topic modeling, and data set dependents. We change the value of alpha according to the topic number to get the desired output. The topic number parameter is used to identify the topic models for each of the datasets without expensive hyperparameter tuning on the full tBERT model.
Topic model and topic type:
The topic model and the topic type are also the modeling concepts involved in BERT topic modeling and data set dependents. One of the most widely used topic models is LDA, but the LDA is not suitable for short texts hence we can also use the GSDMM model for such cases. The selection of topic type is also important as we can evaluate different combinations of tBERT with LDA vs GSDMM and word vs document topics on the development partition of the datasets.
Baselines
Let us now learn about the topic model and its associated terms.
Topic Baselines:
On the training portion of the data set, we train the topic model (either LDA or GSDMM). After the training of the topic model, we calculate the JSD or Jensen Shannon Divergence between two sentences' topic distributions. If the JSD is greater than the threshold, then the model predicts a negative label, on the other hand, if the JSD is smaller than the threshold, then the model predicts a positive label. So, we tune the threshold value according to the number of topics and alpha value.
Evaluating the Model
The evaluation of a model is based on various evaluation techniques like F1 score, precision, recall, etc. The F1 score is used to evaluate the reliability and accuracy of the model. A recent study has shown that the early stopping and random seeds can have a considerable impact on the performance of fine-tuned BERT models. So, we generally use the early stopping during fine-tuning and report average model performance across two seeds for the BERT and tBERT models.
To learn more about BERT topic modeling, please refer to the official code repository here.
Conclusion
- The data sets that we generally use for training a model is in the form of letter or words, so we use BERT to convert our data into numbers and digits.
- BERT (Bidirectional Encoder Representations from Transformers) is a bi-directional learning algorithm that was developed by Google in the year 2018.
- BERT learns to predict the text that might come before or after the other text. The main aim of the development of the BERT was to improve the contextual understanding of the unlabeled text.
- BERT uses a transformer to learn the contextual relations existing between the provided words or sub-words of a text. BERT models are pre-trained with large volumes of data that help it to understand the relationship better.
- We can visualize the BERT as a deep bidirectional (as it can process or analyze the text from right to left and from left to right) pre-trained machine learning model that delivers state-of-the-art results in NLP.
- It uses the concepts of class-based TF-IDF and BERT embeddings to create clusters that allow easily interpretable topics while keeping the other important words in the description of the topic.
- tBERT is a simple architecture formed by combining the topics with the BERT. It gives us better semantic similarity predictions.