What is Decoder in Transformers
Overview
A transformer decoder is a neural network architecture used in natural language processing tasks such as machine translation and text generation. It combines with an encoder to process input text and generate output text. It has multiple layers of self-attention and feed-forward neural networks. It is trained using a combination of supervised and unsupervised learning techniques. It is known for its accuracy and natural-sounding output.
Introduction
The transformer decoder is a crucial component of the Transformer architecture, which has revolutionized the field of natural language processing (NLP) in recent years. It is known for its state-of-the-art performance on various tasks, including machine translation, language modeling, and summarization. The transformer decoder works in conjunction with the encoder, which processes the input sequence and generates a sequence of contextualized representations known as "hidden states." These hidden states capture the meaning and context of the input sequence and are passed on to the transformer decoder.
The transformer decoder block comprises multiple layers of self-attention and feed-forward neural networks, which work together to process the input and generate the output. The transformer decoder then uses these hidden states and the previously generated output tokens to predict the next output token and generate the final output sequence. This encoder-decoder architecture is necessary for NLP tasks as it allows for more accurate and natural-sounding output. In this article, we will delve into the inner workings of the transformer decoder and understand its role and importance in Transformer architecture.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
What is Encoder-Decoder Architecture?
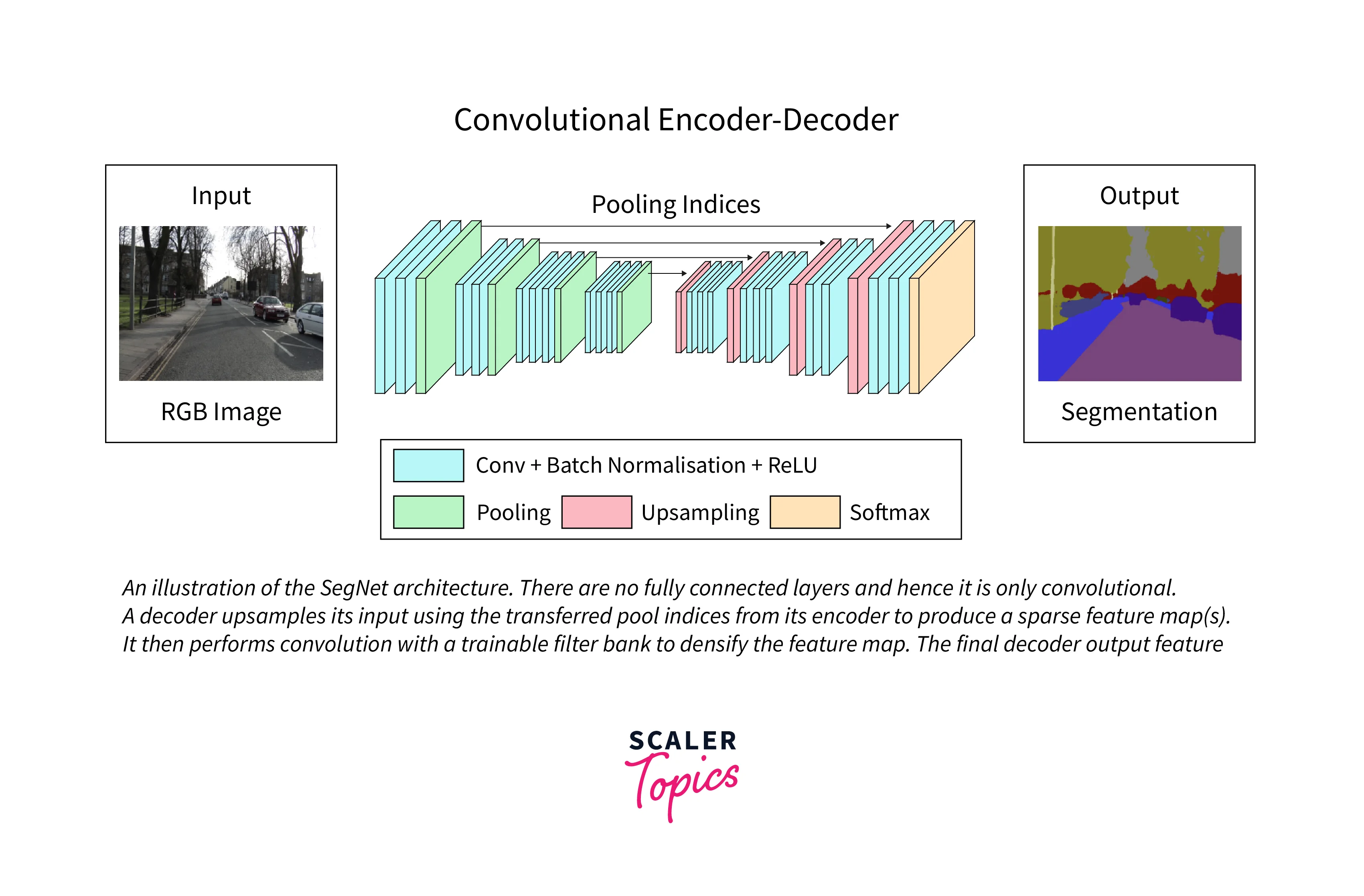
Encoder-Decoder architecture is a popular neural network architecture used in various natural language processing and computer vision tasks The architecture comprises two main parts: the encoder and the decoder.
The encoder is responsible for processing the input and creating a compact representation called the "encoding". The encoder takes the input, such as a sentence in one language or an image, and processes it through multiple layers of neural networks. The final output of the encoder is a fixed-length vector, called the "encoding", that contains a condensed representation of the input. This encoding is typically a lower-dimensional representation of the input, which captures the most important information from the input.
The decoder then takes this encoding and generates the output. The decoder processes the encoding through multiple layers of neural networks and generates the final output, such as a translated sentence or a caption for an image. The decoder also uses an attention mechanism, which allows the model to focus on specific parts of the encoding when generating the output.
Encoder-Decoder architecture can be implemented using various types of neural networks. For example, the encoder and decoder can be implemented using recurrent neural networks (RNNs) or convolutional neural networks (CNNs). RNNs are good at processing input sequences, such as sentences, while CNNs are good at processing images.
Encoder-Decoder architecture is useful in many natural language processing and computer vision tasks because it allows the modeling of complex input-output relationships. For example, in machine translation, the input is a sentence in one language, and the output is a sentence in another language. The model must learn the complex relationship between the two languages. Similarly, in image captioning, the input is an image, and the output is a sentence describing the image. The model must learn the relationship between the visual information in the image and the words in the sentence.
Encoder-Decoder architecture is effective in many natural language processing and computer vision tasks, such as machine translation, image captioning, and text summarization.
Need for a Decoder
- The transformer decoder is a crucial component in the transformer architecture for generating the final output sequence.
- The encoder processes the input sequence and generates hidden states that capture the contextual information.
- The hidden states alone are not enough to generate the output sequence.
- The transformer decoder uses the hidden states as a starting point and generates the output sequence one token at a time using the previously generated output as context.
- The output sequence depends on the specific task, such as translation, language modeling, or text summarization.
- The transformer decoder is crucial in generating the final output sequence.
- Without the transformer decoder, there would be no way to generate the output sequence.
- Without an encoder, the transformer decoder would miss important contextual information, resulting in lower-quality output.
- Combining an encoder and transformer decoder is key to the effectiveness of the transformer architecture in NLP tasks.
Decoder in Transformers
As covered in the previous sections, The decoder is a crucial component of the Transformer architecture, responsible for generating the output sequence in Natural Language Processing (NLP) tasks. It consists of multiple layers, each of which is made up of a multi-head self-attention layer and a feedforward neural network.
The decoder takes as input the hidden states generated by the encoder and the previously generated output tokens and uses them to predict the next output token. At each step, the decoder attends to different parts of the input sequence using its attention mechanism, allowing it to capture complex relationships between the input and output sequences.
Overall, the decoder is a key component of the Transformer architecture, responsible for generating the output sequence in NLP tasks using the contextual information provided by the encoder's hidden states and the previously generated output tokens. Its attention mechanism lets it capture complex relationships between the input and output sequences, enabling it to generate high-quality output.
Examples Where the Decoder Plays a Vital Role
Some examples of decoders in the Transformer architecture include:
- The transformer decoder is used in machine translation models such as Google Translate to generate the translated output sequence.
- The transformer decoder generates the next word in the sequence in language modeling models such as GPT-3.
- The transformer decoder is also used in summarization models, such as the T5 model, to generate summaries of long texts.
- In image captioning models, the transformer decoder generates the caption output sequence.
- Speech recognition models also use the transformer decoder to transcribe spoken words into written text and generate the transcribed output sequence.
There are a lot of real-world use cases, and the tasks mentioned here are just a few of those.
Turn Learning into Career Growth
Internal Workings of a Decoder Block
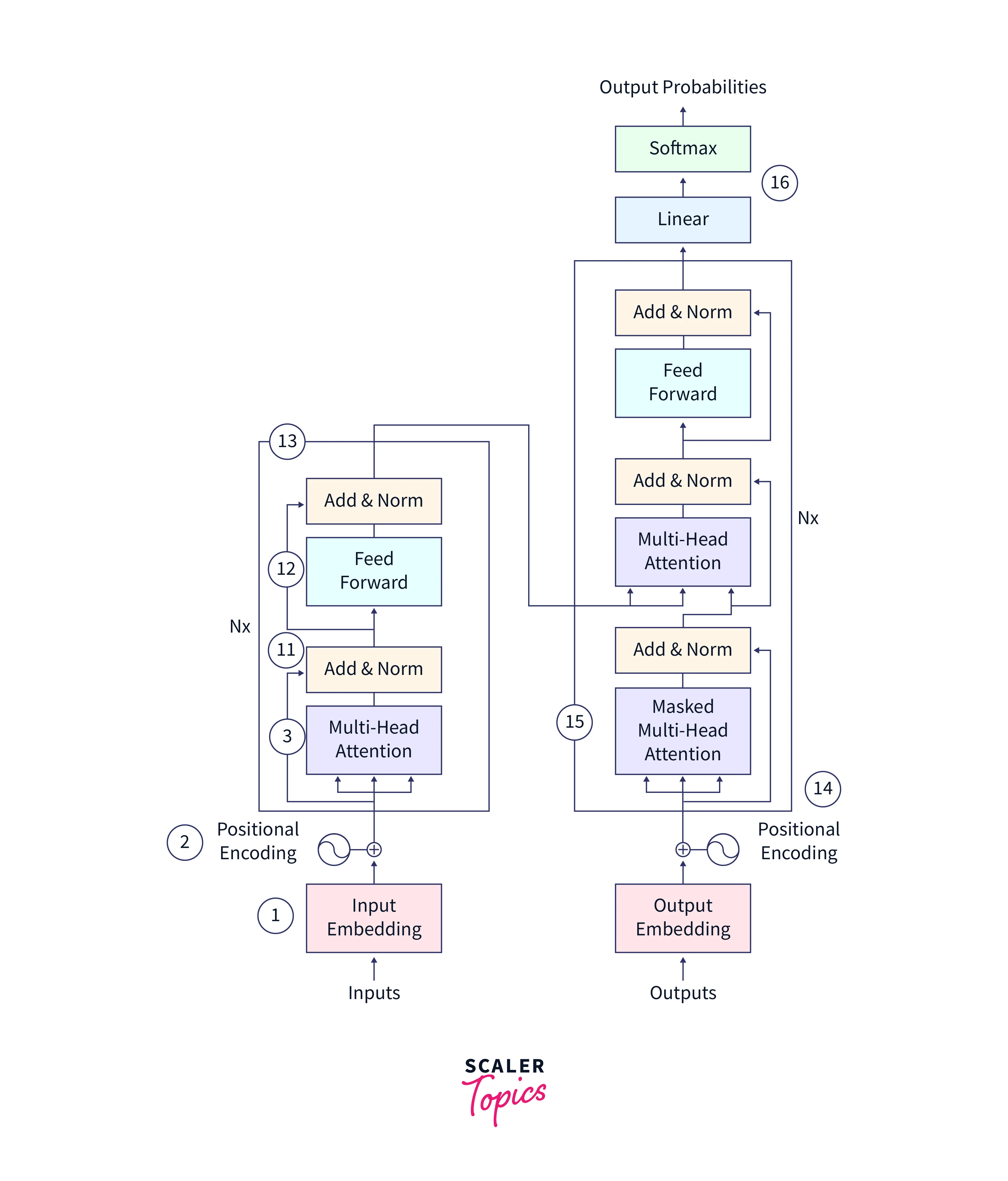
Please note that the steps/annotations in the image above will be explained according to their assigned numerical identifier.
Only some parts of the architecture are explained because we only focus on the decoder part of the Transformer in this article.
The decoder in the Transformer architecture plays a crucial role in generating the output sequence for natural language processing tasks. It takes the hidden states generated by the encoder and the previously generated output tokens as input and uses them to predict the next output token.
(14) The decoder has a masked multi-head attention layer that enables it to focus on various portions of the input sequence as it generates the output at each step. This attention mechanism is essential for capturing complex relationships between the input and output sequences and generating high-quality output.
Multi-Headed Attention Architecture
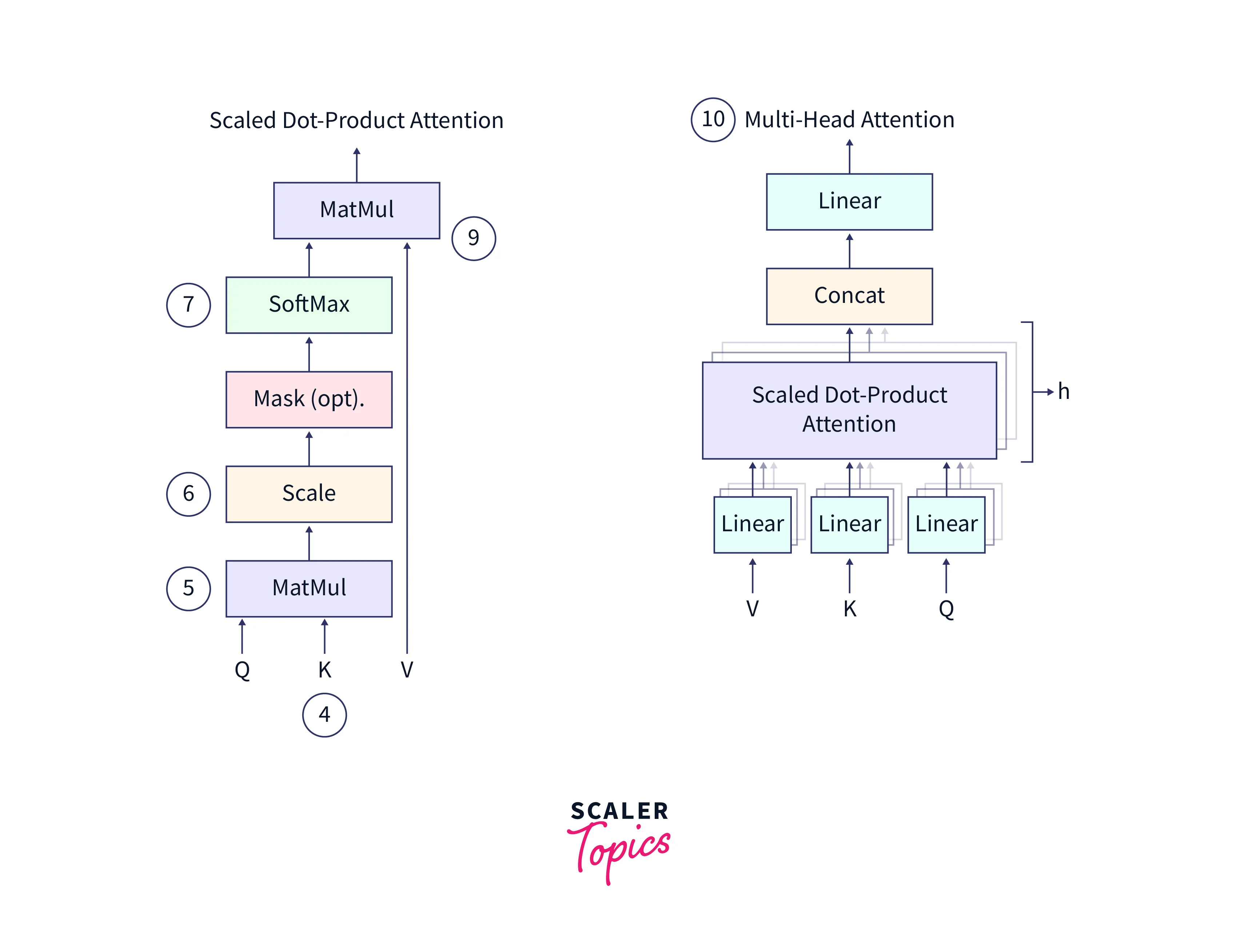
The diagrams above illustrate the Multi-Headed Attention mechanism in detail.
(4) The multi-headed attention mechanism in the Transformer consists of three learnable vectors: the query vector, the key vector, and the value vector. These vectors are used to calculate the attention weights for each input element. The motivation for this approach reportedly comes from information retrieval systems, where a query is compared to a key, and a value is returned.
(5) To calculate the attention weights, the query, and key vectors are multiplied through a dot product to produce a scoring matrix. This matrix represents the importance of each word in the input sequence concerning all other words. Higher scores indicate that a word should receive more attention, while lower scores indicate that a word should receive less attention.
(6) The score matrix is then scaled down according to the dimensions of the query and key vectors to ensure more stable gradients. This is necessary because the multiplication of the score matrix can have exploding effects, which can hinder the model's ability to learn.
(7) After the score matrix has been calculated, it is transformed into a matrix of probabilities using the softmax function** The purpose of the softmax function is to "squash" the attention scores into a probability distribution, which means that the scores are transformed into values between 0 and 1, with higher scores being intensified and lower scores being depressed. This ensures the model is confident in its attention weights and can focus on the most important input elements.
(8) The matrix of probabilities is then multiplied element-wise with the value vector, which amplifies the importance of input elements with higher probabilities and downplays the importance of input elements with lower probabilities.
(9) The concatenated output of the query, key, and value vectors is then passed through a linear layer for further processing. The linear layer combines the input vectors through a linear transformation, which allows the model to learn more complex relationships between the input elements.
The type of attention discussed above is called Self-Attention. It allows a model to attend to different parts of an input sequence and consider their relationships when processing the data.
(10) The self-attention process is repeated for each word in the input sequence. Since the attention weights for each word do not depend on the other words in the sequence, multiple copies of the self-attention module can be used to process the input simultaneously, making the attention mechanism multi-headed. This allows the model to attend to different input parts and capture more complex dependencies between the input elements.
Masking in Multi-Headed Attention
This section explains the annotated part (15) in the image above.
The decoder's masked multi-head attention layer enables it to focus on various portions of the input sequence as it generates the output at each step. However, ensuring that the decoder does not have access to information from future tokens in the input sequence is important. This could lead to "cheating" and produce lower-quality output.
To prevent this, the decoder uses a masked attention mechanism. This is done by masking the entries of words that come later in the sequence in the score matrix. The score matrix is used to calculate the attention weights, which determine the importance of each input token in generating the output.
To mask the entries of future words in the sequence, the current and previous words are added with one, and the future word scores are added with -in. This ensures that the future words in the sequence get drowned out to 0when performingsoftmaxto obtain the probabilities while the rest are retained. Softmax is used tonormalize` the attention weights and obtain a probability distribution over the input tokens. By masking the entries of future words in the score matrix, the decoder is prevented from using information from future tokens in the input sequence.
Final parts of a decoder
(16) Beside the masked multi-head attention layer, the decoder block also includes residual connections, which help improve the flow of gradients and the overall performance of the decoder.
In the Transformer architecture, the output from the decoder block is processed in the following way:
- Linear layer: The output from the decoder block is passed through a linear layer, which applies a linear transformation to the output. The linear layer is a fully-connected neural network layer that applies a linear transformation to the input using a weight matrix and bias vector.
- Softmax function: After passing through the linear layer, the output is passed through the softmax function. The softmax function is a common activation function used in machine learning that normalizes the output of the linear layer into a probability distribution. It ensures that the output values sum up to 1, and each value represents the probability of a particular output class.
- Output probabilities: After passing through the softmax function, the output is a probability distribution over the possible output classes. For example, in a machine translation task, the output classes could be the words in the target language. In this case, the output probabilities would represent the probability of each word being the next word in the output sequence.
- Output prediction: Considering the example of the next word in a sentence prediction, the output probabilities are used to predict the next output token by selecting the class with the highest probability. This predicted output token is then fed back into the decoder as input, along with the previously generated output tokens and the encoder's hidden states. The process is repeated until the desired output sequence is generated.
Conclusion
- Transformer decoder is crucial in generating high-quality output for NLP tasks.
- We learned the decoder's role, the need for it, and its architecture.
- We delved into the internals of the decoder block, specifically its attention layers.
- Some examples of tasks that use the Transformer architecture and its decoder component include machine translation, language modeling, summarization, image captioning, and speech recognition.
- You can learn more about the Transformer architecture and its various components, implement a Transformer model and experiment with different NLP tasks.