What are Encoder in Transformers
Overview:
The transformer encoder architecture has been the basis for many state-of-the-art models in natural language processing tasks such as language translation and text summarization. Encoders in Transformers are neural network layers that process the input sequence and produce a continuous representation, or embedding, of the input. The decoder then uses these embeddings to generate the output sequence. The encoder typically consists of multiple self-attention and feed-forward layers, allowing the model to process and understand the input sequence effectively.
Introduction
The transformer encoder-decoder architecture is a neural network structure for various natural language processing tasks such as language translation and text summarization. The encoder processes the input sequence and produces a continuous representation, or embedding, of the input. At the same time, the decoder generates the output sequence based on the embeddings produced by the encoder. Both encoder and decoder consist of multiple layers with self-attention and feed-forward mechanism. This architecture was introduced in the 2017 "Attention Is All You Need" paper. It has been the basis for many state-of-the-art models in natural language processing due to its ability to effectively process and understand input sequences and generate correct output sequences.
What are Encoders in Transformers?
Encoders in Transformers, also known as the transformer encoder, are a key component of the transformer encoder-decoder architecture. They are responsible for analyzing and representing the input sequence in a way the model can understand. The encoder processes the input sequence and produces a continuous representation, or embedding, of the input. These embeddings are then passed to the decoder to generate the output sequence.
The transformer encoder architecture typically consists of multiple layers, each of which includes a self-attention mechanism and a feed-forward neural network. The self-attention mechanism allows the model to weigh the importance of different input sequence parts by calculating the embeddings' dot product. This mechanism is also known as multi-head attention.
The feed-forward network allows the model to extract higher-level features from the input. This network usually comprises two linear layers with a ReLU activation function in between. The feed-forward network allows the model to extract deeper meaning from the input data and more compactly and usefully represent the input.
The transformer encoder is a crucial part of the transformer encoder-decoder architecture, which is widely used for natural language processing tasks such as language translation, text summarization, language modeling and more. With the ability to effectively process and understand input sequences and generate correct output sequences, transformer encoder-decoder architecture has become one of the most popular architectures in natural language processing.
Encoder-Decoder Architecture
The transformer encoder-decoder architecture is a neural network structure that uses the transformer encoder-decoder modules to perform various natural language processing tasks. The encoder processes the input sequence and produces a continuous representation, or embedding, of the input, which is then passed to the decoder to generate the output sequence.
The transformer encoder comprises multiple self-attention and feed-forward layers, allowing the model to process and understand the input sequence effectively. The decoder also typically consists of multiple layers, including a self-attention mechanism and a feed-forward network.` The decoder uses the embeddings produced by the encoder and its internal states to generate the output sequence.
The decoder also typically consists of `multiple neural network layers that generate the output data based on the context provided by the encoder. The decoder may also include self-attention layers, which allow it to consider the context and dependencies between different parts of the output when generating the data.
The transformer encoder-decoder architecture is widely used in NLP tasks because it allows the model to efficiently process long data sequences and capture relationships between input and output parts. It is particularly well-suited for tasks such as machine translation, where the input and output sequences can be very long and complex.
One limitation of the transformer encoder-decoder architecture is that it may need help to capture `long-range dependencies in the input data, particularly when the input sequence is very long. Researchers have developed variants of the encoder-decoder architecture to address this issue, such as the transformer architecture, which uses self-attention mechanisms to capture long-range dependencies in the input data.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Need of an Encoder?
- The Transformer architecture is a neural network model that uses an encoder to process and encode input data.
- The encoder plays several important roles, such as:
- Extracting useful features and patterns from complex and unstructured input data is crucial for understanding the input and making predictions.
- `Capturing relationships between different parts of the input through self-attention mechanisms. This allows the model to consider the context and dependencies between different parts of the input when making predictions, which is important for tasks such as machine translation, where the meaning of a word can depend on the words around it.
- The encoder also plays a crucial role in the encoder-decoder architecture, a common structure used in natural languages processing tasks such as machine translation and language generation.
- In this architecture, the encoder processes and encodes the input data, and the decoder generates the output data based on the encoded representation.
- The encoded representation provided by the encoder serves as the “context” for the decoder, which helps it generate more accurate and coherent output by capturing the essence of the input.
- Overall, the encoder is a vital component of the Transformer architecture. It is instrumental in the model’s ability to process and understand complex input data by providing a compact representation that captures the essence of the input.
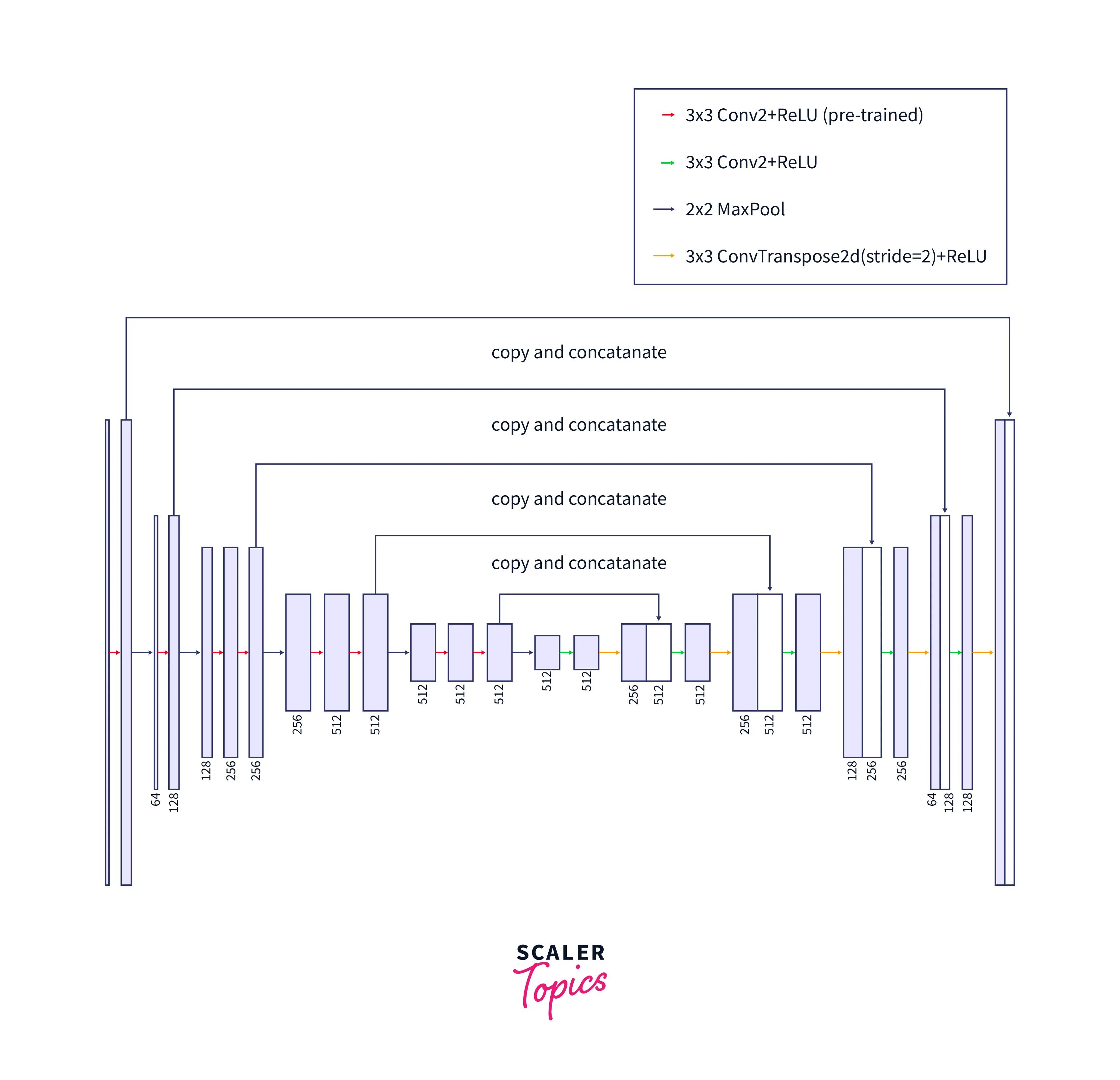
Encoder Block Internals
How do they work?
The encoder block in a Transformer architecture consists of the following components:
- Multi-head self-attention mechanism: The input sequence is first transformed into query, key, and value vectors. These vectors are then used to compute a weighted sum of the values, where the weights are determined by the dot-product of the query and key vectors and scaled by the square root of the dimension. This allows the model to attend to different parts of the input sequence and compute a representation that considers the relationships between elements in the sequence.
- Position-wise fully connected feed-forward network: The output of the multi-head self-attention is then processed by a fully connected feed-forward network with a ReLU activation function. This network helps to capture more complex relationships between elements in the input sequence and produce a new representation.
- Layer normalization: The output of the feed-forward network is then normalized to stabilize the training process. This normalization helps to ensure that the network's activations do not become too large or too small, which can cause problems during training.
- Dropout: Finally, dropout is applied to the output to prevent overfitting. This regularization technique randomly drops out some activations during training, which helps to prevent the model from becoming too confident in its predictions and overfitting the training data.
The encoder block takes in a sequence of vectors, processes them through the multi-head self-attention and position-wise feed-forward network, and outputs a new sequence of vectors. This process is repeated multiple times to produce a high-level representation of the input sequence for subsequent tasks such as classification or machine translation.
How does a Transformer Encoder work?
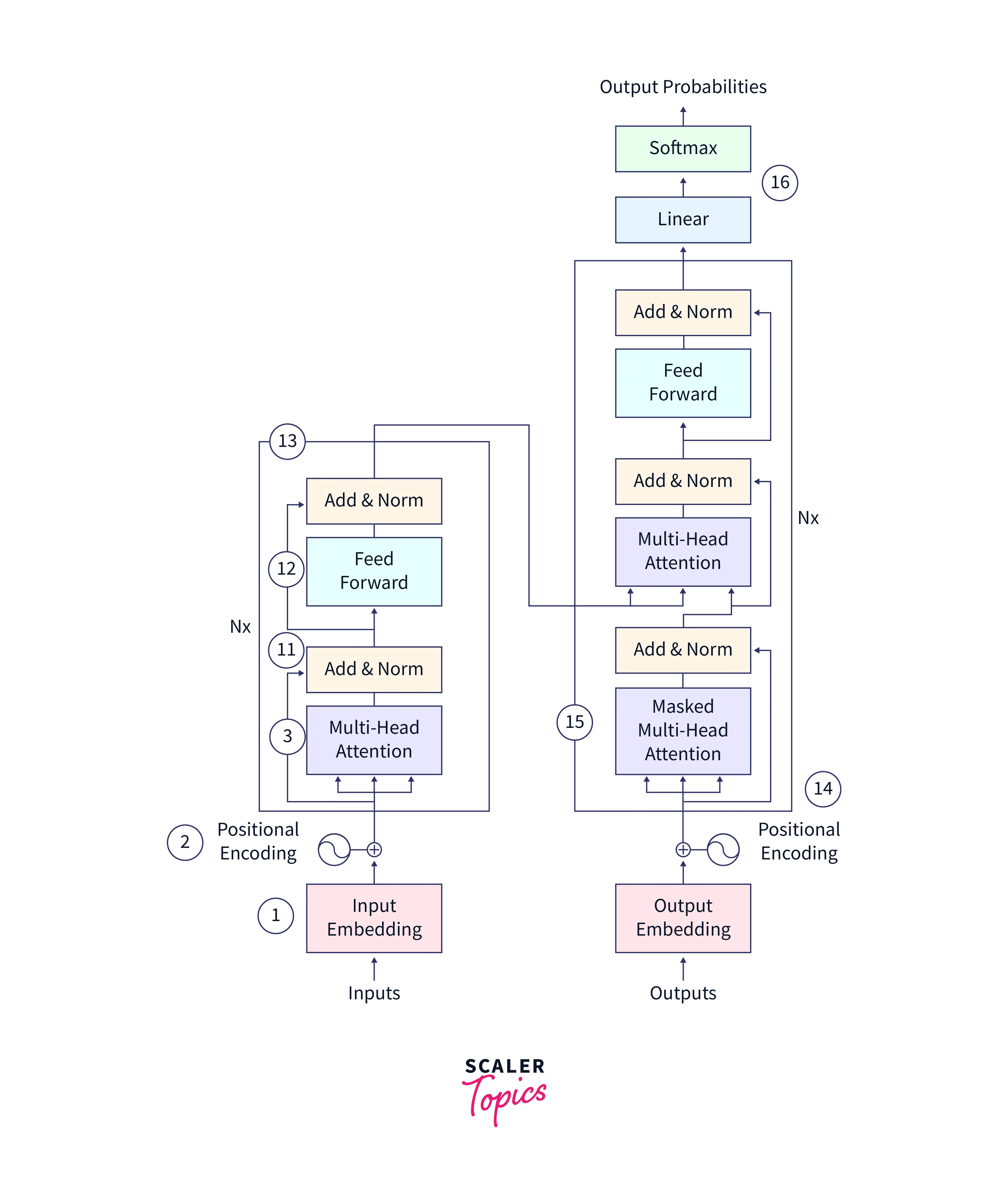
Please note that the steps in the image above will be explained in the same order as they appear. Some parts of the image have been cropped and re-used for a clearer focus on specific steps
For this article, only steps 1 to 13 are relevant, as we only focus on the transformer's encoder part.
(1) In the first step of the Transformer process, the input data is transformed into a vector representation using an embedding layer. This layer maps each word in the input to a fixed-length vector, which helps the model capture the meaning and context of the words. The embedding layer is typically initialized with the pre-trained word embeddings such as word2vec or GloVe, which are learned from large amounts of text data.
(2) After the input data has been embedded, it is augmented with positional encoding. The positional encoding is a series of sinusoidal functions that encode the relative position of each word in the input sequence, and it is added to the input embeddings element-wise. This is necessary because the transformer has no inherent understanding of the order of the input sequence, and the position of each word in the sequence can affect its meaning.
(3) The next step in the Transformer process is the multi-headed attention stage. This is where the transformer differs significantly from other models, using self-attention mechanisms to capture dependencies between different parts of the input data. The multi-headed attention mechanism comprises multiple self-attention layers, which allow the model to attend to different parts of the input and consider their relationships when making predictions. The self-attention layers use dot-product attention, allowing the model to weigh the importance of different input elements based on their relationships. This enables the transformer to capture the input data's long-range dependencies and contextual relationships.
Examples of Encoders
An encoder is a component of a neural network architecture that processes and compresses input data, typically to generate a compact representation that can be used for tasks such as compression, reconstruction, or classification. Some examples of encoder architectures include:
-
Convolutional neural networks (CNNs): These are commonly used in image and video processing tasks and involve filters that scan over the input data to learn features and compress the information into a lower-dimensional representation.
-
Recurrent neural networks (RNNs): These are commonly used innatural language processing tasks and involve feedback connections between hidden units that allow the network to process sequentialinput data` and maintain a memory of previous inputs.
-
Autoencoder: These are neural networks trained to reconstruct the input data from a compact internal representation, typically through an encoder-decoder architecture.
-
Transformer: These are neural networks trained to process sequential input data, such as natural language text, using a self-attention mechanism that allows the network to weigh the importance of different input parts in generating the internal representation.
Turn Learning into Career Growth
Self-Attention Mechanism
The type of attention that was discussed above is called Self-Attention. It allows a model to attend to different parts of an input sequence and consider their relationships when processing the data.
(10) The self-attention process is repeated for each word in the input sequence. Since the attention weights for each word do not depend on the other words in the sequence, multiple copies of the self-attention module can be used to process the input simultaneously, making the attention mechanism multi-headed. This allows the model to attend to different input parts and capture more complex dependencies between the input elements.
Understanding the Self-Attention Mechanism
Self-Attention is used in the encoder stage of the Transformer architecture to capture relationships between different parts of the input sequence The self-attention layer in the encoder is composed of three learnable vectors: the query vector, the key vector, and the value vector.
The query vector is used to "query" the key vector to obtain a score, which represents how much a word in the input sequence should attend to every other word. The key vector compares the query vector to obtain the score. The value vector is used to amplify the importance of higher-scoring words and suppress the importance of lower-scoring words.
The self-attention layer in the encoder allows the model to consider the context and dependencies between different parts of the input when encoding the data. This enables the transformer to capture long-range dependencies in the input data and perform well on tasks such as machine translation and language generation.
Visualizing Self-Attention
Consider the following sentence as input for a machine translation model:
"The driver could not drive the car fast enough because it had a problem."
In this sentence, it can be unclear to a machine whether the pronoun "it" refers to the driver or the car. Similarly, it may need to be clarified to the machine which entity had the problem mentioned in the sentence. These ambiguities can be difficult for a machine to resolve without the ability to learn and understand the context of the sentence. On the other hand, it is typically easier for humans to disambiguate the meaning of words and determine the sentence's overall meaning.
In machine translation, self-attention allows the model to pay more attention to certain words in the source language sentence, such as "it" in the example provided, and consider their relationships with other words in the sentence. This helps the model to understand the context and determine the meaning of words that might be ambiguous or open to multiple interpretations, such as "it" in the example.
Attention in a machine learning model can be visualized by plotting the attention weights or attention scores for each input element. These weights or scores represent the importance of each element in the input sequence, as determined by the model's attention mechanism.
One way to visualize attention is to create a heatmap, where the attention weights are represented as colors on a scale from low to high. This allows the user to see which words the model is paying more attention to when making its predictions. For example, in a machine translation model, the attention weights for each word in the input sequence could be plotted on a heatmap, with low weights represented by cool colors (e.g., blue) and high weights represented by warm colors (e.g., red).
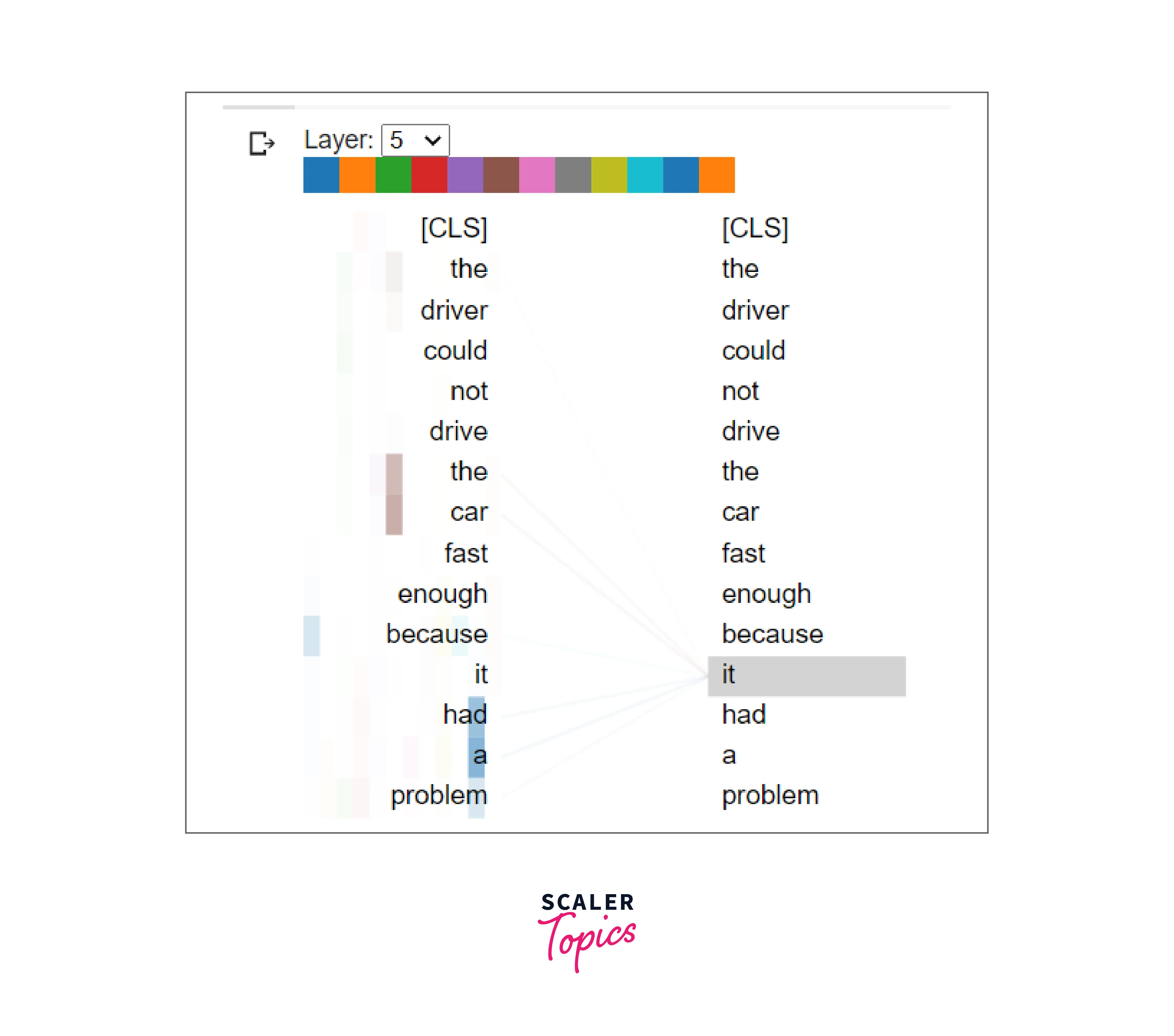
The illustration shows a learned model's attention weights, representing how much the model paid attention to each word in the input sequence when encoding it. The model was able to attend to the word "car" more than any other word when encoding the word "it", which suggests that it was able to understand the context and determine that "it" was referring to the car rather than the driver.
Multi-Headed Attention Architecture
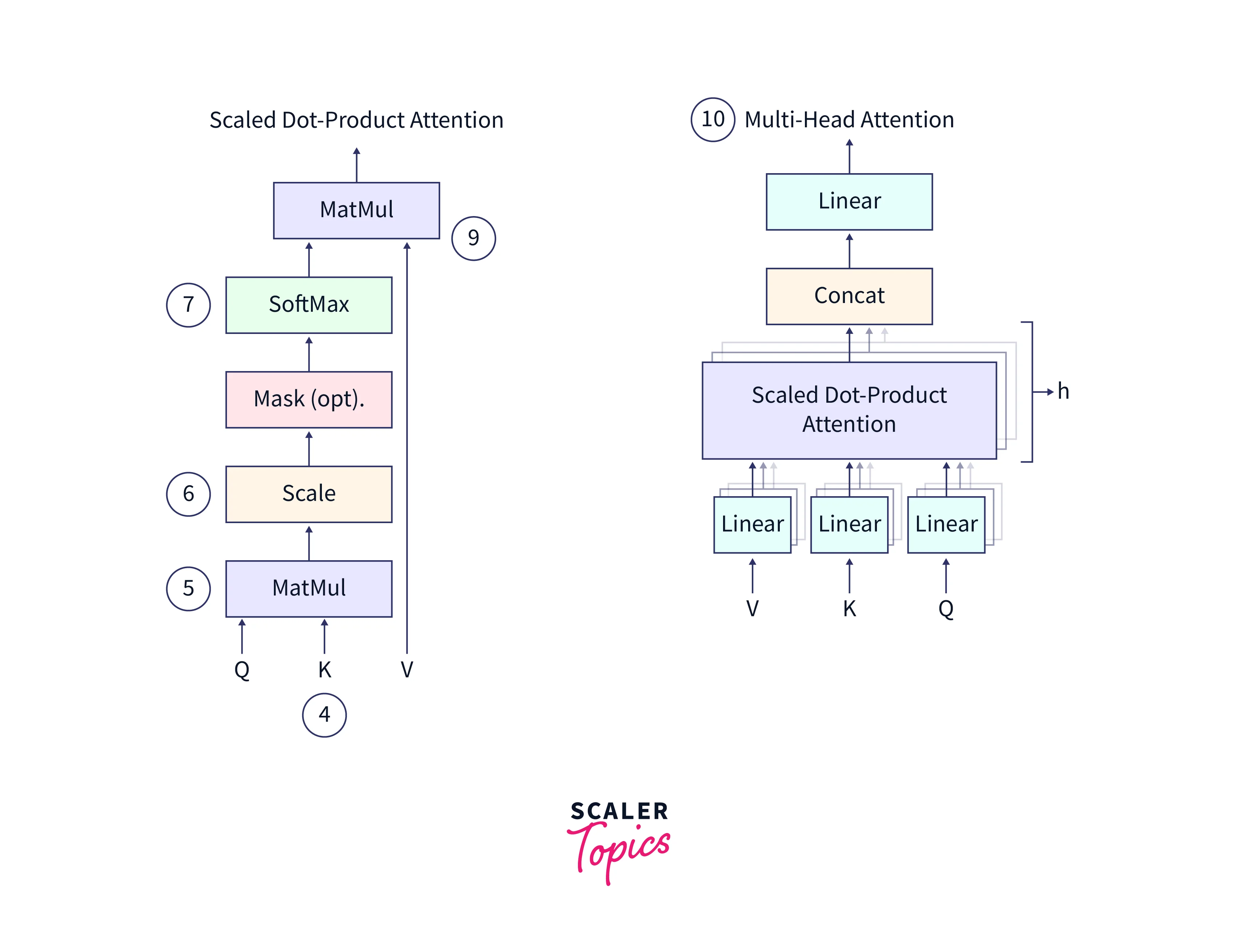
The diagrams above illustrate the Multi-Headed Attention mechanism in detail. Points (4) through (10) are based on the annotations in the image above.
(4) The multi-headed attention mechanism in the transformer consists of three learnable vectors: the query vector, the key vector, and the value vector. These vectors are used to calculate the attention weights for each input element. The motivation for this approach reportedly comes from information retrieval systems, where a query is compared to a key, and a value is returned.
(5) To calculate the attention weights, the query, and key vectors are multiplied through a dot product to produce a scoring matrix. This matrix represents the importance of each word in the input sequence concerning all other words. Higher scores indicate that a word should receive more attention, while lower scores indicate that a word should receive less attention.
(6) The score matrix is then scaled down according to the dimensions of the query and key vectors to ensure more stable gradients. This is necessary because the multiplication of the score matrix can have exploding effects, which can hinder the model's ability to learn.
The masking part of the attention mechanism is used to prevent the model from attending to certain input elements. It is typically used when the input sequence is padded, or the model processes the input in a particular order. We will discuss the masking part in more detail when we discuss the decoder stage of the transformer.
Softmax Function and Obtaining Attention Probabilities
Softmax is used to transform attention scores into probabilities. Attention scores are calculated using a variant of the attention mechanism called self-attention, which allows the model to attend to different parts of the input sequence and consider their relationships when processing the data.
(7) After the score matrix has been calculated, it is transformed into a matrix of probabilities using the softmax function. The purpose of the softmax function is to "squash" the attention scores into a probability distribution, which means that the scores are transformed into values between 0 and 1, with higher scores intensified and lower scores depressed. This ensures the model is confident in its attention weights and can focus on the most important input elements.
(8) The matrix of probabilities is then multiplied element-wise with the value vector, which amplifies the importance of input elements with higher probabilities and downplays the importance of input elements with lower probabilities.
(9) The concatenated output of the query, key, and value vectors is then passed through a linear layer for further processing. The linear layer combines the input vectors through a linear transformation, which allows the model to learn more complex relationships between the input elements.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Final parts of the Encoder block
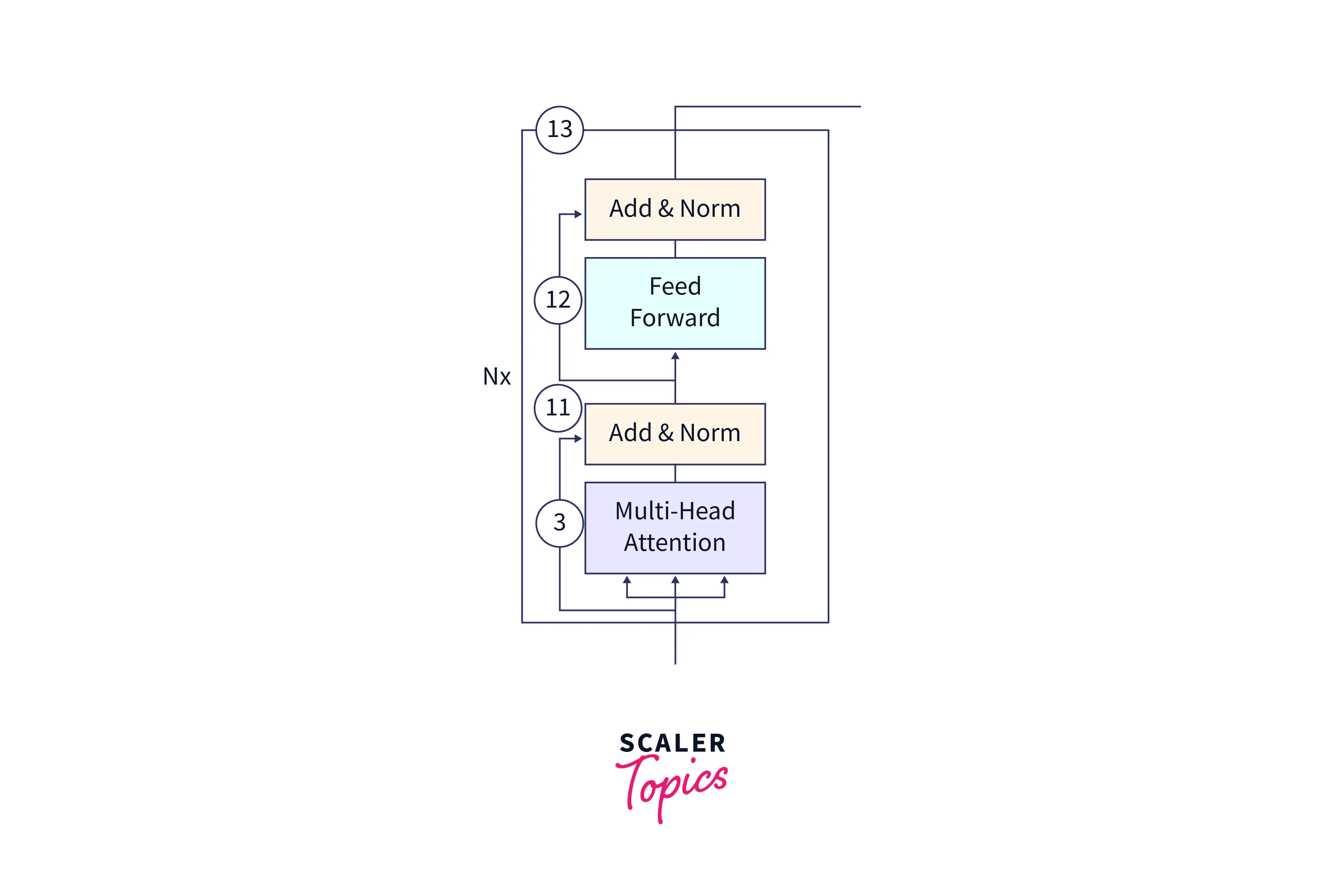
(11) After the self-attention process has been completed, the output value vectors are concatenated and added to the residual connection coming from the input layer. The residual connection helps the gradients flow through the network. Adding the residual connection allows the model to use the information from the input layer and the information learned through the self-attention process. The resulting representation is then normalized using layer normalization, which helps to reduce the training time by a small fraction and stabilize the network.
(12) The output from the self-attention process is then passed through a point-wise feedforward network to obtain an even richer representation of the input data. The feedforward network comprises two linear layers with a non-linear activation function (such as ReLU) in between. It allows the model to learn more complex relationships between the input elements.
(13) The output from the feedforward network is again normalized using layer normalization, and residual connections are added from the previous layer. This helps the model use the information from the previous layers and the information learned through the feedforward process. It can improve the model's ability to capture complex dependencies in the input data.
The encoder plays a vital role in the success of the Transformer architecture, and it is an important component to consider when designing and training these models. Overall, the encoder stage of the Transformer architecture is crucial for the model's ability to process and understand complex input data. It extracts useful features and patterns from the input data, captures relationships between different parts of the input using self-attention mechanisms, and provides a rich representation of the input data for the decoder stage. Using self-attention and feedforward networks in the encoder allows the transformer to capture long-range dependencies and contextual relationships in the input data, essential for tasks such as machine translation and language generation.
Next Steps
Some potential next steps after understanding encoders in transformers could include the following:
- Exploring other components of the transformer architecture, such as the decoder and the attention mechanism.
- Examining the applications of transformers, such as machine translation and language generation, in more detail.
- Evaluating the performance of transformers on various tasks and comparing them to other models.
- Investigating techniques for improving the performance of transformers, such as fine-tuning and data augmentation.
- Applying transformers to a specific problem or task and using them to make predictions or generate output.
Conclusion
- Encoders are neural network layers that process and encode input data in the transformer architecture.
- Encoders comprise multiple encoder blocks containing self-attention and feedforward neural network layers.
- The self-attention layers allow the encoder to attend to different parts of the input sequence and consider their relationships when encoding the data.
- Encoders are important for transformer architecture because they allow the model to process long data sequences efficiently and capture relationships between input parts.
- The transformer encoder-decoder architecture is a popular NLP model that uses self-attention and feed-forward layers to process input and generate output sequences.
- The encoder processes encode the input data, and the decoder generates the output data based on the encoded representation, which serves as the "context" for the decoder.
- The encoder is essential for the transformer's processing and understanding of complex input data.