Building the Word2vec Model Using Gensim
Overview
Word2Vec is a family of models that can take large corpora and represent them in vector space. These representations, also known as word embeddings, are extremely useful as they help us perform many tasks in NLP. From recommender systems to analyzing sentiments from internet feeds to large-scale chatbots, word embeddings have brought life to the field of NLP for decades.
Word2Vec is a vintage model and is very simple to understand. After implementing it, we will use word embedding visualization to understand further how the model works.
What are We Building?
In this article, we are modeling text data by converting large corpora of text into a Vector model using Word2Vec. We will be using the Python library Gensim to do so. We also will build the pipeline needed for word embedding visualization using the TensorFlow Embedding Projector, as well as save the trained model for inference.
Problem Statement
Our problem statement for this article is to create a pipeline using Gensim that uses Word2Vec to process text corpora, visualize the embeddings, and save the trained model to disk.
Prerequisites
Before moving to the actual implementation, there are some pre-requisite topics that we need to know. A summary of them is as follows.
- Embeddings and Word Embedding Visualization :
The output of a Word2Vec model is a word embedding. There are many other models which give similar embeddings, some better than Word2Vec as well. These are synonymous with word vectors for our use case. - Stopwords:
Common words like "the", "to", etc., do not add much to the model but can negatively influence the embedding. - CBOW:
A continuous bag of words uses a single hidden layer NN to predict a source word based on its neighboring words. It uses a sliding window over the sentence to generate these pairs. Consider these examples as (X, Y) pairs to be passed into a model. An example: Given the sentence "I love gensim a lot" and a sliding window of 2, we get ([I, gensim], love), ([love, a], gensim), etc. - Skip-gram:
Skip Grams are a mirror of CBOW. It also uses a similar single hidden layer NN with a sliding window but uses the context words to predict the source word. An example: Given the sentence "I love gensim a lot" and a sliding window of 2, we get (love, [I, gensim]), (gensim, [love, a]), etc
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
How Are We Going to Build This?
We are going to load a custom data file as an input to the model and pre-process it to make it fit the model. After that, we will load the gensim implementation of Word2Vec and train it on the data we loaded. Once the model is done training, we will export the model to disk and load the trained model using Tensorflow Embedding Projector for word embedding visualization. In the process, we also will save and load the model for further inference.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
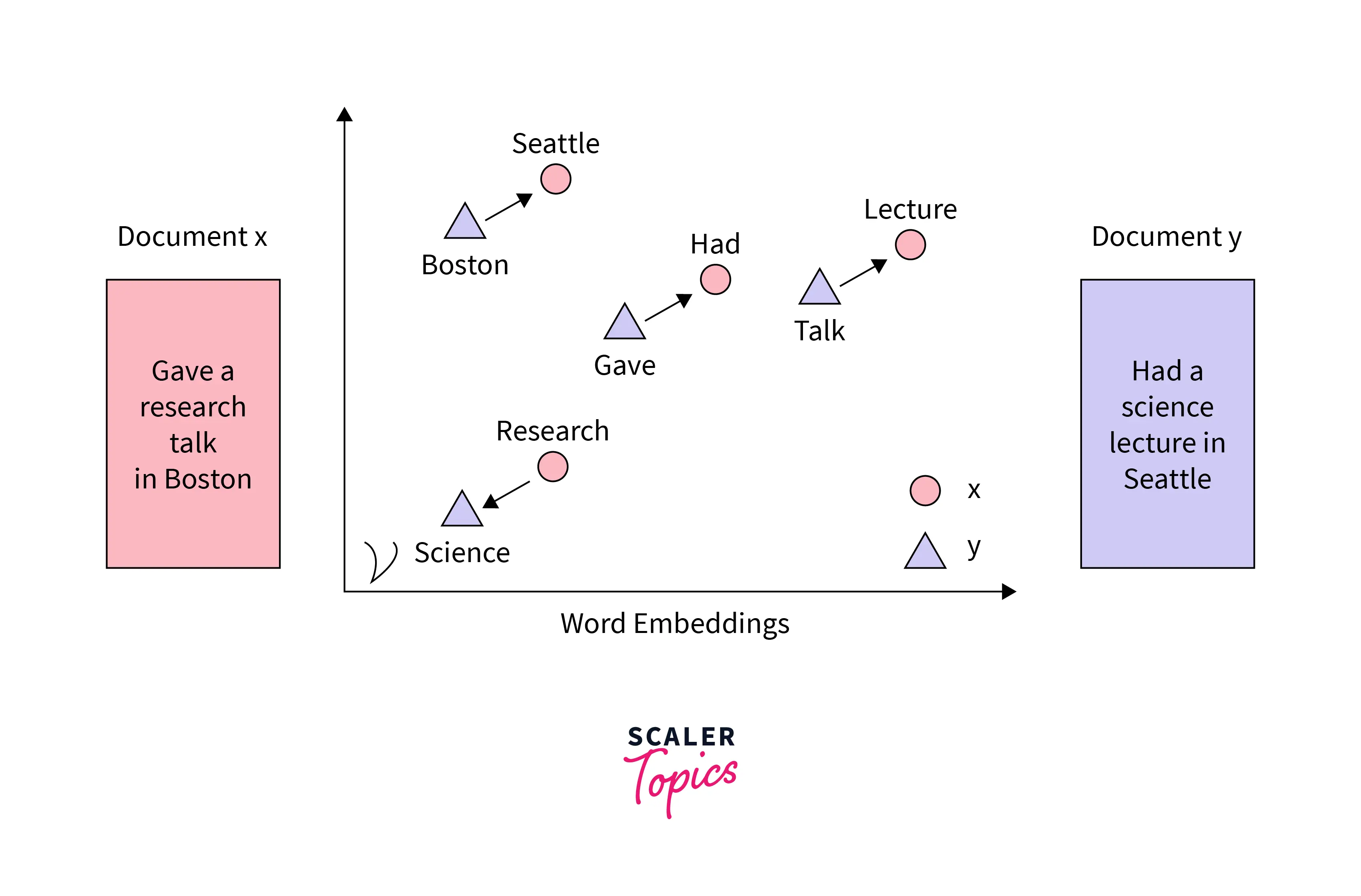
Final Output
The final output that we will get from the model is the text corpora that we load converted to vector space. This vector space can then be used to find similar words from the text and be passed to other neural network models if required. An example of word embedding might look something like this.
Requirements
To create a Word2Vec model, we need to first understand what it is. We will also be looking at the library Gensim where we obtain the Word2Vec model from.
What is Word2Vec?
Word vectors are a numerical representation of text content. Word2Vec is a model that converts large text corpora to a vector representation as doing so provides the corpora with the following properties :
- Since they are converted to numerical vectors, they can be fed into any numerical model, such as a neural network.
- The converted vectors can be compared by using distance metrics such as the cosine distance function ( where A and B are vectors). These metrics make it easy to find related words like the one we want to achieve.
What is Gensim?
Gensim is a text-processing library that lets us train models like Word2Vec very quickly. The library has many more features, such as finding related documents using trained word embeddings and other methods of vectorization that are beyond the scope of this article.
Building Word2Vec Model with Gensim
Now that we have understood the problem statement, we can start building the model using Gensim. We first load all the required packages and data.
Turn Learning into Career Growth
Loading Packages and Data
Before we build the Word2Vec Model, we need to load a few packages along with the data. These packages can be installed using pip. (Eg : pip install gensim). That is if they are not already present in the system that is being used. We also download the stopwords and punctuation data from nltk.
After this, we load the data. For this demo, we will be using text from the book "Emma" by "Jane Austen". This dataset is a public domain dataset from Project Gutenberg that comes with nltk. We can get it using the following code.
We can also use custom text by creating a text file called "sample.txt" in the same directory as the code and pasting whatever we want. (Make sure it is English text).
Data Preprocessing
After loading the data, we need to pre-process it to be able to pass it to the model by removing stopwords and punctuation and converting the words into lowercase tokens. We should get something like this ['emma', 'jane', 'Austen', '1816']
Gensim Word2Vec Model Training
Once both the data and the model have been loaded, we can train it on the data using the following code.
Parameters of the Word2Vec Model
The Word2Vec model implemented in Gensim has a few parameters that we can tune based on the task. They are explained as follows :
- sentences :
This is the pre-processed input text. - size :
This is the maximum dimension size of the output vector. - window :
This is the sliding window size. - min_count :
The minimum word frequency below which words would not be passed to the model. - workers :
This is the number of parallel threads for processing. - sg :
1 for the Skip Gram model, 0 for the CBOW model. - CBOW is prone to overfitting words that frequently appear in the same contexts, so try SkipGrams as well. - Skip grams need more data and are more resource intensive but perform better. Choose it based on the task at hand. - iter :
This is the number of iterations the model will update its gradients for. Tweaking these parameters also helps improve the accuracy of the word embedding visualization.
Compute Similarities
The Word2Vec model can also be used to find similar words in a text. We can find words similar to a random word we pick from the text to see our model works.
Since we used data from Emma, let us try searching for the word "book".
We get the following words and how related the model thinks they are to the word "book".
T-SNE Visualizations
To see what the embedding space looks like, we can give these embeddings to Tensorboard.
To do so, make sure the model is saved. Here we have saved it as "wvecemma". Now we use a script that comes inbuilt with Gensim to convert our Word2Vec model to the Tensorboard format.
We get two files, "model_tensor.tsv" and "model_metadata.tsv".
To convert the model to a Keras Embedding, use the code (for model w), w.wv.get_keras_embedding()
Now we can either open Tensorboard (if you have it installed) and navigate to this folder and open the generated files, or go to this website tensorflow-projector.
On the website, click the Load button. For Step 1, choose the "model_tensor.tsv" file, and for Step 2, choose the other one.
We can then see the embeddings directly.

Saving and Loading the Model
To prevent having to train again, we save the model to disk using the following code.
This model can then be loaded for inference during production using the following code.
Conclusion
- This article taught us how to implement the Word2Vec model in Gensim.
- We learned how to perform word embedding visualization using the TensorBoard Embedding Projector.
- We also learned how to use our data to train a Word2Vec model.