XLM and XLM-RoBERTa
Overview
Natural language processing (NLP) has witnessed significant advancements in multilingual language models, enabling models to understand and process text in multiple languages. XLM and XLM-RoBERTa are two prominent models in this domain designed to overcome the challenges of cross-lingual understanding. This article will explore the importance of multilingual language models, introduce XLM and XLM-RoBERTa, and discuss their architecture, training process, and applications in cross-lingual NLP tasks.
What are Multilingual Language Models?
Multilingual language models are models that are trained on text from multiple languages. They learn to encode and generate text in different languages, enabling them to understand and generate text in any of the languages they were trained on. These models are often trained on a large corpus of multilingual text and then fine-tuned on specific downstream tasks.
One of the key advantages of multilingual language models is their ability to transfer knowledge across languages. By learning shared representations, these models can leverage the knowledge gained in one language to perform well in another language, even if the training data for that language is limited. This makes multilingual language models particularly useful in scenarios where a diverse set of languages needs to be processed or analyzed.
What are Cross-lingual Models?
Cross-lingual models are a specific type of multilingual language model that focuses on enabling language understanding and translation across multiple languages. These models aim to bridge the language barrier by learning to encode text in one language and decode it into another language. They can be used for tasks such as machine translation, cross-lingual document classification, and cross-lingual information retrieval.
Cross-lingual models like XLM and XLM-RoBERTa achieve cross-lingual understanding by learning language-agnostic representations. These representations capture semantic and syntactic information that is shared across languages, allowing the models to map text from one language to another. This is particularly useful in scenarios where labeled data for each language is limited, as the models can leverage the knowledge learned from other languages to improve performance.
Introduction to XLM and XLM-RoBERTa
XLM (Cross-lingual Language Model) and XLM-RoBERTa are both multilingual language models developed by Facebook AI. They are designed to understand and generate text in multiple languages, addressing the challenges of cross-lingual understanding.
XLM is based on the architecture of BERT (Bidirectional Encoder Representations from Transformers) and learns to encode cross-lingual information by training on parallel data, which consists of sentences in different languages aligned at the sentence level. XLM can perform tasks such as machine translation, cross-lingual classification, and text classification across different languages.
XLM-RoBERTa is an improved version of XLM that builds upon the RoBERTa architecture. RoBERTa is a variant of BERT that has been pre-trained on a larger dataset and for more training steps, resulting in enhanced performance in downstream natural language processing tasks. XLM-RoBERTa inherits the cross-lingual capabilities of XLM while benefiting from the improved representation learning of RoBERTa.
Both XLM and XLM-RoBERTa have been successfully used in various applications of natural language processing, including machine translation, cross-lingual classification, sentiment analysis, and text categorization.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
XLM
XLM, short for Cross-lingual Language Model, is a multilingual language model developed by Facebook AI Research. It is based on the Transformer architecture, a popular neural network architecture for sequence transduction tasks. XLM is pre-trained on a large corpus of text from 100 different languages, allowing it to learn shared representations that capture linguistic properties across languages.

XLM introduces several innovations to make cross-lingual learning effective. It incorporates a language modeling objective that encourages the model to learn to predict masked words in a sentence, similar to the approach used in BERT (Bidirectional Encoder Representations from Transformers). XLM also introduces a translation language modeling objective, where the model predicts the translation of a sentence into another language. This helps the model learn to align representations between languages.
XLM Architecture
XLM utilizes the Transformer architecture, which has proven effective in various NLP tasks. It extends the architecture to handle multiple languages and learn cross-lingual representations.
The key components of the XLM architecture include:
-
Transformer Encoder:
XLM employs a multi-layer Transformer encoder, similar to BERT. The Transformer architecture allows for efficient parallel processing of sequential data and captures long-range dependencies in the text. -
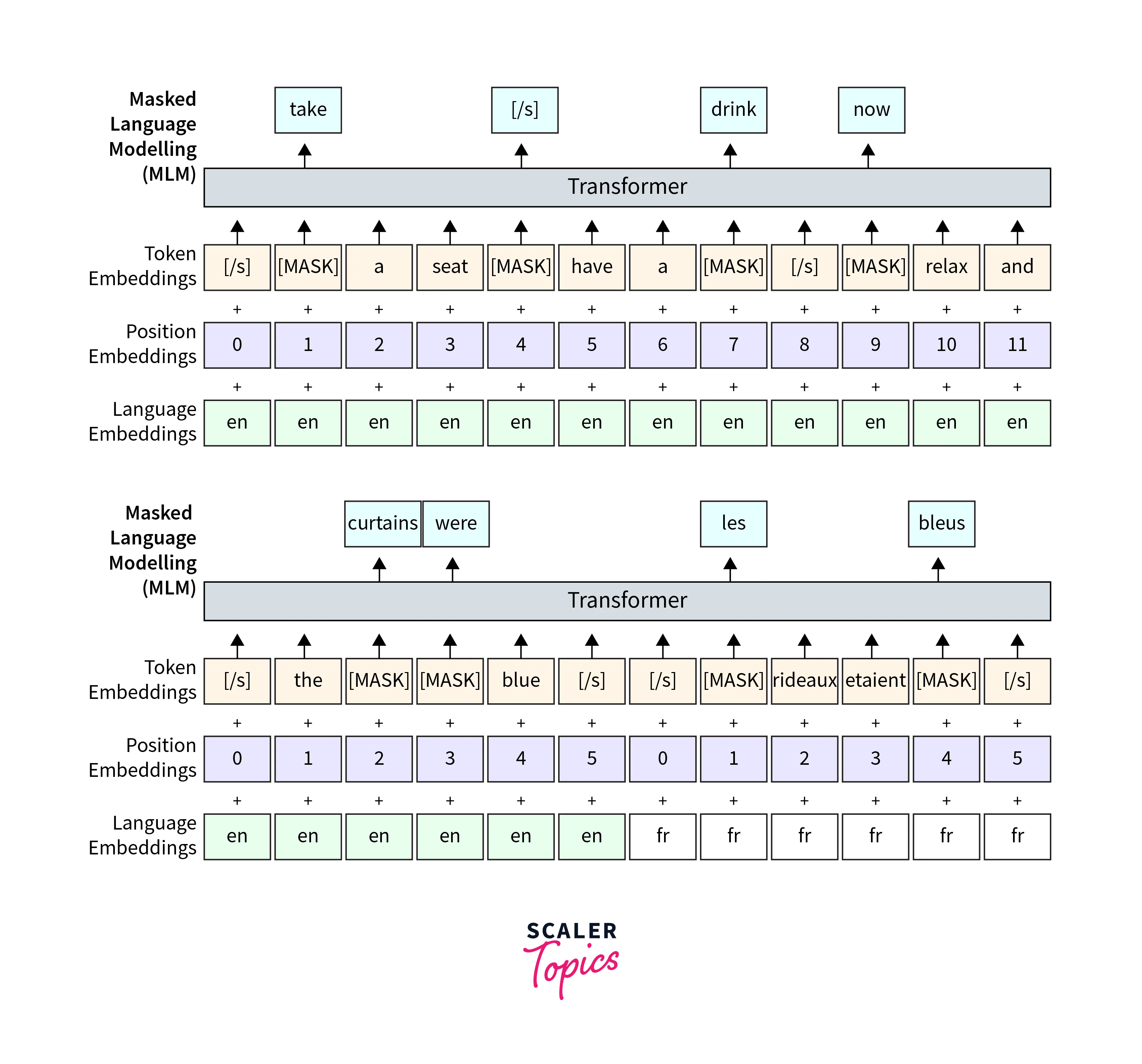
Cross-lingual Masked Language Modeling (XLM-MLM):
During pre-training, XLM uses a variant of the masked language modeling (MLM) objective called cross-lingual MLM. In this process, words from different languages are randomly masked in a sentence, and the model is trained to predict those masked words. This encourages the model to learn language-agnostic contextual representations, helping it understand multiple languages effectively. -
Bilingual Objective:
XLM introduces a bilingual objective, where parallel data (sentences in two languages with the same meaning) is leveraged during training. This allows the model to learn cross-lingual alignments and transfer knowledge from one language to another.
Pre-training Process and Training Objectives
The pre-training process of XLM involves training the model on a large corpus of monolingual and bilingual data from multiple languages. The training objectives include:
-
Cross-lingual Masked Language Modeling (XLM-MLM):
Similar to BERT's MLM, words are randomly masked in sentences, and the model is trained to predict the masked words. Unlike BERT, XLM considers words from different languages, making it cross-lingual. -
Bilingual Objective:
In addition to the XLM-MLM, XLM uses parallel data, where sentences in two languages convey the same meaning. The model is trained to align the representations of parallel sentences, allowing for cross-lingual transfer learning.
By combining these training objectives, XLM learns to generate contextual embeddings that effectively capture language-specific features while retaining cross-lingual information.
Key Features and Advantages of XLM
XLM offers several key features and advantages:
-
Multilingual Capability:
XLM can understand and generate text in multiple languages. It surpasses the limitations of traditional language models, which were designed for specific languages and lacked cross-lingual transferability. -
Cross-Lingual Transfer Learning:
One of the significant advantages of XLM is its ability to transfer knowledge learned from one language to another. This is particularly valuable for languages with limited training data, as the model can leverage information from related languages. -
Improved Cross-lingual Representations:
The XLM architecture, with its bilingual objective and cross-lingual MLM, encourages the model to learn representations that capture language-agnostic features. This helps improve cross-lingual understanding and performance in various downstream NLP tasks.
Overall, XLM's architecture and training objectives make it a pivotal advancement in developing multilingual language models, promoting cross-lingual understanding and knowledge transfer in natural language processing.
Turn Learning into Career Growth
XLM-RoBERTa
XLM-RoBERTa is an extension of XLM that employs the RoBERTa architecture, a variant of the Transformer model, for pre-training.
It is based on the RoBERTa architecture, an optimized variant of BERT (Bidirectional Encoder Representations from Transformers). XLM-RoBERTa builds upon the strengths of XLM while incorporating advancements from RoBERTa to achieve even better performance in multilingual language understanding and downstream NLP tasks.
The key idea behind XLM-RoBERTa is to leverage the pre-training methodology of RoBERTa, which involves large-scale pre-training and extensive hyperparameter tuning, to create a more powerful and effective cross-lingual language model.
XLM-RoBERTa Architecture
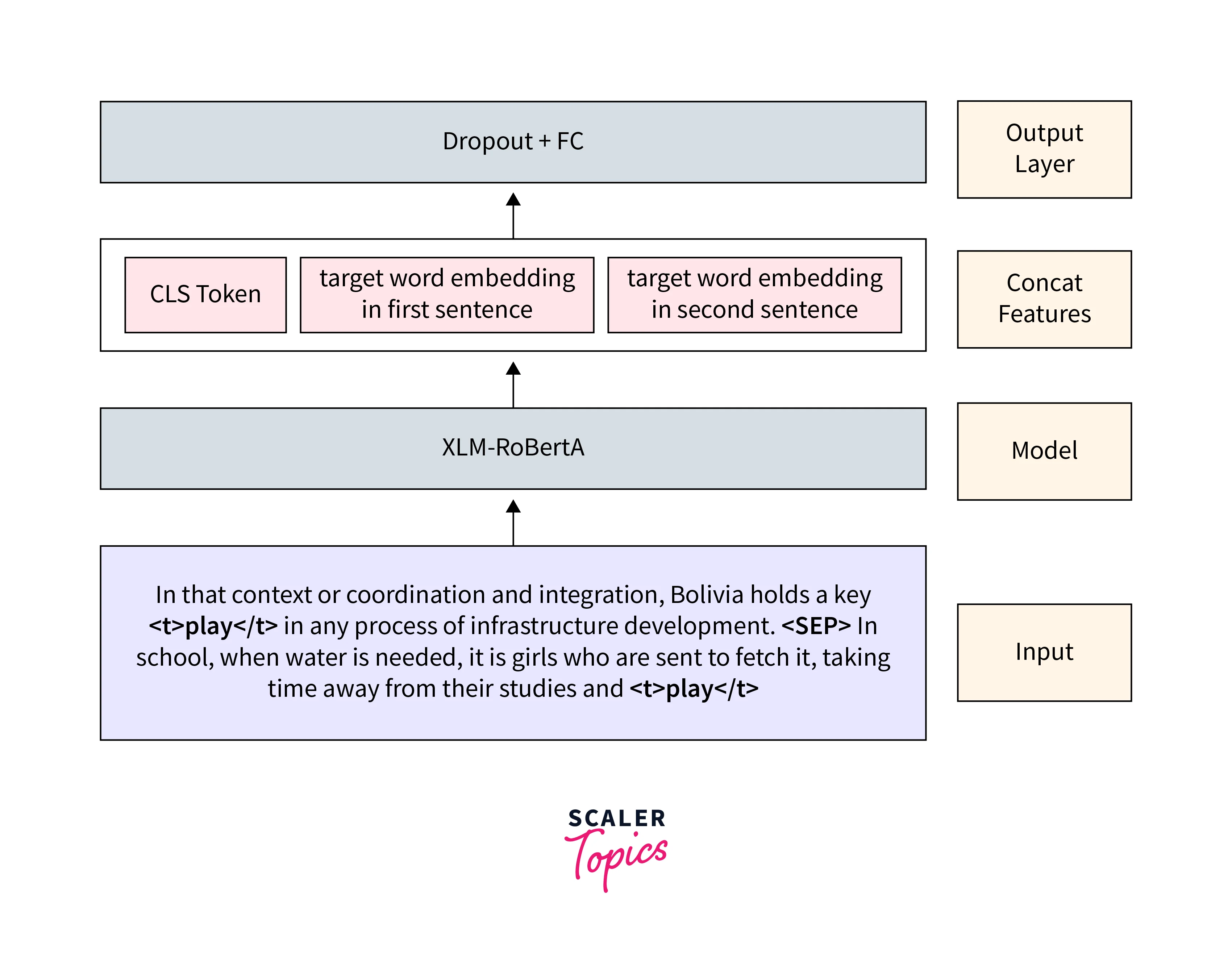
The XLM-RoBERTa architecture is similar to other transformer-based models like BERT. It consists of embedding layers, transformer encoders, and a downstream structure. Here is a breakdown of the architecture
-
Embedding Layers:
Similar to other transformer models, XLM-RoBERTa starts with embedding layers. These layers map input tokens to continuous vector representations, known as word embeddings. XLM-RoBERTa uses byte pair encoding (BPE) to handle subword units, allowing it to handle out-of-vocabulary words and capture morphological information. -
Transformer Encoders:
The core of the XLM-RoBERTa architecture is the transformer encoder. It consists of multiple layers of self-attention mechanisms and feed-forward neural networks. Each layer in the encoder processes the input sequence in parallel, allowing the model to capture both local and global dependencies.The self-attention mechanism enables the model to attend to different parts of the input sequence while encoding contextual information. It computes attention weights for each input token, allowing the model to focus on relevant information during encoding.
The feed-forward neural networks within each transformer layer help capture complex relationships and non-linearities in the input sequence.
-
Downstream Structure:
The output of the transformer encoder is passed through a downstream structure, which can vary depending on the specific task the model is trained for. This structure typically consists of additional layers (e.g., fully connected layers) that transform the encoded representations into task-specific outputs.Overall, the XLM-RoBERTa architecture is designed to learn powerful sentence representations that can capture semantic and syntactic information across different languages. By training on a large amount of multilingual data, XLM-RoBERTa can leverage the shared information between languages to improve performance on various cross-lingual tasks.
Fine-tuning Process and Dataset Preparation
The fine-tuning process of XLM-RoBERTa is similar to that of XLM. After the initial pre-training on a large corpus of monolingual and bilingual data from multiple languages, the model is fine-tuned on specific downstream NLP tasks using task-specific labeled datasets.
The dataset preparation for fine-tuning involves the following steps:
-
Task-specific Datasets:
A task-specific labeled dataset is prepared for each downstream NLP task. For example, if the task is sentiment analysis, the dataset will contain sentences with corresponding sentiment labels (positive/negative/neutral). -
Language Tagging:
In multilingual datasets, each sentence is usually tagged with its language of origin. This helps the model understand the language context and perform language-specific tasks. -
Tokenization and Encoding:
The sentences in the dataset are tokenized into subwords or word pieces and then encoded to create input sequences suitable for the XLM-RoBERTa model. -
Training Objective:
During fine-tuning, the model is trained to minimize the task-specific loss function, which is determined by the nature of the downstream NLP task (e.g., cross-lingual document classification, machine translation, etc.).
By fine-tuning the pre-trained XLM-RoBERTa model on specific tasks, it adapts to the target task and language characteristics, allowing it to excel in a wide range of multilingual NLP applications.
Advancements and Performance Comparisons
XLM-RoBERTa introduces several advancements over XLM, which contribute to its improved performance:
-
Larger Pre-training Corpus:
XLM-RoBERTa utilizes a larger pre-training corpus, similar to RoBERTa. This helps the model learn more robust and generalized representations from the diverse and extensive language data. -
More Training Steps:
XLM-RoBERTa undergoes more pre-training steps than XLM. The increased number of steps allows the model to converge better and capture finer language nuances. -
Removed Next Sentence Prediction (NSP):
RoBERTa and XLM-RoBERTa do away with the next sentence prediction (NSP) task used in the original BERT. Instead, they rely solely on the masked language modeling (MLM) objective, which is more effective.
Performance comparisons between XLM-RoBERTa and other multilingual language models have shown that XLM-RoBERTa achieves state-of-the-art results in various cross-lingual NLP tasks. Its enhanced architecture and fine-tuning of task-specific datasets enable it to outperform its predecessors, including XLM and other competitive models in multilingual language understanding and transfer learning.
Handling Language Diversity with XLM Models
XLM models, like XLM-RoBERTa, excel in handling language diversity. They efficiently tackle various languages, even low-resource ones, through their versatile design.
-
Language Tokenization and Embeddings:
XLM models utilize a consistent tokenizer for multiple languages, ensuring uniform tokenization. Encoded text transforms into numerical embeddings for model input. The tokenization approach encompasses subword tokens, accommodating out-of-vocabulary words and morphologically complex languages. Embeddings are shared across languages, helping the model link similar concepts. -
Language Similarity and Transfer Learning:
Pre-training on extensive multilingual corpora enables XLM models to predict masked words, capturing cross-lingual patterns. The model learns to encode language similarities. This ability translates to downstream tasks, such as sentiment analysis, even across languages not seen during training. -
Low-Resource and Under-Resourced Languages:
XLM models stand out in handling languages with limited data. Shared embeddings empower them to leverage knowledge from well-resourced languages, enhancing performance on low-resource languages. Even with minimal training data, the model can generalize better and achieve notable results.
Applications of XLM and XLM-RoBERTa
XLM and XLM-RoBERTa models have found applications in several areas, including machine translation, cross-lingual classification, and text classification. Here are some specific applications of XLM and XLM-RoBERTa:
- Machine Translation:
XLMs can be used as a pretraining method for unsupervised or supervised neural machine translation. By leveraging cross-lingual language modeling, XLM models can improve the performance of machine translation systems for different language pairs. - Cross-lingual Classification:
XLM-RoBERTa models, in particular, have been used for cross-lingual classification tasks such as sentiment analysis, hate speech detection, and news headline categorization. By pretraining on a large corpus of multilingual data, XLM-RoBERTa can effectively encode cross-lingual information and enable accurate classification across different languages. - Text Classification:
XLM-RoBERTa models have also been applied to text classification tasks, such as binary text classification and multi-class classification. These models can be used to train text classifiers on specific datasets, leveraging the pretraining on large multilingual corpora to improve classification accuracy.
Overall, XLM and XLM-RoBERTa models have shown promising results in various natural language processing tasks, particularly in cross-lingual understanding and text classification.
Conclusion
- XLM and XLM-RoBERTa represent significant advancements in cross-lingual language understanding.
- These models have broken language barriers and enabled efficient communication across diverse linguistic backgrounds.
- The importance of multilingual language models continues to grow as the world becomes more interconnected.
- XLM and XLM-RoBERTa have demonstrated their effectiveness in various cross-lingual NLP tasks, making them indispensable tools for researchers, developers, and businesses in multilingual settings.