Process Scheduling in Linux
Introduction
Scheduling of processes is one of the most important aspects or roles of any operating system. A Process Scheduler deals with process scheduling in Linux. Process Scheduler uses Scheduling Algorithms that help in deciding the process to be executed.
The Linux Scheduling Algorithm
Process scheduling is one of the most important aspects or roles of any operating system.
- Process Scheduling is an important activity performed by the process manager of the respective operating system.
- Scheduling in Linux deals with the removal of the current process from the CPU and selecting another process for execution.
Let us learn more about scheduling strategies (scheduling algorithms) used in Linux operating systems.
Similar to the other UNIX-based operating systems, in LINUX a Process Scheduler deals with process scheduling.
- Process Scheduler chooses a process to be executed.
- Process scheduler also decides for how long the chosen process is to be executed.
Hence, Scheduling Algorithms is nothing but a kind of strategy that helps the process scheduler in deciding the process to be executed.
Scheduling Process Types in Linux
In the LINUX operating system, we have mainly two types of processes namely - Real-time Process and Normal Process. Let us learn more about them in detail.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Realtime Process
Real-time processes are processes that cannot be delayed in any situation. Real-time processes are referred to as urgent processes.
There are mainly two types of real-time processes in LINUX namely:
- SCHED_FIFO
- SCHED_RR.
A real-time process will try to seize all the other working processes having lesser priority.
For example, A migration process that is responsible for the distribution of the processes across the CPU is a real-time process. Let us learn about different scheduling policies used to deal with real-time processes briefly.
SCHED_FIFO
FIFO in SCHED_FIFO means First In First Out. Hence, the SCHED_FIFO policy schedules the processes according to the arrival time of the process.
SCHED_RR
RR in SCHED_RR means Round Robin. The SCHED_RR policy schedules the processes by giving them a fixed amount of time for execution. This fixed time is known as time quantum.
Note: Real-time processes have priority ranging between 1 and 99. Hence, SCHED_FIFO, and SCHED_RR policies deal with processes having a priority higher than 0.
Normal Process
Normal Processes are the opposite of real-time processes. Normal processes will execute or stop according to the time assigned by the process scheduler. Hence, a normal process can suffer some delay if the CPU is busy executing other high-priority processes. Let us learn about different scheduling policies used to deal with the normal processes in detail.
Normal (SCHED_NORMAL or SCHED_OTHER)
SCHED_NORMAL / SCHED_OTHER is the default or standard scheduling policy used in the LINUX operating system. A time-sharing mechanism is used in the normal policy. A time-sharing mechanism means assigning some specific amount of time to a process for its execution. Normal policy deals with all the threads of processes that do not need any real-time mechanism.
Batch (SCHED_BATCH)
As the name suggests, the SCHED_BATCH policy is used for executing a batch of processes. This policy is somewhat similar to the Normal policy. SCHED_BATCH policy deals with the non-interactive processes that are useful in optimizing the CPU throughput time. SCHED_BATCH scheduling policy is used for a group of processes having priority: 0.
Note: Throughput refers to the amount of work completed in a unit of time.
Idle (SCHED_IDLE)
SCHED_IDLE policy deals with the processes having extremely Low Priority. Low-priority tasks are the tasks that are executed when there are absolutely no tasks to be executed. SHED_IDLE policy is designed for the lowest priority tasks of the operating systems.
Note: Normal processes have a static priority that is 0. Hence, SCHED_NORMAL, SCHED_BATCH, and SCHED_IDLE policies only deal with 0-priority processes.
History of Linux scheduler
Before learning about different LINUX schedulers, let us discuss the history and evolution of the different schedulers associated with the different LINUX kernels.
-
Initially, the LINUX kernel used the RR or Round-Robin approach to schedule the processes. In the Round-Robin approach, a circular queue was maintained that held the processes. The advantage of using a round-robin was its fast behavior and easy implementation.
-
After the introduction of scheduling classes in LINUX Kernel 2.2, the processes were divided into three process classes:
- Real-time process
- Non-preemptive process(a process does not leave the CPU until the process makes its system call)
- Normal process.
-
After the introduction of the O(N) scheduler in LINUX Kernel 2.4, a queue is used to store processes. At the time of scheduling, the best process in the queue is selected according to tho the priority of the processes.
-
In the LINUX Kernel 2.6, the complexity of the scheduler was reduced from O(N) to O(1).
-
After O(1) scheduler, CFS, or Completely Fair Scheduler was introduced.
Now, let us discuss the different schedulers.
Refer to the image below to see the locations of different schedulers in the Kernel.
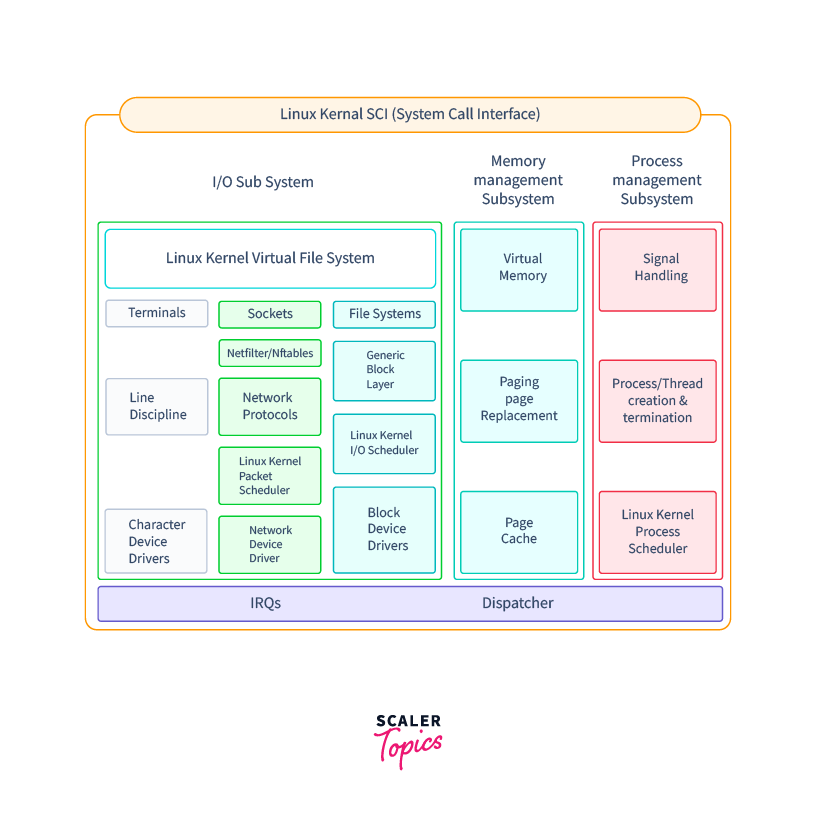
O(n) Scheduler
The LINUX Kernel used the O(n) scheduler between version 2.4 and 2.6.
- n is the number of runnable processes in the system.
- O(n) scheduler divides the processor's time into a unit called epochs.
- Each task is allowed to use at max 1 epoch. If the task is not completed in the specified epoch, then the scheduler adds half of the remaining time in the next epoch.
O(n) scheduler was better than the earlier used circular queue scheduler because O(n) scheduler could schedule N-processes at a time.
Turn Learning into Career Growth
O(1) Scheduler
O(1) Scheduler was introduced in LINUX Kernel 2.6. O(1) scheduler is also called as Big O of 1 scheduler or constant time scheduler. As the name suggests, it can schedule the processes within a constant amount of time, regardless of the number of processes running on the system.
- O(1) scheduler uses two queues.
- The active processes are placed in a queue that stores the priority value of each process. This queue is termed as run queue, or run queue.
- The other queue is an array of expired processes called expired queue. When the allotted time of a process expires, it is placed into the expired queue.
The scheduler gives priority to interactive tasks and lowers the priorities of the non-interactive tasks.
CFS Scheduler
CFS stands for Completely Fair Scheduler, it handles the CPU resource allocation for executing processes. The main aim of CFS is to maximize the overall CPU utilization and performance. CFS uses a very simple algorithm for process scheduling.
- CFS uses a red-black tree instead of a queue for the scheduling.
- All the processes are inserted into Red-Black trees and whenever a new process arrives, it is inserted into the tree.
CFS Usage of Red-Black Tree
As we know, a red-black tree is a self-balancing binary search tree having nodes colored red or black. These red and black colors are used to ensure that the tree maintains its balanced nature both during insertions and deletions.
Note: Insertion and deletion time complexity of RB Tree is O(log(n)).
The main aim of using an RB Tree is Rb Tree's self-balancing nature. RB Tress is used to representing a task and to find out which task to be executed next.
Each task is stored in the RB tree was based on its virtual run time(vruntime). We will learn about vruntime later in this article. When CFS needs to pick the next task to be executed, it picks the leftmost node. Because the leftmost node in the tree resembles the node having the least virtual runtime.
Note:
- Declarations of the RB Tree are stored in linux/rbtree.h
- Implementation of RB tree functions is stored in linux/lib/rbtree.c
Priority Scheduling with Dynamic Priority
Dynamic priority scheduling is also a type of scheduling algorithm. In Dynamic priority scheduling, the priorities are calculated at the time of execution of the processes. The main aim of dynamic priority scheduling in Linux is to adapt to the dynamically changing progress and to form optimal scheduled processes. Dynamic priority gives high CPU utilization which means higher utilization of resources and better performance.
- Priority scheduling algorithms are also known as online scheduling algorithms.
- Priority scheduling in Linux is easy to implement as many times it does not require any priority queue.
:::
Virtual Runtime
The Virtual Runtime of a process is the amount of time spent by the process in the actual execution. Virtual runtime does not include any other time like response time or waiting time.
The CFS uses virtual runtime or Vruntime to schedule the processes. The CFS maintains variables holding the maximum and minimum virtual runtime namely - max_vruntime and min_vruntime. These max_vruntime and min_vruntime variables are used to insert the process as a node in the Red-Black Trees.
The new processes and the processes that got back to the ready state from the waiting queue are assigned min_vruntime. These new processes are then inserted into the RB tree node with the key as min_vruntime.
Conclusion
- Process Scheduler uses Scheduling Algorithms that help in deciding the process to be executed.
- In LINUX, there are two types of processes namely - Real-time processes and Normal processes.
- O(n) scheduler divides the processor's time into a unit called epochs. Each task is allowed to use at max 1 epoch.
- O(1) schedule the processes within a constant amount of time, regardless of the number of processes running on the system.
- CFS (Completely Fair Scheduler), handles the CPU resource allocation. To represent a task, CFS uses a Red-Black Tree.
- In dynamic priority scheduling, the priorities are calculated at the time of execution of the processes.
- Virtual Runtime of a process is the amount of time spent by the process in the actual execution.