What is a RDBMS (Relational Database Management System)?

RDBMS is an abbreviation for Relational Database Management System. It is a class of Database Management systems that emphasizes the relationships among data objects. Common types of RDBMS software examples are MySql, MariaDB, PostgreSQL, Oracle, SQL Server, etc.
A Brief History of RDBMS
The term "relational database" was invented at IBM by E. F. Codd in the . Four years later, IBM began the development of System R, a research project to develop a prototype RDBMS. The first RDBMS software sold was Multics Relational Data Store around June . In Oracle was released by Oracle Corporation, the then Relational Software. Some other examples of an RDBMS would be SAP Sybase ASE, IBM Db2, Informix, etc. In the development of the first RDBMS for Macintosh code-named Silver Surfer, was released in as Dimension.
Why Do We Need RDBMS?
Following are some major reasons for which Relational Database Management Systems are required :
- Data Safety:
Data is kept safe in an RDBMS when any of its programs(s) crash. - Fault Tolerance:
RDBMS provides Fault Tolerance by replication of the database. This is helpful when the system crashes for some reason such as an accidental shutdown, sudden power cuts, etc. - RDBMS also facilitates concurrent access.
- Ease of Use:
While using RDBMS, accessing or managing the data becomes simple because of using tables for storing data in rows and columns. - Scalability:
RDBMS can handle very small to very large amount quantities of data in a uniform fashion. - Indexing:
In RDBMS indexes are used for sorting data which in turn speeds up performance.
Features of RDBMS
- RDBMS represents data in simple logical constructs called tables or relations which are based on the set theory.
- Each table (relation) is a set and thus we can manipulate each table using the rules of set theory such as union, intersection, etc.
- This helps eliminate the parent chain hierarchy, thus representing data in a database as simple two-dimensional tables indexed by combinations of different rows and columns, in which are stored data values.
- The objects of which we desire to store the data of, are stored in relations as rows that represent individual records, and columns that represent characteristics called attributes of the object.
- A column, that represents the properties of an object, holds a value for every record in a certain format. These values must conform to the domain from which they were assigned.
- Data in a relation may be retrieved by a query, which is a statement from a data language, which is a non-procedural language because it is not mandatory to specify the procedure that must be followed to get the work done.
- Data Manipulation Language (DML) is the language used for manipulating the data stored in a database and consists of a set of instructions.
How Does RDBMS Work?
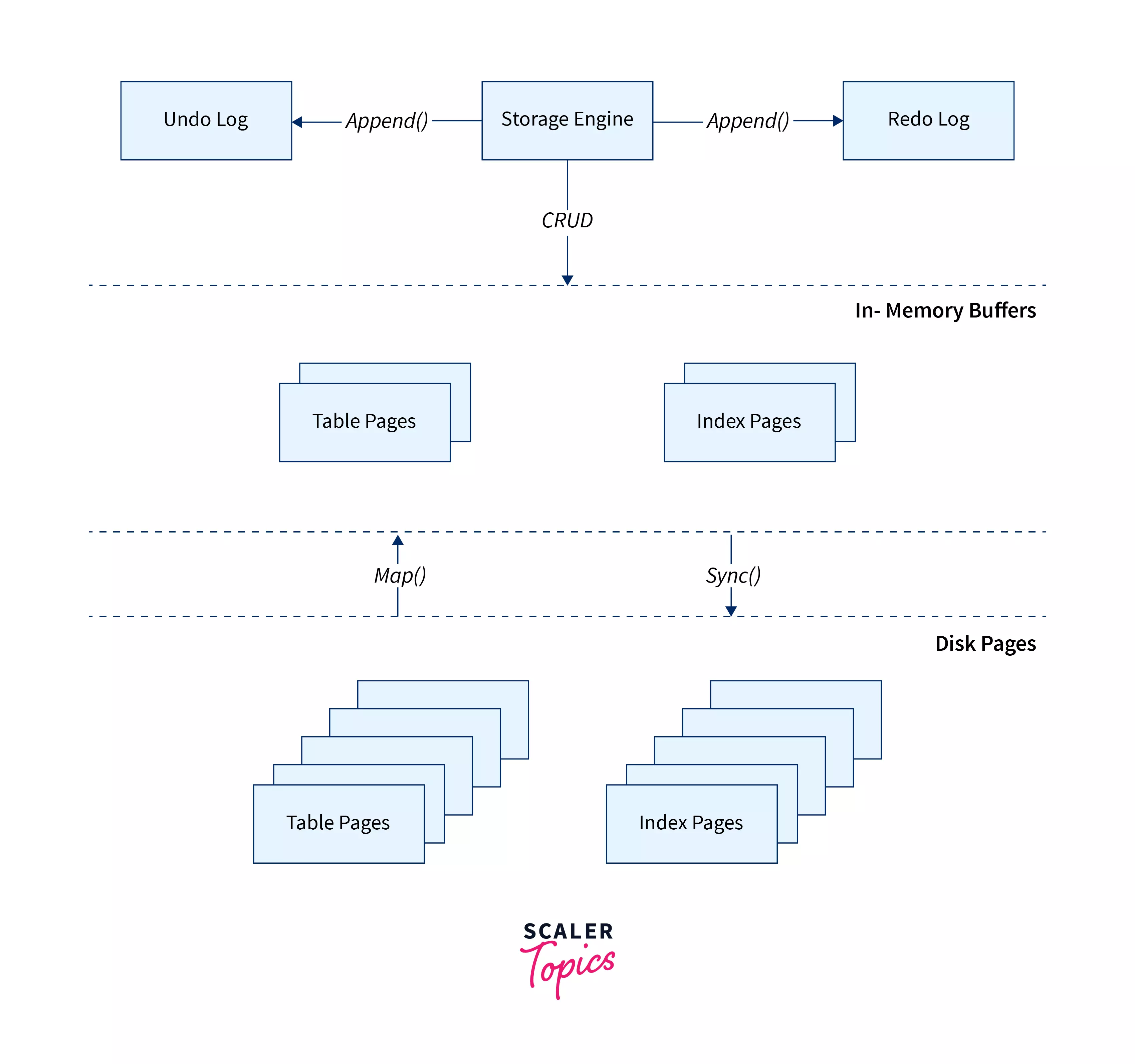
Following is an abstract representation of the working of a relational database management system :
Data Pages :
Disk accesses are slow, so vendors try to minimize them as much as possible. Data is divided into several pages of the same fixed size. When it is required to access data, a relational database will map the secondary-memory-based pages into primary memory buffers. When modification of the disk data is required, only the in-memory pages are altered by the relational database.
The disk-based pages are stored in the buffer pool which is of limited size. Therefore it usually requires storing the data working set. The buffer pool may store the entire data set, only if the memory accommodates it. If the data on the disk is bigger than the size of the buffer pool when a new page is to be cached, the buffer pool will evict old pages to make space for the new pages.
Undo log:
Since many concurrent transactions may access the in-memory changes, a concurrency control mechanism must be employed to ensure data integrity. Hence, once a transaction has altered any row of a table, the uncommitted changes are applied to the in-memory structures while the previous data is stored temporarily in an append-only undo log structure. If the currently executing transaction rolls back, the undo log will reconstruct the in-memory pages by the beginning of the transaction.
Redo log:
After a transaction has been committed, the in-memory changes must persist. We know, from the ACID transaction properties, that a committed transaction must provide durability, which indicates that all committed changes must persist. This is where the redo log comes into action.
It is also a disk-based append-only structure that holds every change done to a transaction. When a transaction is committed, all data page changes will be written to the redo log. In comparison to flushing a constant number of data pages, writing to the redo log is much faster because sequentially accessing the disk is faster than random access. Hence, it makes transactions fast.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Examples of RDBMS
Following are the names of some prominent RDBMS:
- CUBRID
- Oracle Database XE
- MySQL
- SQLite (for mobiles)
- Sequel Pro
- MariaDB
- PostgreSQL
- SQL Server Express
- Db2 Express-C
- Firebird
Uses of RDBMS
Following are the common uses of RDBMS:
- Data Structure:
Relationally storing data enables the database users to easily understand it, and provides simple origination of and access to data. Similar kinds of data may be stored within a relation. - Concurrent access to multiple users :
RDBMS enables multiple users to simultaneously access a database. There exist inbuilt locking and transaction management mechanisms that allow these users to access data concurrently at which it also gets updated, thus preventing collisions between two users updating the data simultaneously, and also preventing users from accessing partially updated data. - Privileges:
Features such as authorization and privilege control in an RDBMS permit the database administrator to grant privileges to certain users and restrict access to unauthorized users, based on the types of operations they desire to perform upon the database. - Network Access:
An RDBMS provides access to a database through a server daemon. The server daemon is a special software program designed to listen for requests on a network and allows database clients to connect to a database and use it. Users need not necessarily physically log in to the computer system to be able to use the database, thus providing convenience to the users and security to the database. - Speed:
The relational model though is not the fastest data structure, but its benefits such as simplicity, compensate fairly for the slow speed. Optimizations embedded into an RDBMS combined with the design of the databases, enhance performance and allow the RDBMS to perform sufficiently fast enough for most applications and data sets. - Maintenance:
RDBMSs provide feature maintenance tools that provide database administrators with the means to easily test, maintain, backup, and repair the databases stored in the system. Many of these operations can be automated.
RDBMS Operators
1. SELECT :
Used for retrieving data from a database. Also supports filtering the retrieved data based on certain conditions.
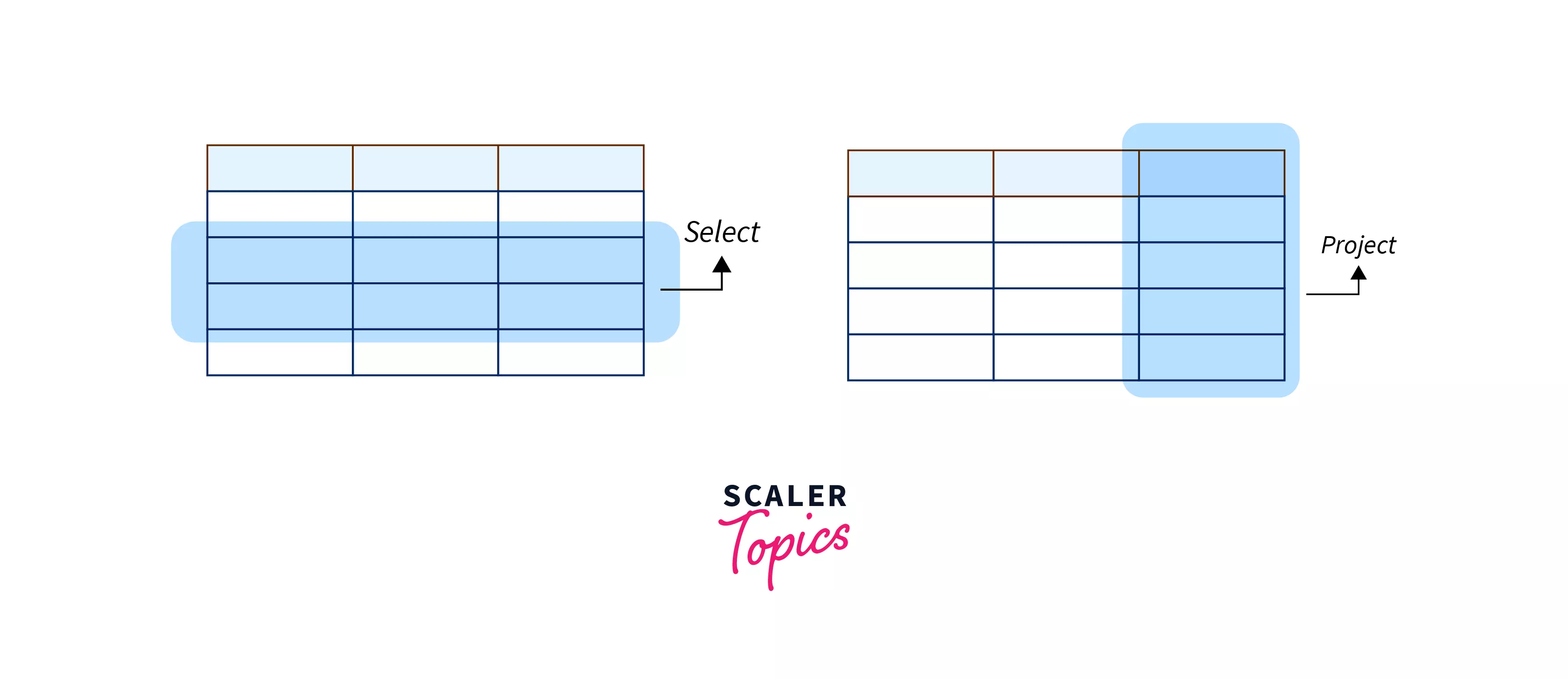
2. PROJECT :
Produces a list of all the values for a selected attribute.
3. JOIN :
Links two different relations together, resulting in the creation of a new table.
Following are the different types of joins:
-
Natural JOIN:
Links tables by selecting rows with common values in common attributes. It occurs in the following three stages :- The product creates a table.
- Select yields appropriate rows.
- The project yields a single copy of each attribute to eliminate duplicate columns.
-
Equi JOIN:
Links tables based on equality conditions that compare specified attributes of tables. -
Theta JOIN
A version of Equi Join that compares specified attributes of every table using some operator other than equality. -
Outer JOIN:
Matched pairs are retained and unmatched values in other tables are left null. They’re of two types: right and left.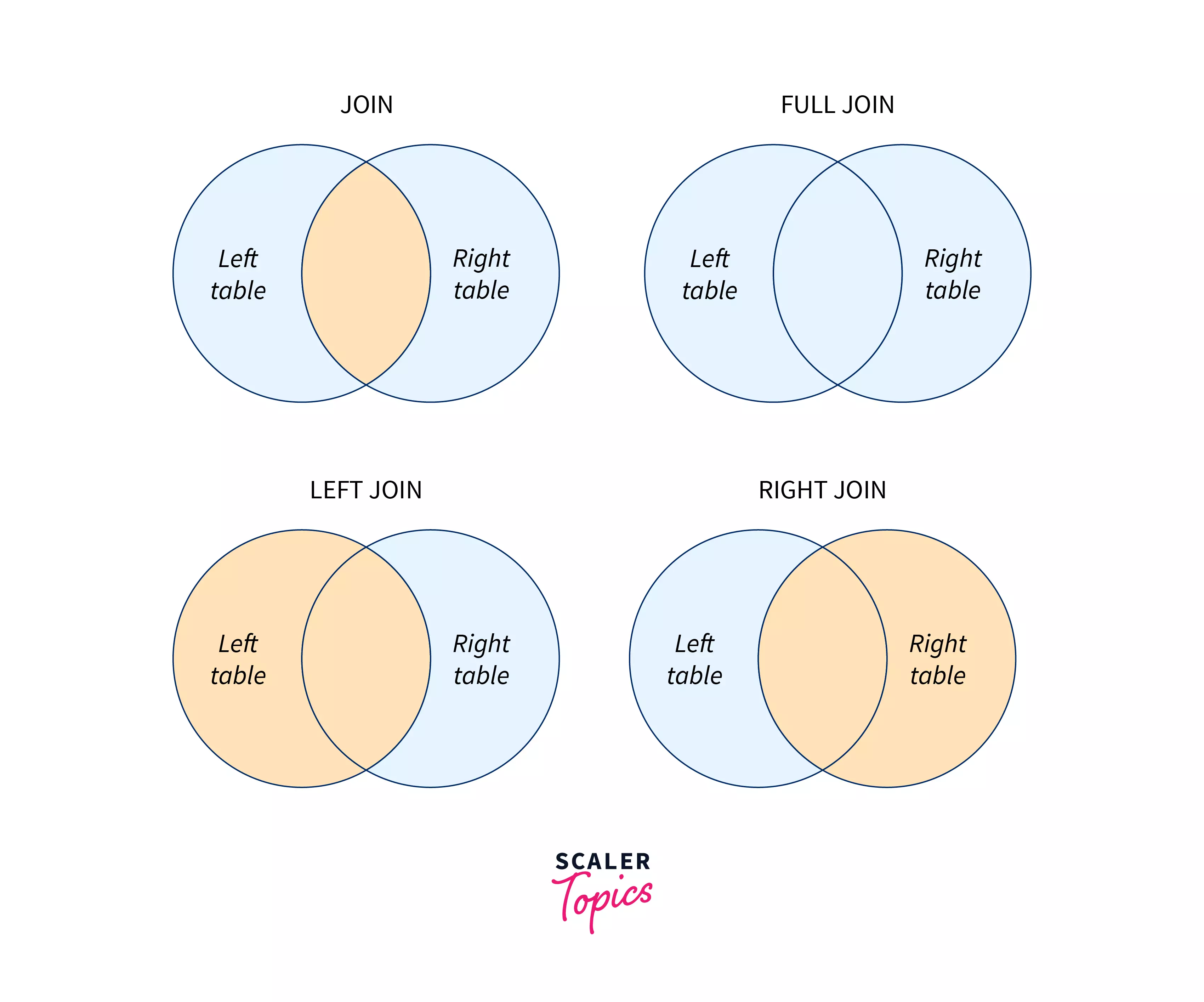
How are RDBMS Structured?
A relational database includes:
- System catalog:
Tables that describe the physical conceptual structure of the data. - Configuration file:
Contains the parameter values allocated for the database. - Recovery log:
Contain informational records about all transactions.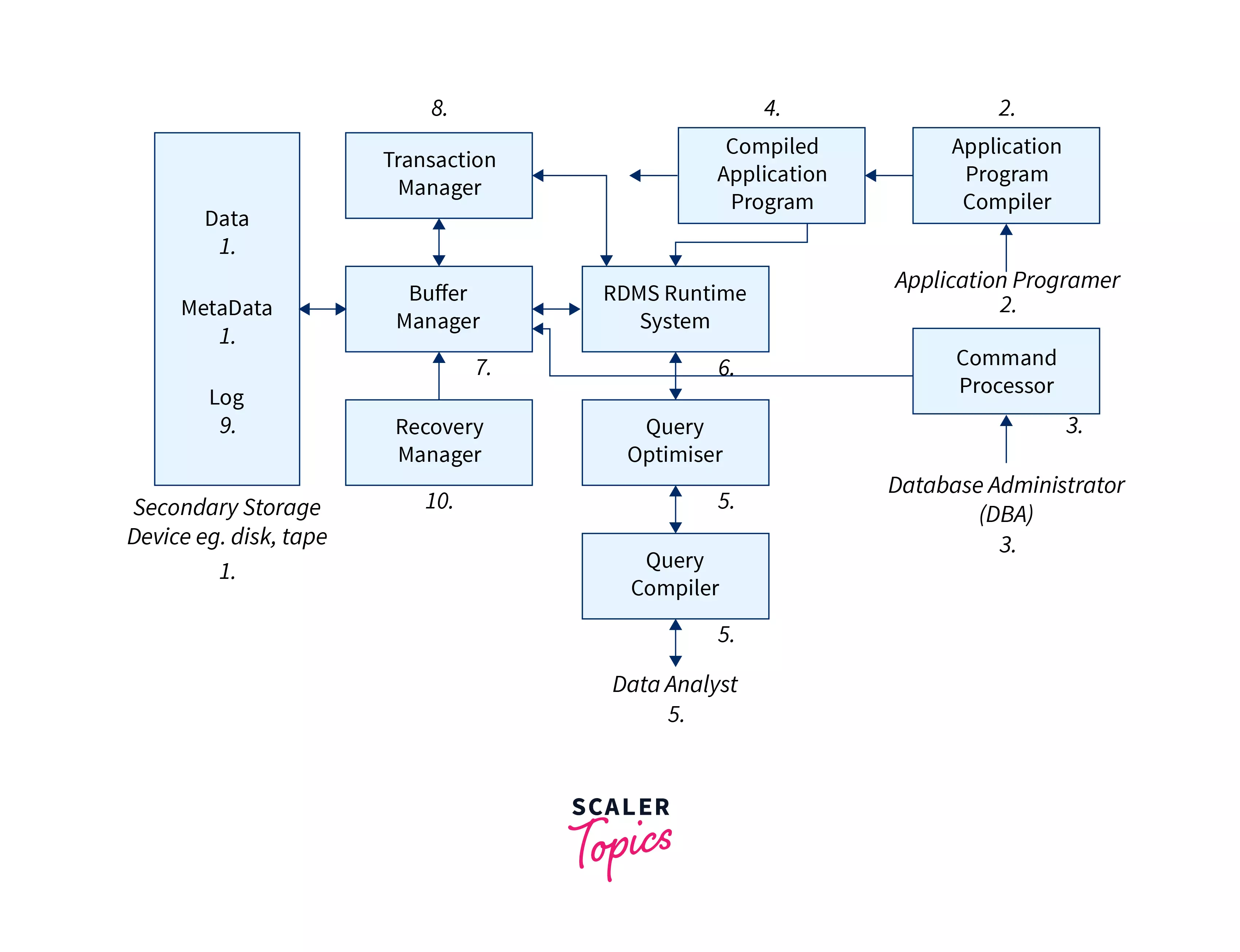
What is a Table/Relation?
In a relational database management system, a relation also referred to as a table, is a collection of data elements organized in a tabular form of rows and columns. Generally saying, a table may have duplicate data rows, while a true relation strictly prohibits having any such duplicity. The table is the simplest form of data storage.
Following is an example:
| ID | NAME | AGE | Salary |
|---|---|---|---|
| 1 | Adam | 34 | 13000 |
| 2 | Alex | 28 | 15000 |
| 3 | Stuart | 20 | 18000 |
| 4 | Ross | 42 | 19020 |
Properties of a Relation
The columns of a table represent the attributes/properties of an object. The rows of a table represent the values of different entries in relation, to different columns. Any row of any column can not have more than one value. There must not exist any duplicate rows in the same relation.
What is a Field?
Fields are the components of relationships that provide their structure. A table can not have zero fields, although a field may not have any value. Fields maintain relationships among tables, by creating matching fields in multiple tables. When creating a table or adding fields to an existing table, one defines the data type used for storing the data in each field. Occasionally, you may even mention the length of the field.






What is a Row/Record?
A row is also called a record. It is used for storing the value of a column for a particular instance (item). There might exist any number of rows as well as columns in a table.
Properties of a Row
Rows store values for columns. There should not exist any duplicate rows in a common relation. Different business objects may have different values for each column. Therefore we represent such as an object with a row.
What is a Column/Attribute?
A column is also referred to as an attribute. An attribute represents some property of an item, i.e. a table. Suppose we wish to create a table for storing information about cars. We will have to include the various properties of a car, such as color, number of wheels, brand name, etc. Each of these properties is represented in relation by relation with the help of attributes, or columns.
Properties of an Attribute
No two columns in the same relation should be the same. Different words store the values of a particular column for different business objects.
Attributes are also used for forming different types of keys in a relational database.
What is Data Item/Cells?
In a relation, data is present in tabular form, accessed by rows and columns. Each possible valid combination of a row and column in a relation, say (i, j) points to a cell. In a cell may be stored the value from a certain record, of a certain attribute.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Degree
The degree of a relation represents the number of entity types associated with the relation. For instance, suppose we have two entities, one is a child and the other is a toy and they are connected with the primary key and foreign key. Therefore the degree of this relationship is 2 since a total of 2 entities are associated in the relationship.
Types of Degree
Based on the number of linked entity types, the following are the four kinds of degrees of a relationship :
- Unary
- Binary
- Ternary
- N-ary
Cardinality
Cardinality represents the number of times an entity from an entity set participates in a relationship set. Or we restate the definition of cardinality as, the number of tuples in a relationship. Following are the 4 kinds of cardinalities in a relation :
- One-to-one
- One-to-many
- Many-to-one
- many-to-many
Domain
It is a unique set of values allowed for an attribute in a table. For instance, a domain of days_in_week will accept Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, and Sunday as possible values.
NULL Values
A row may have no value set for a column. This absolute absence of an entry is known as a NULL value. It is to be noted that empty strings, zero, false, etc do not evaluate to null.
Data Integrity
Data integrity is the overall reliability, completeness, and accuracy of data. It may be specified by the lack of variation between two consecutive updates of a record. This implies that the information is correct and error-free. Data integrity also includes security and integrity controls and methods of regulatory compliance.
Data integrity is maintained by a list of validation and error-checking methods, principles, and rules exercised during the integration flow designing phase. These procedures are based on predefined business rules. The significance of preserving data integrity is when establishing relationships between disparate data elements, ensuring that the data sent from one stage to another is error-free and accurate.
Index in RDBMS
Indexing is used to optimize the performance of an RDBMS by minimizing the number of disk accesses required while query processing. An index is a data structure for quickly locating and accessing the data in a database. An index is created using two database columns.
The first column is the Search key and consists of a copy of the candidate key or the primary key of the relation. These values stored are sorted so that their corresponding data can be accessed quickly, although the data may not necessarily be stored sorted. The other column is for data referencing. It is a set of pointers, each of which holds the address of the disk block in which the particular key value should be found.
RDBMS Normalization
Normalization is A procedure for minimizing redundancy in a table. Redundancy in a table may cause deletion, update, and insertion anomalies. There are 5 levels of normalization, namely, 1nf, 2nf, 3nf, 4nf, and 5nf.
Turn Learning into Career Growth
The Relational Model in RDBMS
The relational model in DBMS is an abstract model used to organize and manage the data stored in a database. It stores data in 2-dimensional inter-related tables, also known as relations in which each row represents an entity and each column represents the properties of the entity.
For further information on this topic have a look at this article on Scaler Topics.
RDBMS Extensions and Intensions
The extension of a relation is the set of rows appearing at any given instance in that relationship and thus varies with time. An extension thus changes as tuples are created, updated, and destroyed.
Following is an example :
Employee relation at t1 time :
| EmpNo | EmpName | Age | Dept |
|---|---|---|---|
| 1000 | Jacob | 22 | SE |
| 1001 | William | 23 | Fin |
| 1002 | Jon | 24 | HR |
| 1003 | Harrold | 19 | Fin |
Employee relation at t2 time after more records are added :
| EmpNo | EmpName | Age | Dept |
|---|---|---|---|
| 1000 | Jacob | 22 | SE |
| 1001 | William | 23 | Fin |
| 1002 | Jon | 24 | HR |
| 1003 | Harrold | 19 | Fin |
| 1005 | Smith | 26 | SD |
| 1006 | Maria | 24 | FIN |
| 1007 | Cyrus | 25 | HR |
Employee relation at time = t2 after further adding records :
| EmpNo | EmpName | Age | Dept |
|---|---|---|---|
| 1000 | Jacob | 22 | SE |
| 1001 | William | 23 | FIN |
The intension of a relation is not dependent on time and is a permanent part of the relation corresponding to what is specified in the schema of the relation. All permissible extensions are hence defined by an intention. An intention comprises of the following two things: a set of integrity constraints, and a structure.
The structure contains the relation name and the names of the columns. The integrity constraints are divided into referential constraints, key constraints, etc.
For instance :
This is the intention of the Employee relation.
Advantages of RDBMS
- Easy to use.
- It is secure.
- Data stored can be updated.
- Limits redundancy and replication of the data. RDBMS offers data integrity and better physical data independence.
- It offers logical database independence.
- RDBMS provides backup and recovery procedures and multiple interfaces.
- Multiple users may access a database in the relational model.
Disadvantages of RDBMS
- RDBMS software is expensive, complex, and increases the overall cost of using a DBMS.
- The operation of an RDBMS requires skilled human resources.
- Certain applications using RDBMS are slow in processing.
- In RDBMS, it is difficult to recover the lost data.
SQL Constraints
Constraints in SQL are the rules that we apply to the data types in a relation. We can specify the limit on the type of data that can be stored in a particular column in a table using these SQL constraints.
Following are the five constraints in SQL:
- NOT NULL:
It restricts the relationship to not store a null value in a particular column. - UNIQUE:
When specified with a column, UNIQUE tells that all the values in the column have to be unique. - PRIMARY KEY:
Among all candidate keys, a key is chosen to be the primary key. The primary key is used for virtually connecting one relation with another. - FOREIGN KEY:
The primary key of the first relation will be exactly a copy of the foreign key, in terms of name, data types, and other characteristics. Now using the primary key from the first relation we can address the attributes in the other relation as if they were both a single relation. - CHECK:
This constraint is used for validating the values of an attribute to satisfy a certain condition. - DEFAULT:
This constraint puts a default value for the specific attribute when no value is given by the user.
ACID Properties and RDBMS
Relational DBMS follows ACID properties, which are as follows :
Atomicity
Either a transaction completes successfully, or it does not execute at all.
Consistency
The state of data in a database remains the same before and after a transaction.
Isolation
Many transactions occur simultaneously, independent of each other, and without producing any interventions in each other.
Durability
The changes produced by a transaction reflect and persist in the database, even in the event of a failure occurring related to power, system, connectivity, etc.
The Relational Database of the Future: The Self-Driving Database
A database must store crucial information, essential for the efficient operation of a project. If the database is not protected, it might be subject to breaches, if it is slow and unavailable, it would not be of much use. This is self-driving (autonomous) databases come into the picture.
A self-driving DBMS is cloud-based and uses techniques such as AI to eliminate the manual effort required for database updates, tuning, backups, security, and other routine management tasks traditionally performed by database administrators.
Key Factors to Consider While Selecting an RDBMS
The most highly recognizable relational database management software is MySQL, which offers one of the most advanced and comprehensive features found in data management tools. It also provides users with one of the highest levels of security, scalability, uptime, and reliability.
Often termed as the most powerful RDBMS, the open-source PostgreSQL complies with the ACID properties . Postgres focuses on extensibility and has high reliability in storing data securely and returning it as a response to requests from other application software.
SQLite is a lightweight file-based embedded relational database management system that unlike most other RDBMS does not require its process, clustering, or user management. What makes SQLite lightweight while at the same time also retaining its relational power is that it uses an in-process compact library, which implements a serverless, self-contained, zero-configuration, and transactional SQL database engine.
An open-source, free, fully operational, and transactional database management solution for modern software development and enterprise use cases is MySql. The original MySql developers created MariaDB as a fork of the MySQL RDBMS after Oracle acquired MySQL in . MariaDB offers more database engines than MySQL itself does, for instance, BLACKHOLE, MyISAM, MEMORY, CSV, MERGE, etc. MariaDB’s backward compatibility is one of its strongest pros as a binary drop-in replacement for MySQL.
RDBMS vs DBMS
A DBMS is a software for systematically storing and managing data in a computer system. Examples, are MySql, MongoDB, etc. RDBMS is a specialized class of DBMS that is based on the concept of relational modeling.
Example: PostgreSQL, MariaDB, etc.
Learn More
Conclusion
- RDBMS is a class of Database Management systems that emphasizes the relationships among data objects.
- Needs of RDBMS:
data safety, fault tolerance, concurrent access, ease of use, scalability, indexing. - Examples of RDBMS:
MySQL, SQLite, MariaDB, PostgreSQL, SQL Server Express, Firebird, etc. - A relational database offers data consistency as it follows the ACID principles.
- A self-driving DBMS is cloud-based and uses techniques such as AI to eliminate the manual effort required for database updates, tuning, backups, security, and other routine management tasks traditionally performed by database administrators.