Types of Big Data
Overview
In today's digital age, as organizations collect and process massive amounts of data, the need for effective management and analysis of big data becomes essential. Big data can be categorized into various types, each presenting its features, use cases, and challenges. In this article, we will explore into the different types of big data – structured, unstructured, and semi-structured – and compare their characteristics and applications.
What is Big Data?
Big Data refers to the enormous volume of data that is generated, processed, and analyzed to achieve business intelligence. It encompasses both the data itself and the technologies used to handle and extract valuable insights from it. To gain a complete understanding of big data, it's essential to explore its various features and types of big data and how they contribute to data science. To learn more about the basics of big data, you can explore the article on Big Data.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Types of Big Data
Big data can be broadly classified into three main types:
- Structured data
- Semi-structured data
- Quasi-structed data
- Unstructured data
Structured Data
- Structured data is one of types of big data, characterized by its organized and systematic format.
- Structured data is defined as a clear framework, typically represented in tables, rows, and columns.
- Suitable for traditional database systems and facilitates efficient storage, retrieval, and analysis.
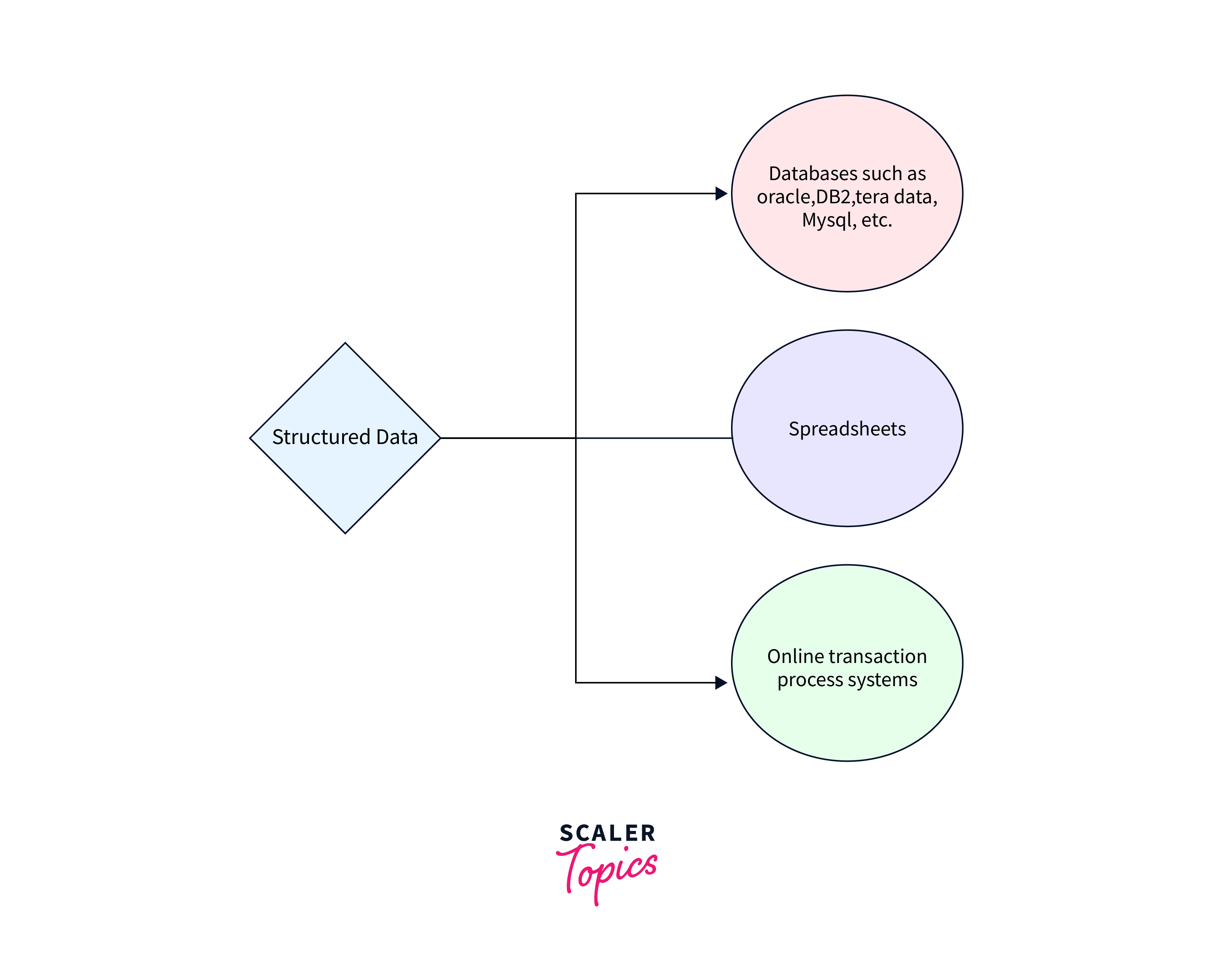
Examples:
- Tables in relational databases.
- Spreadsheets.
- Formated Dates or Time and information like account numbers.
Merits:
- The organized format helps to define data fields and establish relationships for efficient retrieval.
- Structured query languages (SQL), enable precise and rapid querying which accelerates data analysis.
- Promotes data consistency and accuracy while minimizing errors and discrepancies that could arise during data entry or processing.
- Seamless data migration between systems and platforms, allowing interoperability and integration across diverse applications.
- Quantitative analysis, statistical calculations, and aggregation are easier with structured data.
Limitations:
- Rigidity: The predefined structure can be limiting when dealing with complex, dynamic, or evolving data types.
- Data Loss: The structured approach might force oversimplification, leading to the omission of potentially valuable information and overlooking fine grained detail.
- Scalability Challenges: As data volumes grow exponentially, maintaining the structural integrity while scaling of data becomes increasingly challenging due to performance bottlenecks.
Semi-Structured Data
- Semi-structured data is one of the types of big data that represents a middle ground between the structured and unstructured data categories.
- It combines elements of organization and flexibility, allowing for data to be partially structured while accommodating variations in format and content.
- This type of data is often represented with tags, labels, or hierarchies, which provide a level of organization without strict constraints.
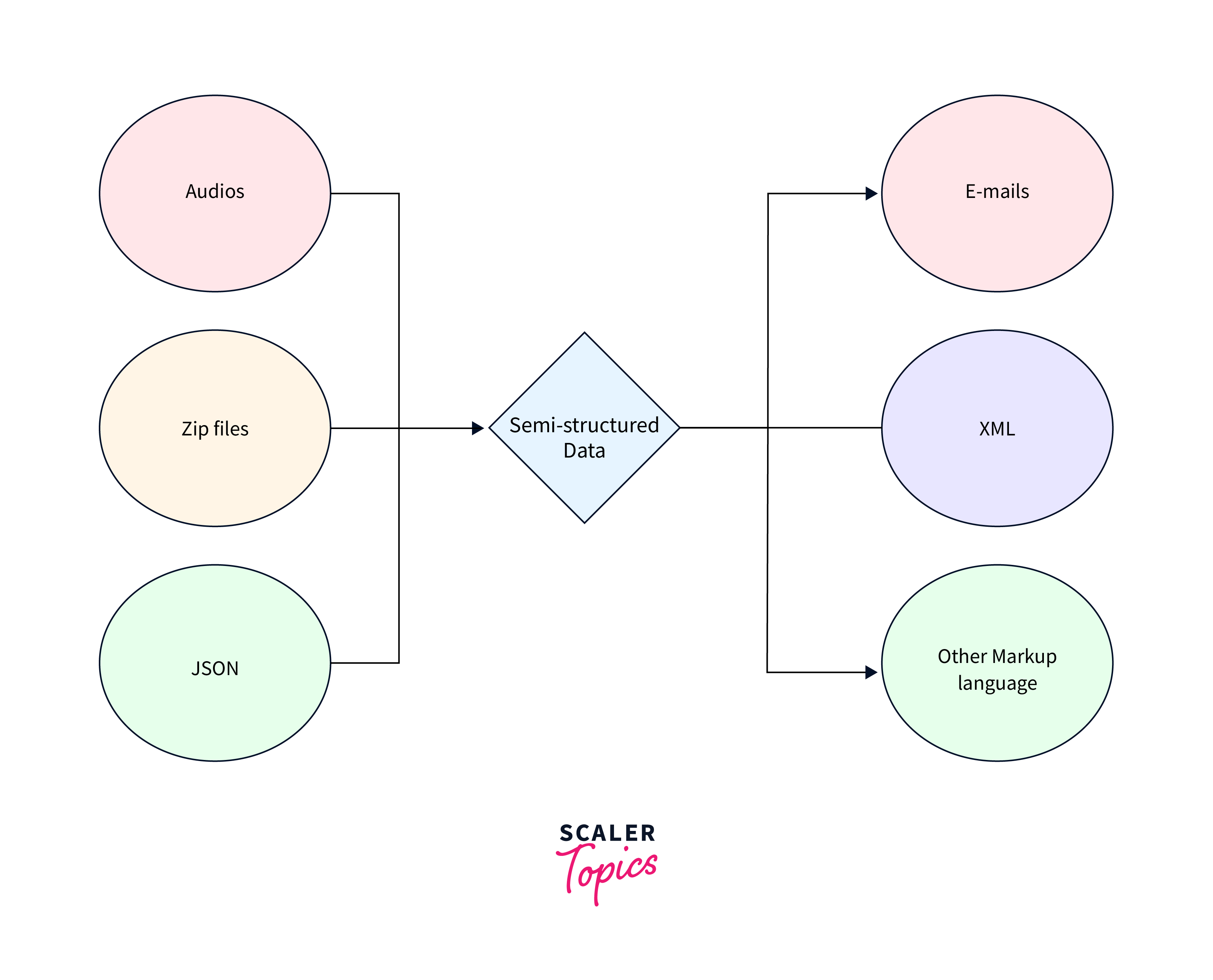
Examples:
- XML Documents
- JSON Data
- NoSQL Databases
Merits:
- Semi-structured data is flexible and can represent complex relationships and hierarchical structures. It can accommodates changes to data formats without requiring major alterations to the underlying processing systems.
- Semi-structured data can be stored in ways that optimize space utilization and retrieval efficiency.
Limitations:
- Data Integrity: The flexible nature of semi-structured data can lead to issues related to data integrity, consistency, and validation.
- Query Complexity: Analyzing and querying semi-structured data might require more complex and specialized techniques compared to structured data.
- Migration: Migrating or integrating semi-structured data across different systems can be challenging due to variations in data representations and semantics.
Turn Learning into Career Growth
Quasi-structured Data
- Quasi-structured is one of the types of big data that occupies a unique space between structured and unstructured data types, introducing a degree of order while maintaining a level of flexibility.
- Quasi-structured data has some consistent patterns while allowing for variations in content.
- This data type is commonly encountered in various digital formats, requiring specialized approaches for effective management and analysis.
Examples:
- Email headers
- Log files
- Web scraped data.
Merits:
- Quasi-structured data is flexible, allowing for a more comprehensive representation of real-world scenarios.
- Analyzing quasi-structured data can benefit from automation techniques, such as pattern recognition, while still accommodating control for varying content.
- Quasi-structured data approaches can handle evolving data formats without requiring drastic changes to storage or processing systems.
Limitations:
- Data Integration: Integrating quasi-structured data from various sources can be complex due to variations in patterns and formats.
- Querying Complexity: Quasi-structured data may require specialized querying techniques, striking a balance between structured and unstructured querying methods.
- Data Validation: Ensuring data integrity and validation can be challenging due to the mix of structured and unstructured elements.
Unstructured Data
- Unstructured data is one of the types of big data that represents a diverse and often unorganized collection of information.
- It lacks a consistent structure, making it more challenging to organize and analyze.
- This data type encompasses a wide array of content, including text, images, audio, video, and more, often originating from sources like social media, emails, and multimedia platforms.
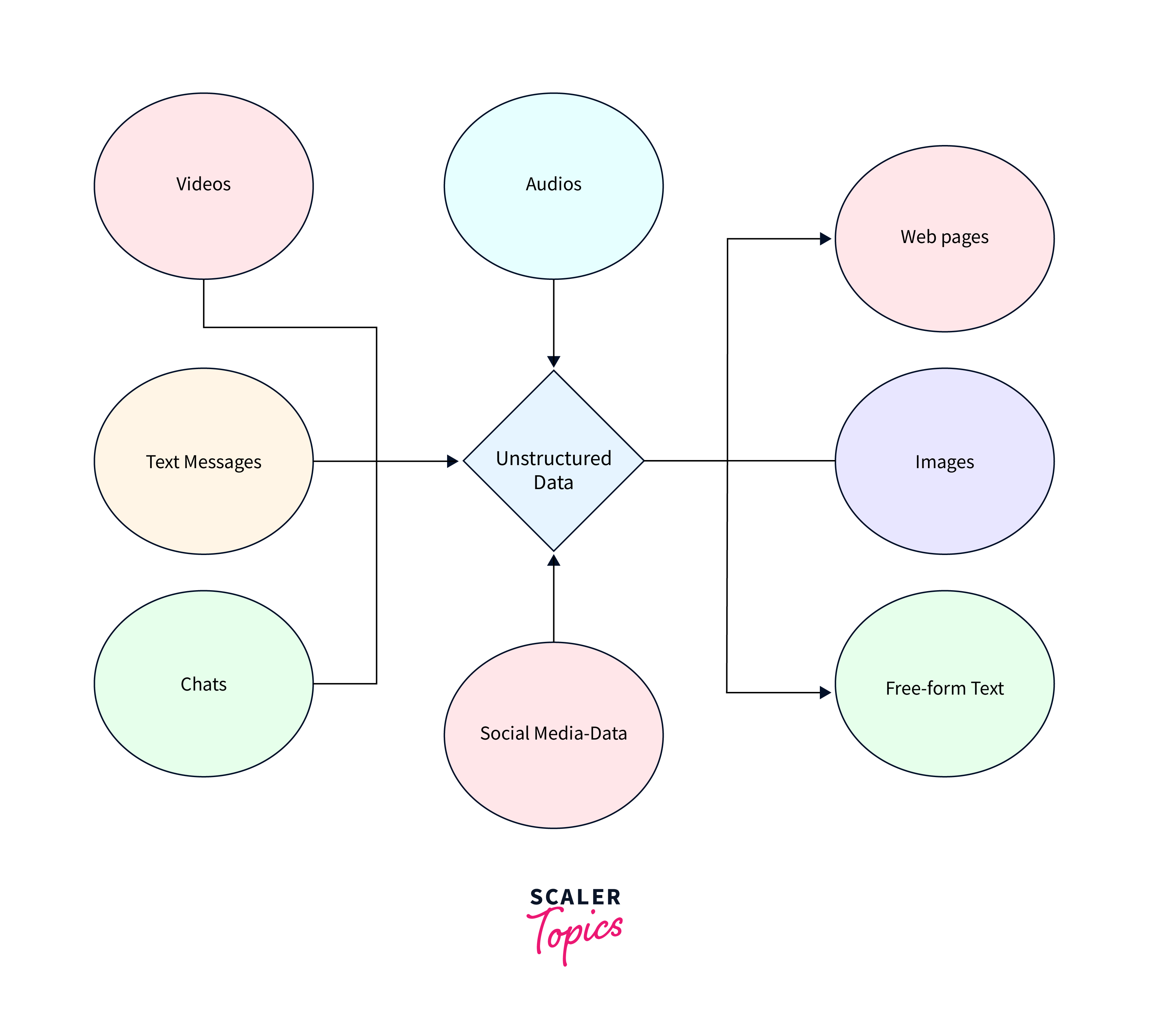
Example:
- Social media posts data.
- Customer reviews and feedback, found on e-commerce platforms, review sites, and surveys.
- Medical images, such as X-rays, MRIs, and CT scans, are examples of unstructured data.
Merits:
- Unstructured data can capture more information and qualitative aspects that structured data might overlook.
- The diverse nature of unstructured data mirrors real-world scenarios more closely, and can be valuable for decision-making and trend analysis.
- Unstructured data fuels innovation in fields like natural language processing, image recognition, and machine learning.
Limitations:
- Data Complexity: The lack of a predefined structure complicates data organization, storage, and retrieval.
- Data Noise: Unstructured data can include noise, irrelevant information, and outliers.
- Scalability: As unstructured data volumes grow, managing and processing this data becomes resource-intensive.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Compare Structured vs Unstructured vs Semi-Structured
Structured data, unstructured data, and semi-structured data are the types of big data each with their strengths and weaknesses.
- Structured data provides order and efficiency in processing, making it suitable for well-defined tasks and analysis.
- Unstructured data offers a wealth of insights from diverse sources, albeit with challenges in extraction and interpretation.
- Semi-structured data strikes a balance, offering flexibility and organization for complex data models.
The following tabulation compares the three types of big data:
| Aspect | Structured Data | Unstructured Data | Semi-Structured Data |
|---|---|---|---|
| Definition | Organized | Lack of predefined structure | Mix of organization and flexibility |
| Examples | Sales transactions in a relational database, student records in spreadsheets. | Social media posts, customer reviews, medical images, and audio recordings. | XML documents, JSON data, NoSQL databases. |
| Storage Efficiency | Efficient storage and retrieval due to organized format. | Varied storage efficiency based on content types, can be challenging to manage. | Balances storage efficiency with flexibility, optimized for complex data structures. |
| Querying | Well-suited for structured query languages (SQL), efficient querying. | Challenging for querying, requires advanced techniques like natural language processing. | Requires specialized querying techniques, adaptable to complex relationships. |
| Data Complexity | Well-organized and straightforward to manage. | Chaotic and challenging to organize due to lack of structure. | Balances flexibility with some level of organization, and moderate complexity. |
| Flexibility | Limited flexibility, data must adhere to a predefined structure. | Highly flexible, can capture diverse content, but may lack uniformity. | Offers flexibility while maintaining some level of structure, adaptable to changes. |
| Integration | Well-suited for traditional relational databases and structured applications. | May require advanced integration techniques due to diverse formats. | Adaptable for web applications, APIs, and systems with varying data sources. |
| Analysis Difficulty | Easier to analyze, suitable for quantitative analysis and reporting. | Requires advanced techniques for sentiment analysis, pattern recognition, etc. | Complex analysis may involve specialized techniques but accommodates diverse structures. |
| Scalability | Efficient for managing large volumes due to structured format. | Scalability challenges due to data diversity and potential noise. | Scalable, but complexity might increase with data volume and structure. |
Conclusion
- There are three main types of big data: structured, unstructured, and semi-structured.
- Structured Data is organized and formatted in predefined ways, while offering efficient storage, querying, and insights for quantitative analysis, making it well-suited for traditional databases and reporting.
- Semi-Structured Data combines organization and flexibility, accommodating complex data models which is perfect for modern web applications.
- Quasi-Structured Data provides variations in content in consistent patterns structure.
- Unstructured Data lacks a predefined structure and contains diverse content that provides rich insights, but can be challenging to organize and query.