Understanding Large Language Models: How They Are Shaping the Future of AI
What is a large language model? A large language model (LLM) is an advanced artificial intelligence system built on concepts you master when you learn deep learning, specifically transformers. Trained on massive text datasets, a large language model predicts and generates human-like text by learning complex statistical patterns, semantics, and syntactic structures.
Introduction to Large Language Models
The landscape of artificial intelligence has been fundamentally transformed by the advent of the large language model. For decades, natural language processing (NLP) relied on heavily engineered, rule-based systems or smaller statistical models that struggled to grasp the nuance and context of human language. The modern large language model bypasses these limitations through raw scale—utilizing billions or even trillions of parameters—and unsupervised learning over vast corpuses of human knowledge.
When engineers and computer science students ask, "what is large language model architecture based on?", the answer invariably points to the attention mechanism and the transformer topology. These models do not "understand" language in a sentient manner; rather, they perform highly sophisticated next-token prediction. By calculating the probability distribution of a subsequent word given the preceding context, a large language model can translate code, summarize research, and generate coherent architectural system designs. Understanding the internal mechanics of these models is no longer optional for anyone exploring what is ai engineering—it is a foundational requirement for building the next generation of intelligent, scalable applications.
Stop learning AI in fragments—master a structured AI Engineering Course with hands-on GenAI systems with IIT Roorkee CEC Certification
AI Engineering Course Advanced Certification by IIT-Roorkee CEC
A hands on AI engineering program covering Machine Learning, Generative AI, and LLMs - designed for working professionals & delivered by IIT Roorkee in collaboration with Scaler.
Enrol Now
The Historical Evolution of Language Models
To fully contextualize the power of a modern large language model, one must examine the evolutionary trajectory of NLP systems. Early iterations of language modeling relied on n-grams, which predicted the next word based purely on the frequency of the preceding 'n' words. These models suffered from data sparsity and an inability to maintain long-term dependencies. As neural networks gained traction, Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks became the industry standard.
LSTMs introduced a hidden state that could carry information across sequence steps, mitigating the vanishing gradient problem inherent in standard RNNs. However, RNNs and LSTMs process data sequentially. This architectural bottleneck prevented large-scale parallelization during training, restricting the size of the datasets and the parameter counts these models could effectively utilize.
The paradigm shifted entirely in 2017 with the publication of "Attention Is All You Need" by Vaswani et al., which introduced the Transformer architecture. By eliminating recurrence and relying entirely on attention mechanisms, the Transformer allowed for the parallel processing of entire sequences. This specific breakthrough enabled the scaling laws that define today's large language model ecosystem.
| Feature | RNN / LSTM | Transformer-Based Large Language Model |
|---|---|---|
| Processing Mechanism | Sequential (token by token) | Parallel (entire sequence simultaneously) |
| Context Retention | Degrades over long distances (Vanishing Gradient) | Maintained via Global Self-Attention |
| Hardware Utilization | Poor (hard to parallelize on GPUs) | Excellent (highly optimized for GPU matrix multiplication) |
| Parameter Scalability | Limited (typically millions of parameters) | Massive (billions to trillions of parameters) |
Core Architectural Components
The underlying architecture of a large language model dictates its capability to process context, follow instructions, and generate syntactically correct outputs. Most contemporary LLMs rely on the Transformer architecture, which can be configured in three primary ways: encoder-only (e.g., BERT), encoder-decoder (e.g., T5), and decoder-only (e.g., the GPT series). Modern generative large language models are almost exclusively decoder-only, optimized for autoregressive text generation. In these systems, the model generates output one token at a time, appending the newly generated token to the input sequence before predicting the next.
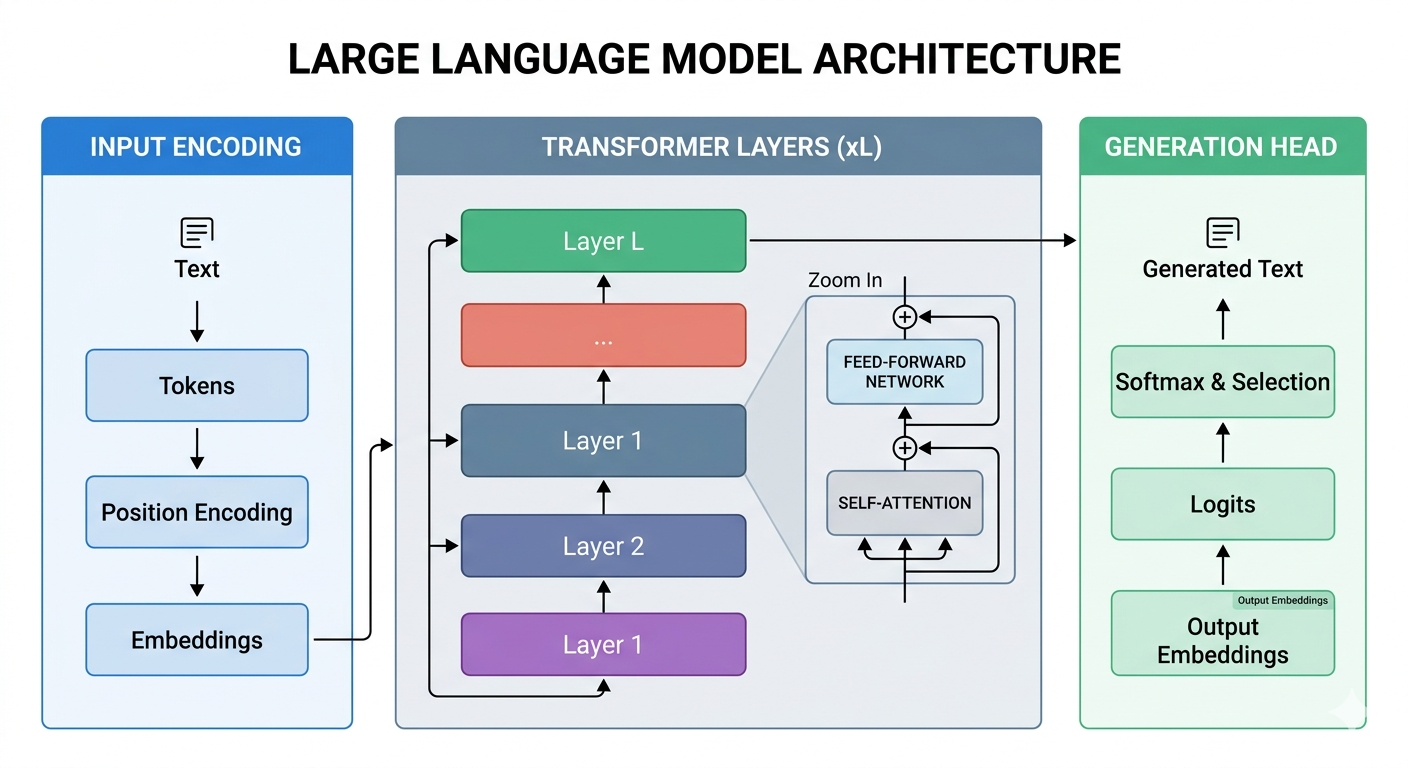
Self-Attention Mechanism
The self-attention mechanism is the mathematical engine that allows a large language model to weigh the importance of different words in a sequence relative to one another, regardless of their positional distance. For each token in a sequence, the model creates three distinct vectors: a Query (Q), a Key (K), and a Value (V). These vectors are generated by multiplying the input embeddings by learned weight matrices (Wq, Wk, Wv).
The attention score is computed by taking the dot product of the Query vector of the current token with the Key vectors of all tokens in the sequence. To prevent the dot products from growing excessively large and pushing the softmax function into regions with extremely small gradients, the results are scaled by the square root of the dimension of the key vectors (√dk). Finally, a softmax function is applied to yield the attention weights, which are multiplied by the Value vectors.
The mathematical representation of this operation is: Attention(Q, K, V) = softmax((Q K^T) / √dk) V
Because decoder-only models must not look ahead at future tokens during training (as they are autoregressive), a masking matrix is applied to the upper triangle of the attention scores before the softmax operation. This is known as Masked Multi-Head Attention.
Multi-Head Attention and Feed-Forward Networks
Instead of calculating a single attention distribution, a large language model utilizes Multi-Head Attention. The Q, K, and V matrices are projected into multiple lower-dimensional subspaces ("heads"). Each head calculates its own attention mechanism independently, allowing the model to focus on different linguistic phenomena simultaneously—for instance, one head might track subject-verb agreement, while another tracks pronouns back to their proper nouns.
The outputs of all heads are concatenated and passed through a linear layer. Following the attention mechanism, the data passes through a position-wise Feed-Forward Network (FFN), which applies non-linear transformations (commonly using activation functions like GeLU or SwiGLU) to expand the model's representational capacity.
Below is a conceptual PyTorch implementation of a scaled dot-product attention block:
Become the Ai engineer who can design, build, and iterate real AI products, not just demos with an IIT Roorkee CEC Certification
AI Engineering Course Advanced Certification by IIT-Roorkee CEC
A hands on AI engineering program covering Machine Learning, Generative AI, and LLMs - designed for working professionals & delivered by IIT Roorkee in collaboration with Scaler.
Enrol NowScaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Data Acquisition and Preprocessing
A large language model is only as robust as the data upon which it is trained. The massive parameter counts of these models require petabytes of textual data to achieve optimal convergence. This data is typically scraped from the public internet, encompassing web pages, academic journals, code repositories, and digitized books. However, raw internet data is highly unstructured, noisy, and rife with low-quality content, toxic language, and redundant information.
Consequently, dataset preprocessing is arguably the most critical engineering phase in the development of a large language model. The pipeline involves aggressive filtering, deduplication, and tokenization. A poorly preprocessed dataset leads directly to degraded model performance, hallucination loops, and catastrophic memorization, where the model outputs exact replicas of its training data rather than generalizing.
Data Filtering and Deduplication
The first step in curating a dataset for a large language model is filtering. Engineers use heuristic rules (such as removing documents with excessive HTML tags, non-standard character distributions, or uncharacteristically short text lengths) alongside machine learning classifiers designed to filter out spam and toxic content.
Deduplication is equally vital. Web data is incredibly repetitive. Training a model on duplicated data artificially inflates the statistical probability of specific phrases, causing the model to overfit. Deduplication occurs at two levels:
- Exact Match Deduplication: Removing identical documents using cryptographic hashing (e.g., SHA-256).
- Fuzzy Deduplication: Utilizing algorithms like MinHash and Locality-Sensitive Hashing (LSH) to identify and remove documents that are structurally similar but not perfectly identical.
Tokenization
Before text can be ingested by a neural network, it must be converted into numerical representations. Tokenization is the process of breaking down raw text into manageable sub-word units called tokens. Rather than using word-level tokenization (which results in massive, unmanageable vocabularies) or character-level tokenization (which fails to capture semantic meaning efficiently), a modern large language model employs sub-word tokenization algorithms.
Byte-Pair Encoding (BPE) is the most prevalent algorithm. BPE starts with a vocabulary of individual characters or bytes and iteratively merges the most frequently adjacent pairs into a single new token. This process continues until a predefined vocabulary size (typically between 32,000 and 128,000 tokens) is reached. This approach allows the large language model to represent common words as single tokens while gracefully handling rare words or out-of-vocabulary terms by breaking them down into known sub-word components.
Training Processes of a Large Language Model
Training a large language model involves immense computational resources, often requiring clusters of thousands of GPUs running continuously for months. The process is not a single, monolithic run; rather, it is divided into distinct, sequential phases. Each phase serves a specific purpose, transitioning the model from a raw statistical engine that blindly predicts text into a refined, aligned tool capable of obeying complex user instructions and maintaining safety boundaries.
The optimization during training relies on backpropagation and stochastic gradient descent variants, predominantly the AdamW optimizer. Due to memory constraints, techniques like Fully Sharded Data Parallel (FSDP) or DeepSpeed Zero Redundancy Optimizer (ZeRO) are employed to partition model states (optimizer states, gradients, and parameters) across multiple GPUs.
The Pretraining Phase
Pretraining is the most resource-intensive phase of developing a large language model. During this stage, the model initializes with random weights and is exposed to the massive, deduplicated corpus of text. The objective is self-supervised causal language modeling: the model attempts to predict token x_t given the context of tokens x_1 through x_{t-1}.
The model calculates a probability distribution over its entire vocabulary for the next token. The actual next token in the training data acts as the ground truth. The error between the model's prediction and the ground truth is quantified using Cross-Entropy Loss: L = - Σ y_i log(p_i) Where y_i represents the true distribution (a one-hot encoded vector of the actual next token) and p_i represents the model's predicted probability distribution.
Through trillions of these predictive iterations, the model implicitly learns the grammar, facts, reasoning capabilities, and coding syntax present in its training corpus. The output of this phase is a base model, directly answering what are foundation models in generative ai. While highly knowledgeable, a base model is difficult to interact with; if prompted with a question, it might simply generate more questions, as it has only learned to continue a sequence, not to answer queries.
Fine-Tuning and Alignment (SFT and RLHF)
To transform a base model into an interactive assistant, it undergoes alignment. This typically involves two sequential sub-phases:
- Supervised Fine-Tuning (SFT): The large language model is trained on a high-quality, human-annotated dataset consisting of prompt-response pairs. This teaches the model the specific format of human dialogue and instruction following.
- Reinforcement Learning from Human Feedback (RLHF): To further refine the model's output to align with human preferences (e.g., helpfulness, honesty, and harmlessness), RLHF is employed. First, a separate Reward Model is trained on human preference data, where human raters rank different model outputs. Then, the large language model is optimized using reinforcement learning algorithms, such as Proximal Policy Optimization (PPO), to maximize the scores generated by the Reward Model.
Recently, Direct Preference Optimization (DPO) has emerged as a mathematically elegant alternative to RLHF. DPO bypasses the need for a separate reward model by directly optimizing the language model's policy using the human preference data, significantly simplifying the alignment pipeline.
Inference and Deployment Strategies
Deploying a large language model into a production environment introduces a unique set of engineering challenges. Unlike traditional software applications, serving an LLM requires managing extreme memory bandwidth limitations and compute bottlenecks. Inference—the process of the model generating text in real-time—is memory-bound. As the model auto-regressively generates tokens, it must continually read its massive weight matrices from GPU memory to compute the next token, which heavily strains VRAM bandwidth.
Understanding inference optimization is vital for backend engineers integrating these models into commercial applications. Without sophisticated deployment strategies, latency becomes unacceptable, and the cost of GPU hosting becomes economically unviable.
Hardware Constraints and KV Caching
During text generation, the Transformer architecture must recalculate attention weights for every token. As the context window grows, this results in redundant mathematical operations, as the Keys (K) and Values (V) for preceding tokens do not change. To optimize this, deployment engines utilize a KV Cache. The engine stores the computed K and V tensors for all past tokens in GPU memory, drastically reducing compute requirements at the cost of VRAM footprint.
However, standard KV Cache allocation is highly inefficient due to memory fragmentation. Modern serving frameworks utilize PagedAttention, an algorithm inspired by virtual memory paging in operating systems. PagedAttention divides the KV Cache into fixed-size blocks that can be stored non-contiguously in VRAM, virtually eliminating memory fragmentation and allowing a single GPU to serve significantly more concurrent user requests.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Quantization and Optimization Techniques
To deploy a large language model on consumer hardware or to reduce cloud operational costs, engineers employ Quantization. Quantization reduces the precision of the model's numerical weights. A standard model utilizes 16-bit floating-point (FP16 or BF16) numbers. Quantization algorithms map these weights to lower precision formats, such as 8-bit integers (INT8) or even 4-bit integers (INT4).
Techniques like GPTQ (Generative Pre-trained Transformer Quantization) and AWQ (Activation-aware Weight Quantization) carefully compress the model while minimizing the loss of accuracy. By reducing precision, a model that once required 80GB of VRAM can be run entirely on a 24GB consumer GPU.
Evaluating a Large Language Model
Evaluating a large language model is a notoriously complex challenge. Because language is inherently open-ended and highly subjective, traditional metrics used in machine learning (like exact match accuracy or F1 scores) are often insufficient. Early NLP metrics like BLEU or ROUGE relied on exact n-gram overlap between the model's output and a reference text, which heavily penalized models that generated correct answers using different vocabulary.
Modern evaluation frameworks have shifted toward benchmarking on highly complex, standardized datasets that test distinct capabilities:
- MMLU (Massive Multitask Language Understanding): Tests the model's knowledge across dozens of academic and professional subjects, from physics to law, evaluating its zero-shot and few-shot accuracy.
- HumanEval: Developed by OpenAI, this benchmark tests the coding capabilities of a large language model. The model is given a Python function signature and a docstring, and it must generate the correct implementation. The code is then executed against hidden unit tests.
- LLM-as-a-Judge: A newer paradigm where a superior, highly capable model (such as GPT-4) is explicitly prompted to evaluate the output of a smaller model based on specific grading criteria like coherence, factual accuracy, and conciseness.
Applications and Use Cases
The highly adaptable nature of a large language model allows it to act as a foundational layer for countless downstream applications across software engineering, concepts from a data science course, and business operations. By utilizing techniques like In-Context Learning—where the model learns to perform a task simply by being shown examples in the prompt, without altering its internal weights—developers can rapidly prototype complex systems.
Key technical use cases include:
- Retrieval-Augmented Generation (RAG): LLMs are integrated with vector databases (like Pinecone or Milvus). When a user queries the system, the database retrieves relevant documents and injects them into the LLM's context window. This grounds the large language model in proprietary data, preventing hallucinations and ensuring up-to-date responses without retraining.
- Automated Code Synthesis and Refactoring: Integrated development environment (IDE) extensions utilize LLMs to turn prompts into code, autocomplete boilerplates, and translate codebases from deprecated languages to modern stacks, and automatically generate unit tests based on functional logic.
- Data Pipeline Automation: Large language models excel at unstructured data extraction. They are frequently deployed in ETL (Extract, Transform, Load) pipelines to parse raw JSON logs, emails, or PDF documents and output structured, queryable data formats.
Limitations and Interpretability
Despite their profound capabilities, the fundamental architecture of a large language model introduces several distinct limitations that engineers must account for when building enterprise systems. Chief among these is the propensity for "hallucinations"—instances where the model generates highly plausible but factually incorrect information. Because an LLM is optimizing for statistical likelihood rather than empirical truth, it lacks a grounded world model.
Furthermore, a large language model is limited by its context window. While modern models boast context sizes exceeding 100,000 tokens, the attention mechanism's computational complexity scales quadratically with sequence length. Although architectural tweaks like Ring Attention and Sparse Attention aim to mitigate this, long-context retrieval often suffers from the "lost in the middle" phenomenon, where the model effectively retrieves information from the very beginning or end of a prompt but ignores data buried in the center.
Finally, the interpretability of these systems remains an unsolved area of research in computer science. Known as "mechanistic interpretability," researchers are actively probing the billions of parameters within a large language model to understand exactly how internal logic gates fire to produce a given output. Currently, neural networks remain "black boxes." If a model outputs a biased or incorrect statement, developers cannot simply trace an execution path or look at a stack trace to debug the cognitive error, complicating strict compliance and safety guarantees in sectors like healthcare and finance.
FAQs
What is the difference between a large language model and a traditional search engine? A traditional search engine indexes existing web pages and uses algorithms like PageRank to retrieve information based on keyword matching and backlink authority. It points you to data. A large language model generates novel responses by computing the statistical probability of text based on its internal parametric memory, effectively synthesizing information rather than just retrieving it.
How does a large language model handle context windows? The context window is the maximum number of tokens (words or sub-words) an LLM can process in a single inference pass. The model uses positional encodings (like Rotary Position Embeddings - RoPE) to keep track of the order of words. If input exceeds the context window, the model cannot process it, and developers must use techniques like chunking or Retrieval-Augmented Generation (RAG) to manage the data.
What is zero-shot and few-shot prompting? Zero-shot prompting involves asking a large language model to perform a task without providing any prior examples of the expected output. Few-shot prompting provides the model with several examples (pairs of inputs and desired outputs) within the prompt itself. This leverages the model's in-context learning capabilities to significantly improve accuracy and enforce output formatting.
Can a large language model learn in real-time? No. Once the training process (pretraining and fine-tuning) is complete, the weights of a standard large language model are frozen. It does not update its internal knowledge base in real-time as it interacts with users. To give a model access to real-time information, engineers must utilize external tools, web scraping APIs, or vector databases (RAG architecture) during the inference phase.