What Are Foundation Models in Generative AI
What are foundation models in ?
Foundation models are large-scale artificial intelligence models trained on vast quantities of unlabeled data using self-supervised learning. Their massive parameter size and generalized knowledge base allow them to be fine-tuned or prompted for a wide variety of downstream generative tasks, effectively replacing isolated, task-specific models.
Generative artificial intelligence has undergone a paradigm shift. Historically, natural language processing (NLP) and computer vision required discrete models architected and trained explicitly for singular objectives—be it sentiment analysis, named entity recognition, or image classification. The introduction of foundation models fundamentally generative AI collapsed this pipeline. By establishing a shared baseline capable of achieving strong zero-shot and few-shot inference capabilities, foundation models serve as the underlying operating engine for modern applications.
To have foundation models explained technically, one must look beyond basic definitions and examine the systems engineering, distributed training paradigms, and neural network architectures that make them possible. This guide provides a comprehensive, rigorous examination of foundation models, exploring their architecture, training lifecycle, efficiency bottlenecks, and role in modern software engineering.
The Core Concept: Emergence and Homogenization
The term "foundation model" was popularized by the Stanford Institute for Human-Centered Artificial Intelligence (HAI) to describe a specific class of deep learning models characterized by two driving principles: emergence and homogenization.
Emergence refers to the phenomenon where model capabilities scale implicitly with parameter count and dataset size. Rather than explicitly programming a model to translate code from Python to C++, or to perform logical reasoning, these capabilities emerge organically as the model attempts to minimize its loss function over hundreds of billions of training tokens. By learning the statistical distribution and underlying syntax of its training data, the model develops generalized heuristics.
Homogenization refers to the consolidation of methodologies. Before foundation models, building a robust machine learning system required combining Convolutional Neural Networks (CNNs) for images, Recurrent Neural Networks (RNNs) for sequential text, and separate architectures for speech. Today, a unified architecture—predominantly the Transformer—can be applied across almost all data modalities, homogenizing the technological stack that AI engineers must maintain.
Architectural Foundations: How They Work
At the core of virtually every modern foundation model is a highly parallelizable neural network architecture. Understanding how these models scale to hundreds of billions of parameters requires a deep dive into the mechanisms that allow them to process sequential data efficiently without succumbing to the vanishing gradient problems that plagued earlier recurrent networks. The architecture must map high-dimensional input arrays into dense semantic vector spaces, compute relationships between varying inputs in parallel, and output probabilistic distributions that define the generated content.
Stop learning AI in fragments—master a structured AI Engineering Course with hands-on GenAI systems with IIT Roorkee CEC Certification
AI Engineering Course Advanced Certification by IIT-Roorkee CEC
A hands on AI engineering program covering Machine Learning, Generative AI, and LLMs - designed for working professionals & delivered by IIT Roorkee in collaboration with Scaler.
Enrol Now
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
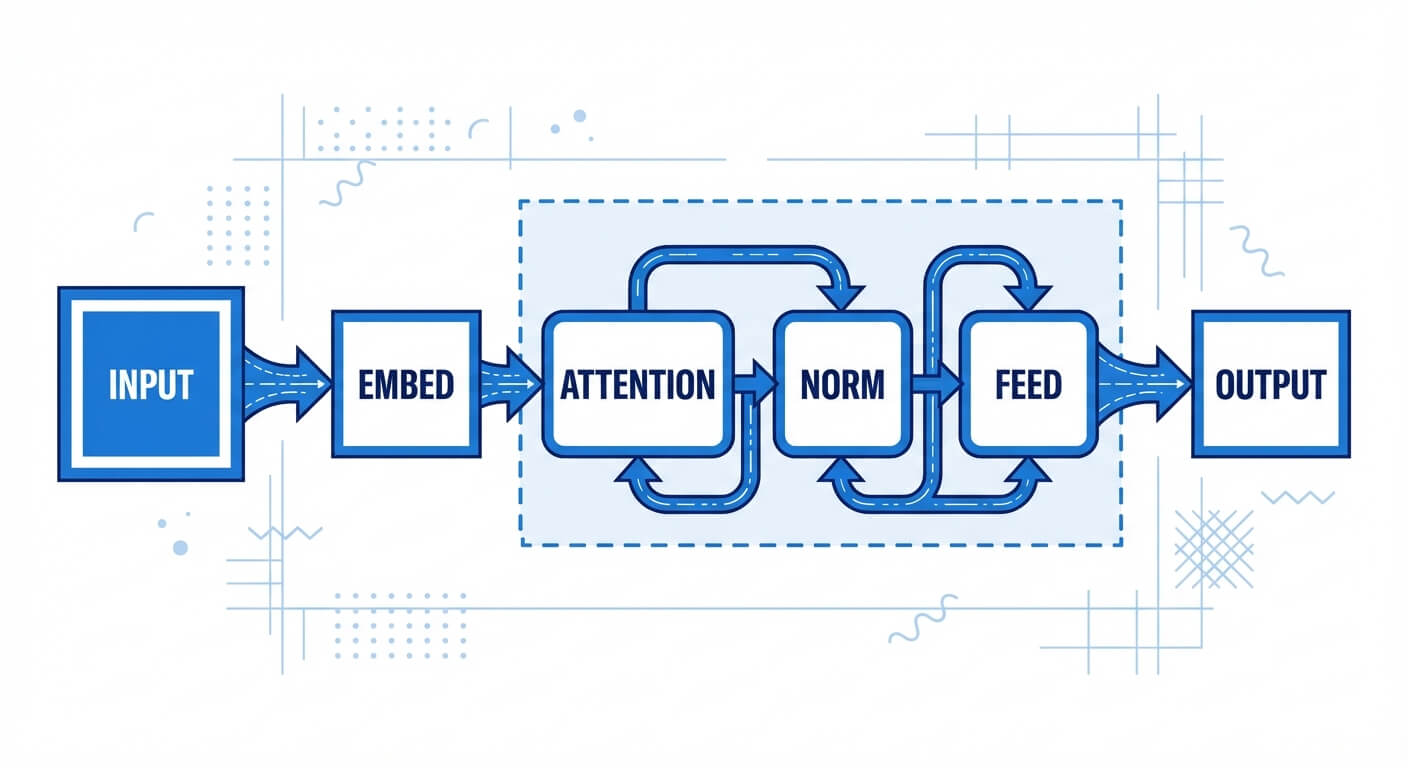
The Transformer Architecture
The Transformer, introduced by Vaswani et al. in 2017, is the architectural backbone of modern foundation models. Unlike RNNs or LSTMs, which process sequences sequentially, the Transformer processes entire sequences concurrently. This removes the temporal dependency of the recurrent step, enabling massive parallelization across GPU clusters.
The architecture consists of stacked blocks containing two primary sub-components: the Multi-Head Attention mechanism and the Position-wise Feed-Forward Network. Because the Transformer ingests tokens simultaneously, it lacks an inherent sense of order. To resolve this, positional encodings are injected into the input embeddings before they enter the network, providing discrete mathematical markers that signify a token's absolute or relative position within the context window.
Self-Attention Mechanisms
The self-attention mechanism is the mathematical operation that enables a foundation model to weigh the importance of disparate tokens within an input sequence, regardless of their positional distance.
For each token, the model computes three vectors: a Query (Q), a Key (K), and a Value (V), generated by multiplying the input embedding by learned weight matrices. The attention score is calculated by taking the dot product of the Query with all Keys, scaling it by the square root of the dimension size (to prevent vanishing gradients in the softmax function), applying a softmax transformation, and multiplying the result by the Value vector.
Expressed mathematically in plain text: Attention(Q, K, V) = softmax((Q K^T) / √d_k) V
Multi-head attention applies this operation multiple times in parallel, allowing the foundation model to simultaneously attend to different representation subspaces (e.g., one head might track subject-verb agreement, while another tracks narrative context).
Tokenization and Embeddings
Foundation models do not process raw text or images; they process numerical arrays. In text-based models, tokenization algorithms like Byte-Pair Encoding (BPE) or WordPiece chunk text into subword units. These subwords are mapped to a high-dimensional continuous vector space (often ranging from 4,096 to 12,288 dimensions) via an embedding layer.
By representing concepts as dense vectors, foundation models can perform spatial mathematics to establish semantic similarity. Words or concepts with similar meanings end up clustered near one another in this high-dimensional latent space.
The Training Lifecycle of Foundation Models
Training a foundation model from scratch is a massive engineering undertaking that requires orchestration across thousands of accelerators (GPUs or TPUs), distributed file systems, and resilient fault-tolerance mechanisms. The training pipeline is generally split into three distinct phases: pre-training, supervised fine-tuning, and alignment. Each phase relies on different loss functions, data curation strategies, and optimization algorithms to refine the model's predictive capabilities.
Phase 1: Unsupervised Pre-Training
Pre-training is the most computationally expensive phase. The model is initialized with random weights and tasked with processing terabytes of raw, unlabeled data—often scraped from the internet (e.g., Common Crawl, Wikipedia, GitHub).
For autoregressive models (like the GPT series), the objective is Causal Language Modeling: predicting the next token in a sequence given the previous tokens. The model outputs a probability distribution across its entire vocabulary. The loss is calculated using cross-entropy, measuring the divergence between the model's predicted distribution and the actual next token in the training data.
Cross Entropy Loss = - Σ y_i log(p_i)
During this phase, the optimization algorithm (typically AdamW) updates the model's billions of parameters via backpropagation. To handle the immense scale, engineering teams utilize advanced distributed computing paradigms such as Fully Sharded Data Parallelism (FSDP), Tensor Parallelism, and Pipeline Parallelism to split the model weights and optimizer states across multiple physical GPUs.
Phase 2: Supervised Fine-Tuning (SFT)
A pre-trained foundation model is essentially a document-completion engine; it is not yet a conversational assistant. If prompted with a question, it might merely generate more questions rather than answering. Supervised Fine-Tuning adapts the model to follow instructions.
During SFT, the model is trained on tens of thousands of high-quality, human-annotated demonstration pairs formatted as "Instruction" and "Response." The objective remains the same (next-token prediction), but the data distribution is narrow and highly curated. This phase teaches the model the structural syntax of being a helpful assistant.






Phase 3: Alignment via RLHF
To prevent the model from generating toxic, biased, or functionally incorrect content, a final alignment phase is applied. The most common technique is Reinforcement Learning from Human Feedback (RLHF).
- Reward Model Training: Human annotators rank multiple model-generated responses from best to worst. A secondary neural network (the Reward Model) is trained to predict human preference scores.
- Policy Optimization: The foundation model (acting as the policy) generates responses. The Reward Model scores them, and these scores are used as signals to update the foundation model's weights using Proximal Policy Optimization (PPO).
Recently, Direct Preference Optimization (DPO) has emerged as a mathematically simpler alternative to RLHF. DPO bypasses the need for a separate reward model by directly updating the model weights based on paired preference data using a modified cross-entropy objective.
Master structured AI Engineering + GenAI hands-on, earn IIT Roorkee CEC Certification at ₹40,000
AI Engineering Course Advanced Certification by IIT-Roorkee CEC
A hands on AI engineering program covering Machine Learning, Generative AI, and LLMs - designed for working professionals & delivered by IIT Roorkee in collaboration with Scaler.
Enrol NowParameter-Efficient Fine-Tuning (PEFT) Strategies
Training or even fully fine-tuning foundation models requires immense GPU memory footprint, primarily due to the storage needed for optimizer states, gradients, and the model weights themselves. For most software engineering teams building enterprise generative AI applications, full-parameter fine-tuning is cost-prohibitive. Parameter-Efficient Fine-Tuning (PEFT) addresses this constraint by freezing the base model and introducing a small number of trainable parameters.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Low-Rank Adaptation (LoRA)
LoRA is the industry standard for adapting foundation models to domain-specific tasks without catastrophic forgetting or excessive hardware requirements. Instead of updating the massive weight matrices within the Transformer's dense layers, LoRA injects trainable rank decomposition matrices into the architecture.
If a pre-trained weight matrix W_0 has dimensions d x k, updating it fully requires computing a gradient matrix of the exact same dimensions. LoRA freezes W_0 and models the weight update ΔW as the product of two low-rank matrices, B (dimension d x r) and A (dimension r x k), where the rank 'r' is significantly smaller than d or k.
The forward pass becomes: h = W_0 x + B A x
By setting 'r' to a low value (e.g., 8, 16, or 64), engineers can reduce the number of trainable parameters by over 99%. During inference, the learned matrices B and A can be multiplied together and statically added back into W_0, resulting in zero latency overhead.
To illustrate how an engineer might implement this conceptually, here is a simplified structural representation of a LoRA layer in Python using PyTorch:
Quantization (QLoRA)
To further reduce memory constraints, engineers employ Quantization—reducing the numerical precision of the model weights. By converting 32-bit floating-point (FP32) weights down to 16-bit (FP16), 8-bit (INT8), or even 4-bit (NF4) representations, the VRAM required to load the model drops drastically. QLoRA combines 4-bit NormalFloat quantization of the base model with 16-bit LoRA adapters, enabling the fine-tuning of a 70-billion parameter foundation model on a single high-end GPU.
Taxonomy of Foundation Models in Generative AI
Not all foundation models are designed for the same generative outputs. While the underlying premise of self-supervised learning on massive datasets remains consistent, the architectural design and specific loss objectives vary based on the intended modality. The generative AI landscape categorizes these models into distinct families based on their generation mechanics and data types.
Autoregressive Language Models (Decoder-Only)
Autoregressive models are the standard for modern text generation. Utilizing a "decoder-only" Transformer architecture, these models predict the next token in a sequence based strictly on preceding tokens. Because they utilize a causal mask during training—preventing the model from "looking ahead" at future tokens—they excel at open-ended generation tasks, conversational AI, and code generation. Examples include OpenAI’s GPT-4, Meta’s Llama 3, and Anthropic’s Claude.
Masked Language Models (Encoder-Only)
While historically foundational to modern NLP, encoder-only models are less common in pure generative AI but are critical for representation and understanding. These models process the entire input sequence simultaneously without a causal mask. During training, random tokens are hidden (masked), and the model must predict them based on bidirectional context (surrounding words). Google's BERT (Bidirectional Encoder Representations from Transformers) is the most famous example, excelling at embedding generation, sentiment analysis, and search ranking.
Turn Learning into Career Growth
Diffusion Models (Computer Vision)
For generating high-fidelity images and video, Diffusion Models have superseded older Generative Adversarial Networks (GANs). Diffusion is a continuous-time mathematical process. During training (the forward process), Gaussian noise is incrementally added to an image until it becomes pure static. The foundation model (often based on a U-Net architecture with cross-attention) is trained to reverse this process—predicting and subtracting the noise step-by-step to recover the original image. By conditioning the noise-prediction on text embeddings, models like Stable Diffusion and Midjourney generate novel images from natural language prompts.
Multimodal Foundation Models
The cutting-edge frontier of generative AI involves inherently multimodal foundation models. Rather than relying on fragile pipelines that stitch together separate speech, vision, and text models, natively multimodal models ingest diverse data types directly into a single Transformer architecture. In these systems, images are chopped into "patches," linearly projected into vectors, and fed alongside text tokens into the self-attention mechanisms. This allows the model to map visual pixels and text tokens into the exact same semantic latent space.
Become the Ai engineer who can design, build, and iterate real AI products, not just demos with an IIT Roorkee CEC Certification
AI Engineering Course Advanced Certification by IIT-Roorkee CEC
A hands on AI engineering program covering Machine Learning, Generative AI, and LLMs - designed for working professionals & delivered by IIT Roorkee in collaboration with Scaler.
Enrol NowFoundation Models vs. Traditional Machine Learning Models
Understanding the paradigm shift brought by foundation models requires a direct comparison with traditional, task-specific machine learning methodologies. The differences encompass architecture, scalability, hardware requirements, and the fundamental approach to solving computational problems.
| Comparison Aspect | Traditional ML Models | Foundation Models (Generative AI) |
|---|---|---|
| Architectural Scope | Narrow and task-specific (e.g., an SVM or CNN specifically built solely for classifying spam or identifying cats). | General-purpose and domain-agnostic (e.g., a Transformer that can translate text, write code, and summarize articles). |
| Data Requirements | Relies heavily on heavily annotated, supervised datasets. Data labeling is a primary bottleneck. | Relies on massive, unlabeled, raw datasets utilizing self-supervised learning objectives (like next-token prediction). |
| Adaptability & Transfer Learning | Poor transferability. A model trained for sentiment analysis cannot be easily adapted for translation without retraining. | Highly adaptable. Can perform zero-shot and few-shot inference out of the box, or be fine-tuned via PEFT for specific tasks. |
| Training Infrastructure Cost | Generally low to moderate. Can often be trained on a single GPU or consumer-grade hardware in hours or days. | Astronomically high. Requires distributed clusters of specialized AI accelerators (H100s, TPUs) running for months. |
| Inference Complexity | Fast, deterministic, and lightweight. Generally stateless and highly predictable. | Computationally heavy, memory-bound (KV caching), and probabilistic (generative). Subject to latency constraints. |
Systems Engineering Challenges and Limitations
Despite their profound capabilities, integrating foundation models into production systems introduces significant engineering complexities. Because they process vast amounts of continuous data and generate probabilistic outputs, engineers must contend with strict hardware limitations, latency bottlenecks, and reliability concerns that do not exist in traditional deterministic software.
Memory Bottlenecks and the KV Cache
During autoregressive generation, a foundation model predicts tokens one at a time. To predict token N, the model must compute attention scores across all N-1 preceding tokens. Recomputing the Key (K) and Value (V) tensors for historical tokens at every step is computationally disastrous.
To solve this, engineering frameworks implement a KV Cache. As tokens are processed, their K and V vectors are stored in GPU memory (VRAM). While this drastically improves compute latency, it shifts the bottleneck to memory bandwidth. As context windows grow, the KV Cache can consume gigabytes of VRAM per user session, severely limiting concurrent batch sizes. Advanced optimizations like PagedAttention (implemented in frameworks like vLLM) borrow concepts from operating system virtual memory to manage KV cache fragmentation efficiently.
Quadratic Complexity of Attention
Standard multi-head attention scales quadratically with sequence length—O(N^2) for compute and memory. If you double the context window, the computational cost quadruples. This makes scaling foundation models to read massive documents (e.g., 1 million tokens) mathematically difficult. System-level optimizations like FlashAttention—which fuses mathematical operations to minimize memory reads/writes to High Bandwidth Memory (HBM)—and architectural modifications like Grouped Query Attention (GQA) are employed to mitigate these constraints.
Hallucinations and Probabilistic Non-Determinism
At a granular level, foundation models do not "know" facts; they predict high-probability mathematical distributions. When the model encounters a prompt traversing a sparsely populated region of its latent space (e.g., obscure technical facts), it will still attempt to generate the most statistically probable sequence of tokens. This results in "hallucinations"—syntactically perfect but factually incorrect outputs. In production, mitigating hallucinations requires external systems engineering, such as Retrieval-Augmented Generation (RAG), which forces the model to ground its generation in an external, verified vector database.
Frequently Asked Questions (FAQ)
Why is it called a "foundation" model and not a "general" model? The term "foundation" emphasizes that these models are rarely the final product. Just as a building's foundation provides a structural base upon which various architectural designs can be built, a foundation model provides a baseline of generalized knowledge that developers fine-tune, prompt, augment to build specific end-user applications. They are foundational infrastructure, not Artificial General Intelligence (AGI).
What is the difference between a foundation model and a Large Language Model (LLM)? All LLMs (like GPT-4 or Llama 3) are foundation models, but not all foundation models are LLMs. "Foundation model" is an umbrella term encompassing any large-scale, self-supervised model. A text-to-image generator like Stable Diffusion is a foundation model, but it is not an LLM because it deals with visual modalities rather than pure language.
How does Grouped Query Attention (GQA) improve foundation model inference? In standard Multi-Head Attention, every Query head has a corresponding Key and Value head. In GQA, multiple Query heads share a single Key and Value head. This drastically reduces the memory footprint of the KV Cache during autoregressive generation without severely degrading model performance, allowing higher throughput and larger batch sizes in production environments.
Can foundation models be pre-trained from scratch on consumer hardware? No. While inferencing (running) or fine-tuning (via LoRA) a quantized foundation model is feasible on consumer GPUs with 16GB to 24GB of VRAM, pre-training a foundation model from scratch requires processing trillions of tokens across billions of parameters. This requires thousands of synchronized enterprise-grade GPUs (like NVIDIA H100s) connected via high-speed interconnects (NVLink/InfiniBand) and costs millions of dollars in compute alone.