What is Generative AI? Complete Guide
What is generative AI? Generative AI refers to a subset of deep learning models capable of producing novel content—such as text, images, code, and audio—based on learned data distributions. By leveraging architectures like Transformers, Generative Adversarial Networks (GANs), and Diffusion models, it moves beyond pattern recognition to synthesize entirely new, highly probable data outputs.
Understanding the Generative Artificial Intelligence Meaning
At its core, the generative artificial intelligence meaning hinges on the mathematical concept of probability distributions. Traditional machine learning models are designed to map inputs to discrete outputs (classification) or continuous values (regression). They evaluate existing data to make a prediction. Generative AI, however, is engineered to understand the underlying manifold of the training data. Once a generative model learns the joint probability distribution of the data, it can sample from this distribution to create net-new, synthetic instances that share the statistical properties of the original dataset.
For a software engineer or computer scientist, understanding generative AI requires a paradigm shift. You are no longer programming deterministic rules, nor are you merely drawing decision boundaries between classes. Instead, you are building systems that map a random noise vector or a semantic context vector into a complex, high-dimensional output space. Whether the model is predicting the next most logical token in a sequence of code or iteratively denoising a matrix of pixels to form an image, the underlying engine is rooted in complex matrix multiplications, backpropagation, and vast neural network parameter spaces.
Generative AI vs. Traditional AI (Discriminative Models)
To fully grasp the architecture of modern AI systems, developers must distinguish between generative models and discriminative models. Both rely on deep learning and neural networks, but their optimization objectives and mathematical foundations differ entirely. While a discriminative model answers the question, "Which category does this data belong to?" a generative model answers, "What does data belonging to this category look like?"
Stop learning AI in fragments—master a structured AI Engineering Course with hands-on GenAI systems with IIT Roorkee CEC Certification
AI Engineering Course Advanced Certification by IIT-Roorkee CEC
A hands on AI engineering program covering Machine Learning, Generative AI, and LLMs - designed for working professionals & delivered by IIT Roorkee in collaboration with Scaler.
Enrol Now
Discriminative models learn the conditional probability boundary P(Y|X)—meaning they predict a label Y given an input X. They are highly efficient for tasks like spam detection, anomaly detection, or facial recognition. Generative models, conversely, learn the joint probability distribution P(X, Y), or simply P(X) in unsupervised scenarios. This allows them to generate new data points X. Because generative models must understand the structural and contextual depth of the entire dataset rather than just the boundary between classes, they require significantly more computational overhead, parameter capacity, and training data.
| Feature | Generative AI | Traditional AI (Discriminative) |
|---|---|---|
| Core Objective | Synthesize new data instances that resemble the training set. | Classify existing data or predict a specific numerical value. |
| Mathematical Foundation | Learns the joint probability P(X, Y) or data distribution P(X). | Learns the conditional probability P(Y|X) (decision boundary). |
| Output Type | High-dimensional data (Text, Images, Audio, Code). | Low-dimensional data (Labels, Classes, Probabilities, Predictions). |
| Primary Architectures | Transformers, GANs, VAEs, Diffusion Models. | Convolutional Neural Networks (CNNs), Support Vector Machines (SVMs), Random Forests. |
| Example Use Case | Generating a [Python script](https://www.scaler.com/topics/python/ "rel=noopener nofollow") from a natural language prompt. | Detecting whether a given Python script contains a specific security vulnerability. |
How Does Generative AI Work Behind the Scenes?
Modern generative AI operates through foundation models—massive neural networks trained on broad datasets that can be adapted to a wide range of downstream tasks. The capacity of these models is dictated by their parameter count, often ranging from billions to trillions of trainable weights. When a user inputs a prompt, the text is tokenized into numerical representations, mapped to high-dimensional continuous vectors (embeddings), and processed through successive neural network layers.
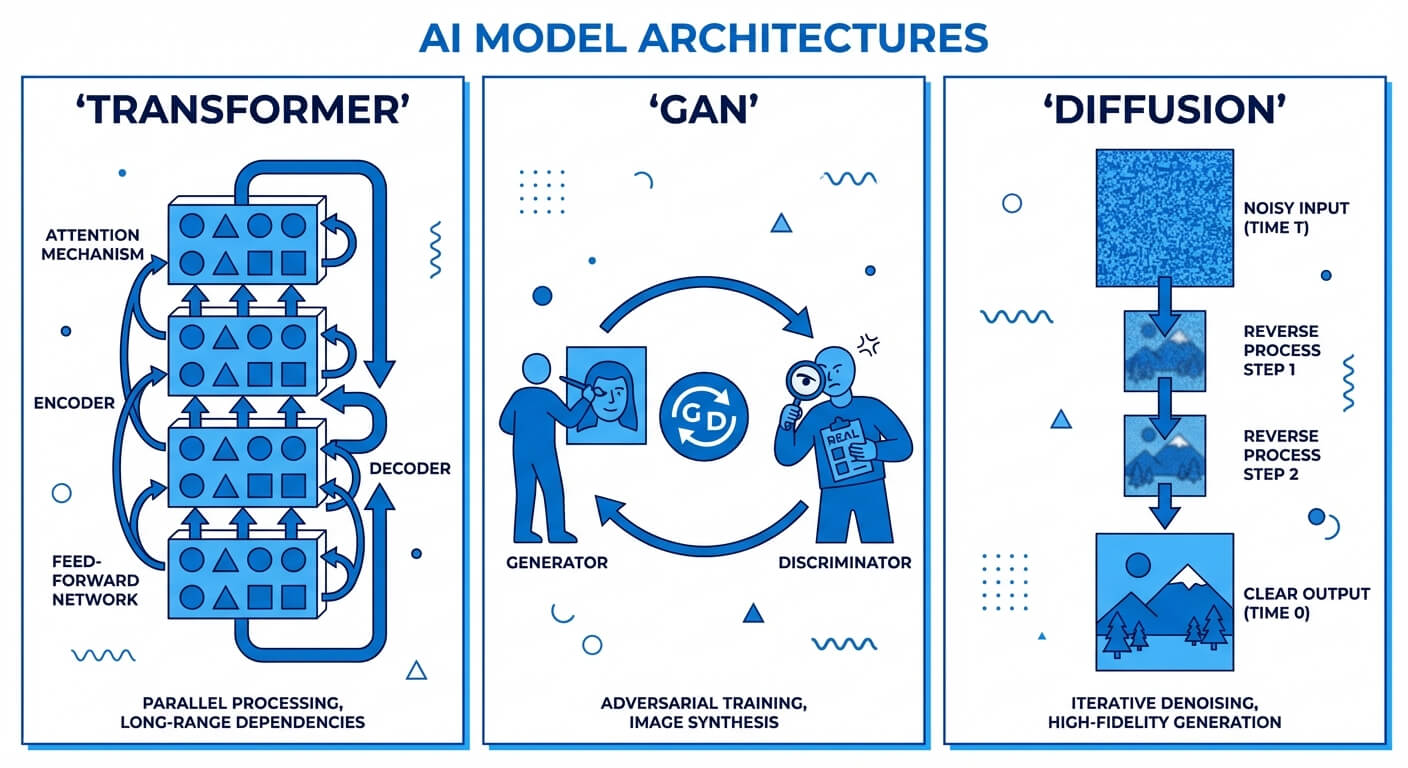
To understand the mechanics, we must examine the specific neural network architectures that drive these capabilities.
Transformer Networks
The Transformer architecture, introduced by Google researchers in the 2017 paper "Attention Is All You Need," is the bedrock of modern Large Language Models (LLMs) like GPT-4, LLaMA 3, and Claude. Before Transformers, sequence models like Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTMs) processed data sequentially, leading to bottlenecks in parallelization and issues with vanishing gradients on long contexts.
Transformers bypass sequential processing by utilizing a mechanism called Self-Attention. Self-attention allows the model to weigh the importance of every token in an input sequence relative to every other token simultaneously, regardless of their positional distance.
Mathematically, the self-attention mechanism computes an output utilizing three matrices derived from the input embeddings: Queries (Q), Keys (K), and Values (V). The formula is expressed as:
Attention(Q, K, V) = softmax((Q K^T) / √dk) V
Where dk represents the dimension of the key vectors. Dividing by √dk scales the dot product, preventing gradients from vanishing during backpropagation when passing through the softmax function.
Below is a simplified implementation of a Self-Attention block using PyTorch, illustrating how these matrices interact in code:
Generative Adversarial Networks (GANs)
GANs, introduced by Ian Goodfellow in 2014, fundamentally altered the landscape of image synthesis. A GAN consists of two distinct neural networks—a Generator (G) and a Discriminator (D)—locked in a continuous, zero-sum game (a minimax game).
The Generator's objective is to map a random latent noise vector (z) to a synthesized data sample (such as an image) that is indistinguishable from real data. The Discriminator's objective is to evaluate a given sample and output a probability indicating whether the sample is real (from the training data) or fake (produced by the Generator).
The training objective can be summarized by the following minimax value function V(D, G):
min(G) max(D) V(D, G) = E[log D(x)] + E[log(1 - D(G(z)))]
During training, backpropagation iteratively updates both networks. As the Discriminator gets better at spotting fakes, the Generator is forced to generate increasingly photorealistic outputs to fool it.
Become the Ai engineer who can design, build, and iterate real AI products, not just demos with an IIT Roorkee CEC Certification
AI Engineering Course Advanced Certification by IIT-Roorkee CEC
A hands on AI engineering program covering Machine Learning, Generative AI, and LLMs - designed for working professionals & delivered by IIT Roorkee in collaboration with Scaler.
Enrol NowVariational Autoencoders (VAEs)
Unlike GANs, which utilize adversarial training, Variational Autoencoders are probabilistic models that rely on Bayesian inference. A VAE consists of an Encoder that compresses input data into a lower-dimensional latent space, and a Decoder that reconstructs the data from this latent representation.
Crucially, standard autoencoders map inputs to fixed, discrete points in the latent space, making generation difficult because the space between points is undefined. VAEs solve this by mapping inputs to a probability distribution (typically a Gaussian distribution with a mean μ and a standard deviation σ). To generate new data, the system samples a random point from this continuous distribution and decodes it.
To allow backpropagation through a random sampling process, VAEs utilize the Reparameterization Trick. Instead of sampling directly from the distribution, the model samples a random noise variable ε from a standard normal distribution, and computes the latent vector z as:
z = μ + (σ ⊙ ε)
This ensures the gradients can bypass the stochastic node and flow back through the deterministic μ and σ parameters to update the encoder weights.
Diffusion Models
Diffusion models are currently the state-of-the-art architectures for high-fidelity image and audio generation (powering tools like DALL-E 3, Midjourney, and Stable Diffusion). These models are based on non-equilibrium thermodynamics.
The diffusion process consists of two phases:
- Forward Process (Adding Noise): The model takes a clean image and gradually adds Gaussian noise over a series of steps (T) until the image is completely destroyed, leaving only isotropic Gaussian noise.
- Reverse Process (Denoising): A neural network (typically a U-Net architecture with attention mechanisms) is trained to predict and subtract the noise added at each step. By starting with pure random noise and iteratively applying the learned reverse process, the model synthesizes a highly detailed, coherent image from nothing.
The Training Pipeline of Generative Models
Building a generative AI system from scratch is not a single compilation step; it is a multi-stage pipeline requiring massive distributed computing, specialized datasets, and careful algorithmic alignment. Software engineers working in AI ops or ML engineering must understand this pipeline, as optimizing even a fraction of a percent of compute efficiency saves millions of dollars.
The standard pipeline for modern large-scale generative models (particularly LLMs) follows three distinct phases: Unsupervised Pre-training, Supervised Fine-Tuning, and Alignment.
Unsupervised Pre-training
The pre-training phase is where the foundation model acquires its generalized knowledge of syntax, grammar, coding logic, and world facts. The model is fed terabytes of unstructured data (web scrapes, books, GitHub repositories, Wikipedia) and trained using a self-supervised objective. For LLMs, this objective is typically Next-Token Prediction (Causal Language Modeling).
Given a sequence of tokens (x1, x2, ..., x_t-1), the model attempts to maximize the probability of the next token x_t. The objective function minimizes the negative log-likelihood over the dataset:
L = - Σ log P(x_t | x1, ..., x_t-1; θ)
During this phase, the model is essentially a massive statistical engine. It does not know how to answer a question or follow a prompt; it only knows how to continue a document naturally. Pre-training requires thousands of GPUs running continuously for months.
Supervised Fine-Tuning (SFT)
To transform a raw, pre-trained text predictor into a usable assistant (like ChatGPT), the model undergoes Supervised Fine-Tuning. Human annotators create high-quality prompt-and-response pairs. The pre-trained model is then fine-tuned on this much smaller, curated dataset.
This phase teaches the model the format of interaction: recognizing that an input is a question or a command, and structuring its output as a helpful, formatting-compliant answer rather than just appending text that looks statistically similar to the prompt.
Reinforcement Learning from Human Feedback (RLHF)
The final, crucial step for modern generative AI is alignment via RLHF. Even after SFT, models might generate factually incorrect, biased, or unhelpful answers. RLHF utilizes reinforcement learning algorithms to align the model’s outputs with human preferences.
- Reward Model Training: A secondary neural network (the Reward Model) is trained to evaluate responses. Humans rank multiple model outputs for a single prompt, and the Reward Model learns to score these responses based on human preference.
- PPO Optimization: The generative model (the policy) is then optimized using an algorithm like Proximal Policy Optimization (PPO). The model generates responses, the Reward Model scores them, and the PPO algorithm updates the generative model's weights to maximize the expected reward while penalizing it for straying too far from its original pre-trained distribution (using Kullback-Leibler divergence).
The Software and Hardware Stack for Generative AI
Deploying and scaling generative AI models goes far beyond standard microservices architecture. Software engineers handling AI systems are constrained by memory bandwidth, floating-point operations per second (FLOPS), and network latency between distributed nodes. The stack requires highly specialized hardware and low-level software frameworks.
The rapid integration of generative AI into the tech stack is evolving the role of the software engineer. While understanding traditional data structures, algorithms, and system design remains critical, developers must now incorporate AI-native competencies.
Hardware Infrastructure
The immense parameter counts of generative models (e.g., 70 billion parameters for LLaMA 3 70B) present significant memory challenges. A single parameter represented in a 16-bit floating-point number (FP16) requires 2 bytes of memory. Therefore, a 70B model requires roughly 140 GB of VRAM just to load the weights into memory, ignoring the extra memory needed for the context window (KV Cache) and batch processing.
- GPUs (Graphics Processing Units): Nvidia dominates this space with its A100 and H100 Tensor Core GPUs. These processors are optimized for highly parallelized matrix multiplications. A typical enterprise cluster connects hundreds of these GPUs via NVLink, allowing them to share memory pools.
- TPUs (Tensor Processing Units): Google’s proprietary Application-Specific Integrated Circuits (ASICs) are specifically designed to accelerate neural network machine learning tasks, offering massive throughput for both training and inference.
- NPU (Neural Processing Units): Increasingly found in edge devices and consumer hardware (like Apple Silicon) to handle smaller generative tasks locally without cloud latency.
Software Frameworks and Libraries
To interface with the hardware, ML engineers rely on specialized software stacks that handle distributed computing and hardware acceleration.
- CUDA: Nvidia's parallel computing platform and programming model that allows software to use specific types of GPUs for general-purpose processing.
- PyTorch and TensorFlow: The primary deep learning frameworks used to construct, train, and execute neural network graphs. PyTorch has largely become the industry standard for generative AI research due to its dynamic computational graph.
- Hugging Face Transformers: An open-source library that provides high-level APIs to download, implement, and fine-tune state-of-the-art pre-trained models.
- Inference Optimization Frameworks: Tools like vLLM and TensorRT-LLM use techniques like PagedAttention to optimize the KV cache, drastically improving the throughput (tokens/second) of model serving in production environments.
- Quantization: To fit massive models on consumer hardware, engineers use quantization frameworks (like GPTQ or AWQ) to compress weights from FP16 down to INT8 or INT4 formats, sacrificing a minute amount of accuracy for massive gains in memory efficiency and inference speed.
High-Value Applications and Use Cases
For software engineers, IT professionals, and technology enterprises, generative AI is not merely a novelty; it is rapidly becoming an infrastructure layer. Its ability to parse, transform, and synthesize data enables entirely new application architectures.
Software Engineering and Code Generation
Generative AI models fine-tuned on codebases (such as OpenAI's Codex, GitHub Copilot, and StarCoder) have fundamentally altered the software development lifecycle. These models understand multiple programming languages, frameworks, and syntax rules.
- Automated Boilerplate and Refactoring: Developers can prompt LLMs to generate boilerplate REST APIs, implement specific design patterns, or refactor legacy code (e.g., converting an older Java application to modern Kotlin).
- Test Generation: Generative AI can automatically parse functions and generate comprehensive unit tests, including edge case scenarios and mock data structures, improving test coverage metrics with minimal human labor.
- Code Review and Security Analysis: Models can be integrated into CI/CD pipelines to analyze pull requests, flag potential security vulnerabilities (like SQL injection or buffer overflows), and suggest optimized implementations.
Natural Language Processing and Text Generation
The most prominent application of generative AI resides in Natural Language Processing (NLP). Moving beyond simple chatbots, enterprise systems utilize generative models for complex semantic tasks.
- Retrieval-Augmented Generation (RAG): To solve the issue of LLMs hallucinating facts or lacking proprietary data, engineers implement RAG architectures. In a RAG setup, a user's prompt is converted into a vector embedding and used to query a Vector Database containing internal company documents. The relevant documents are retrieved and injected into the LLM's context window, allowing the model to generate accurate, source-backed responses.
Below is a conceptual example of how an engineer might set up a basic RAG pipeline using Python and LangChain:
Computer Vision and Image Synthesis
Generative AI in computer vision has evolved from blurry, low-resolution GAN outputs to photorealistic synthesis capable of fooling human experts.
- Asset Generation for Gaming and UI/UX: Developers and designers use diffusion models to rapidly prototype user interface assets, generate thousands of unique textures for 3D environments, or create conceptual art.
- Medical Imaging Data Augmentation: In healthcare technology, acquiring sufficient training data is often bottlenecked by privacy laws (HIPAA). Generative models can synthesize highly accurate, completely anonymous medical scans (like MRIs or X-rays) to train diagnostic AI models without violating patient privacy.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Audio and Speech Generation
Generative AI systems can clone voices, synthesize realistic text-to-speech (TTS), and generate original musical compositions. Architectures like WaveNet and transformer-based audio models analyze the waveforms of human speech to replicate intonation, pacing, and regional accents. This allows software engineers to easily integrate highly dynamic, conversational voice agents into customer service software or accessibility tools.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Risks, Limitations, and Governance Concerns
Despite the transformative potential of generative AI, deploying these systems into production environments introduces critical systemic risks. Unlike deterministic algorithms where inputs result in guaranteed outputs, the probabilistic nature of generative AI demands robust safeguards, extensive monitoring, and strict governance protocols.
Hallucinations and Stochastic Parrots
The most profound limitation of Large Language Models is their propensity to "hallucinate"—generating highly plausible, confident, but factually entirely incorrect statements. Because generative AI models are statistical predictors, they lack a true internal model of truth or real-world logic. They map semantic relationships, not factual ground truth.
If a sequence of tokens statistically sounds correct, the model will output it. For software engineers, relying blindly on AI-generated code can lead to importing non-existent, hallucinated library packages, which malicious actors can register on public package managers to execute supply-chain attacks.
Copyright, Legal, and Regulatory Challenges
Generative models are pre-trained on staggering amounts of data scraped from the internet, much of which is copyrighted material. This has resulted in ongoing lawsuits from authors, artists, and media publishers.
From an enterprise governance perspective, engineers must ensure that using AI-generated code does not violate open-source licensing agreements (such as GPL). If a generative model inadvertently memorizes and regurgitates a proprietary algorithm from its training data, utilizing that code could expose a company to severe intellectual property litigation. Furthermore, regulatory frameworks like the European Union's AI Act impose stringent compliance requirements on high-risk AI systems regarding transparency and data governance.
Environmental Impact and Compute Cost
The carbon footprint and resource consumption of generative AI represent significant operational concerns. Training a massive parameter model requires gigawatt-hours of electricity. Beyond electrical consumption, data centers housing thousands of GPUs generate massive amounts of heat, requiring millions of gallons of fresh water for cooling systems. For enterprise IT architectures, the financial overhead of running large models via API calls or hosting them internally on cloud infrastructure can rapidly outpace the cost of traditional computing if not highly optimized.
Security and Adversarial Attacks
Generative AI models introduce new attack vectors that traditional cybersecurity frameworks are ill-equipped to handle.
- Prompt Injection: Similar to SQL injection, malicious users can craft specific input strings that override an LLM's system instructions, forcing the model to bypass safety constraints, leak internal data, or execute unauthorized commands.
- Jailbreaking: Using psychological or logical tricks (such as asking the AI to "roleplay" as an unrestrained system) to bypass the Reinforcement Learning from Human Feedback (RLHF) guardrails.
- Data Poisoning: Adversaries injecting maliciously crafted data into the open web, knowing that web-crawlers will scrape it for future model training, subtly shifting the model’s behavior or inserting deliberate vulnerabilities.
Essential Skills for Software Engineers in the Generative AI Era
The rapid integration of generative AI into the tech stack is evolving the role of the software engineer. While understanding traditional data structures, algorithms, and system design remains critical, developers must now incorporate AI-native competencies.
- Prompt Engineering and Context Optimization: Moving beyond simple queries, engineers must understand how to construct zero-shot, few-shot, and Chain-of-Thought (CoT) prompts to steer model behavior programmatically.
- Vector Database Administration: Relational databases (SQL) and document stores (NoSQL) are insufficient for managing high-dimensional vector embeddings. Engineers must master vector databases like Pinecone, Milvus, and Weaviate, understanding algorithms like Hierarchical Navigable Small World (HNSW) for fast approximate nearest neighbor (ANN) searches.
- Orchestration Frameworks: Familiarity with frameworks like LangChain, LlamaIndex, and Semantic Kernel is crucial for chaining multiple LLM calls, connecting models to external APIs, and managing memory in conversational agents.
- Model Evaluation and MLOps: Engineers must implement automated pipelines to evaluate generative output quality using metrics like BLEU, ROUGE, or LLM-as-a-judge frameworks, and integrate model deployment safely into traditional CI/CD workflows.
Frequently Asked Questions (FAQ)
What is the difference between AGI and Generative AI? Generative AI refers to narrow AI systems designed specifically to generate content based on learned data distributions. Artificial General Intelligence (AGI) is a theoretical concept representing a machine that possesses human-like cognitive abilities, capable of understanding, learning, and applying generalized intelligence to any problem domain, rather than just generating patterns.
Can Generative AI replace software engineers? Currently, generative AI acts as an advanced productivity multiplier rather than a replacement. While it excels at generating boilerplate code, scripting, and syntax formatting, it lacks the ability to comprehend complex, large-scale system architecture, abstract business logic, and cross-system integrations. The role of the AI engineer is shifting from writing syntax to designing system logic and validating AI-generated components.
What is the "temperature" parameter in LLMs? Temperature is a hyperparameter used to control the randomness of the model's output generation. Mathematically, it adjusts the logits before applying the softmax function. A low temperature (e.g., 0.1) makes the model highly deterministic, almost always selecting the most probable next token—ideal for code generation or factual queries. A high temperature (e.g., 0.8) flattens the probability distribution, allowing the model to select less probable tokens, resulting in more diverse and creative text.
Why do Generative AI models require so much VRAM? VRAM (Video RAM) is necessary because deep learning models must hold billions of mathematical parameters (weights and biases) in memory simultaneously to compute the forward pass. Additionally, generative models like Transformers require extra VRAM for the KV Cache (Key-Value Cache), which stores the attention states of previously processed tokens so the model does not have to recompute them for every new word generated.