Schedule in DBMS

Scheduling is the technique of preserving the order of the operations from one transaction to another while executing such concurrent transactions. A series of operations from one transaction to another transaction is known as a schedule.
What is Scheduling, and why is it required?
Transactions are a set of instructions that perform operations on databases. When multiple transactions are running concurrently, then a sequence is needed in which the operations are to be performed because at a time, only one operation can be performed on the database. This sequence of operations is known as Schedule, and this process is known as Scheduling.
When multiple transactions execute simultaneously in an unmanageable manner, then it might lead to several problems, which are known as concurrency problems. In order to overcome these problems, scheduling is required.
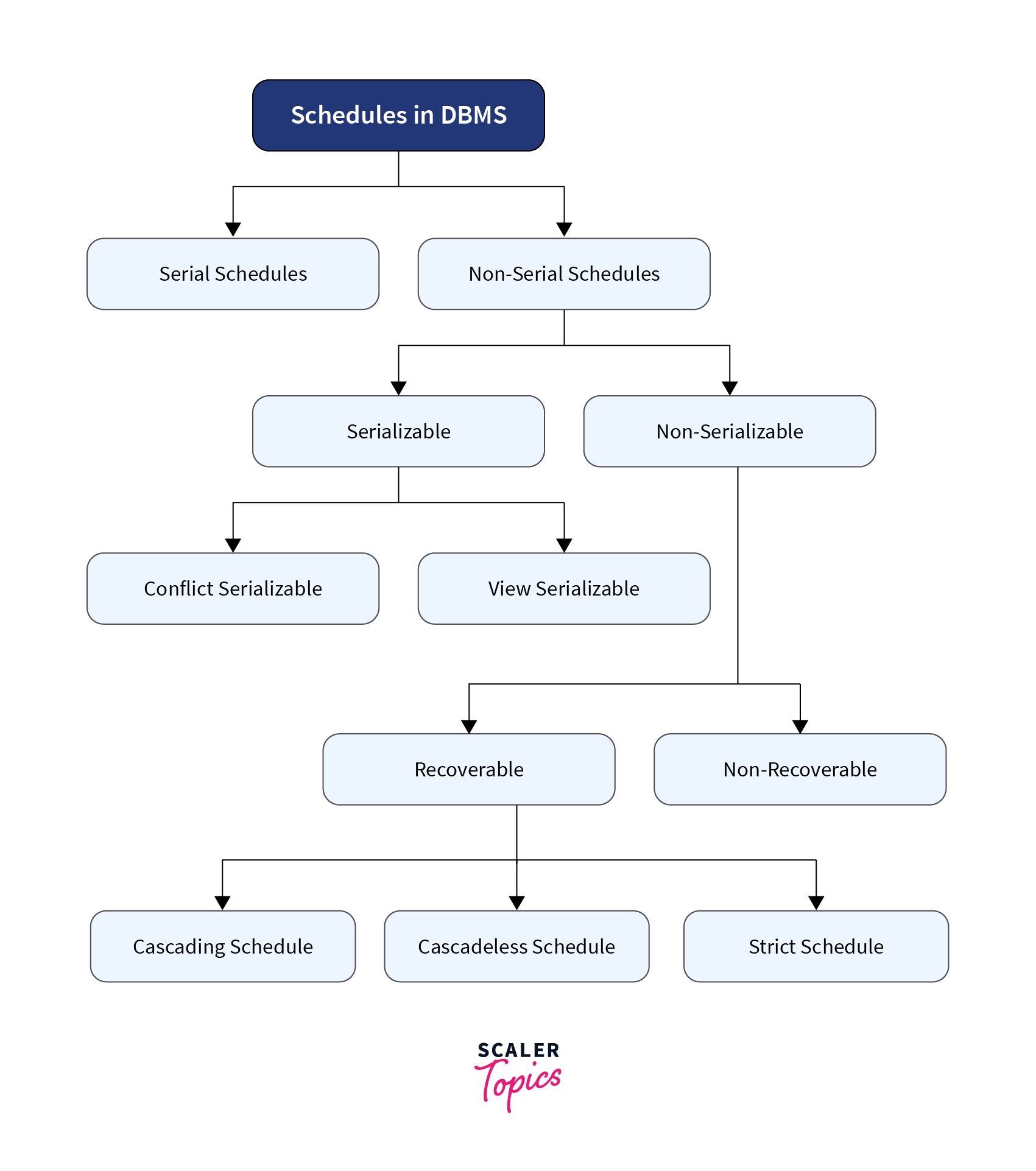
Types of Schedules
There are mainly two types of scheduling -
- Serial Schedule
- Non-serial Schedule Further, they are divided into their subcategories, as shown below.
Serial Schedule
As the name says, all the transactions are executed serially one after the other. In serial Schedule, a transaction does not start execution until the currently running transaction finishes execution. This type of execution of the transaction is also known as non-interleaved execution.
Serial Schedules are always recoverable, cascades, strict, and consistent. A serial schedule always gives the correct result.
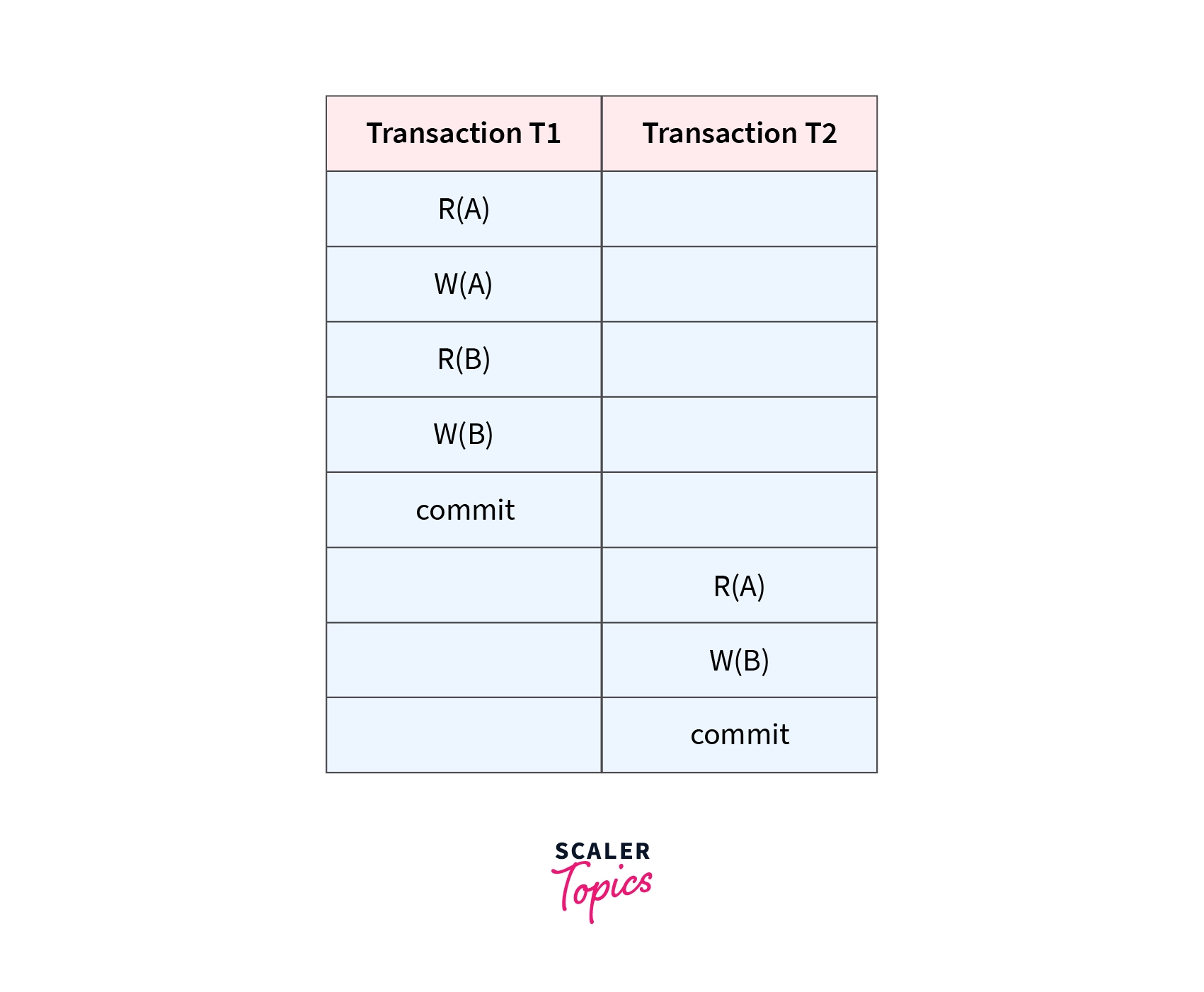 Consider two transactions T1 and T2 shown above, which perform some operations. If it has no interleaving of operations, then there are the following two possible outcomes - Either execute all T1 operations, which were followed by all T2 operations. Or execute all T2 operations, which were followed by all T1 operations.
In the above figure, the Schedule shows the serial Schedule where T1 is followed by T2, i.e. T1 -> T2.
Where R(A) -> reading some data item ‘A’.
And, W(B) -> writing/updating some data item ‘B’.
If n = number of transactions, then a number of serial schedules possible = n!.
Consider two transactions T1 and T2 shown above, which perform some operations. If it has no interleaving of operations, then there are the following two possible outcomes - Either execute all T1 operations, which were followed by all T2 operations. Or execute all T2 operations, which were followed by all T1 operations.
In the above figure, the Schedule shows the serial Schedule where T1 is followed by T2, i.e. T1 -> T2.
Where R(A) -> reading some data item ‘A’.
And, W(B) -> writing/updating some data item ‘B’.
If n = number of transactions, then a number of serial schedules possible = n!.
Therefore, for the above 2 transactions, a total number of serial schedules possible = 2.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Non-serial Schedule
In a non-serial Schedule, multiple transactions execute concurrently/simultaneously, unlike the serial Schedule, where one transaction must wait for another to complete all its operations. In the Non-Serial Schedule, the other transaction proceeds without the completion of the previous transaction. All the transaction operations are interleaved or mixed with each other.
Non-serial schedules are NOT always recoverable, cascades, strict and consistent.
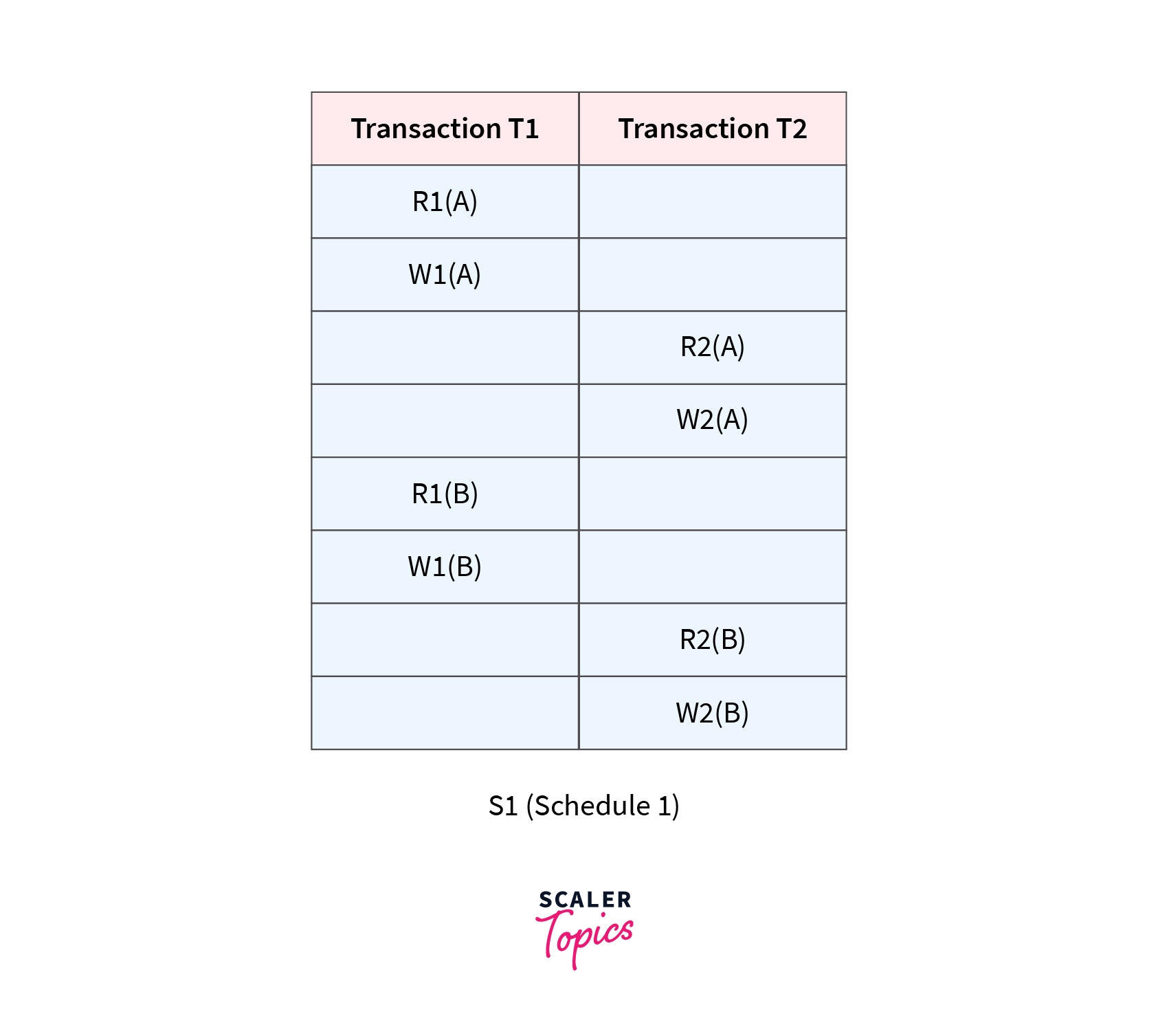 In this Schedule, there are two transactions, T1 and T2, executing concurrently. The operations of T1 and T2 are interleaved. So, this Schedule is an example of a Non-Serial Schedule.
In this Schedule, there are two transactions, T1 and T2, executing concurrently. The operations of T1 and T2 are interleaved. So, this Schedule is an example of a Non-Serial Schedule.
Total number of non-serial schedules = Total number of schedules – Total number of serial schedules
Non-serial schedules are further categorized into serializable and non-serializable schedules. Let's now discuss further Serializability.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Serializability in DBMS
Serializability in DBMS is a concept that helps to identify which non-serial schedules are correct and will maintain the consistency of the database. A serializable schedule always leaves the database in a consistent state. A serial schedule is always a serializable schedule because, in a serial Schedule, a transaction only starts when the other transaction has finished execution. A non-serial schedule of n transactions is said to be a serializable schedule, if it is equivalent to the serial Schedule of those n transactions. A serial schedule does not allow concurrency; only one transaction executes at a time, and the other starts when the already running transaction is finished.
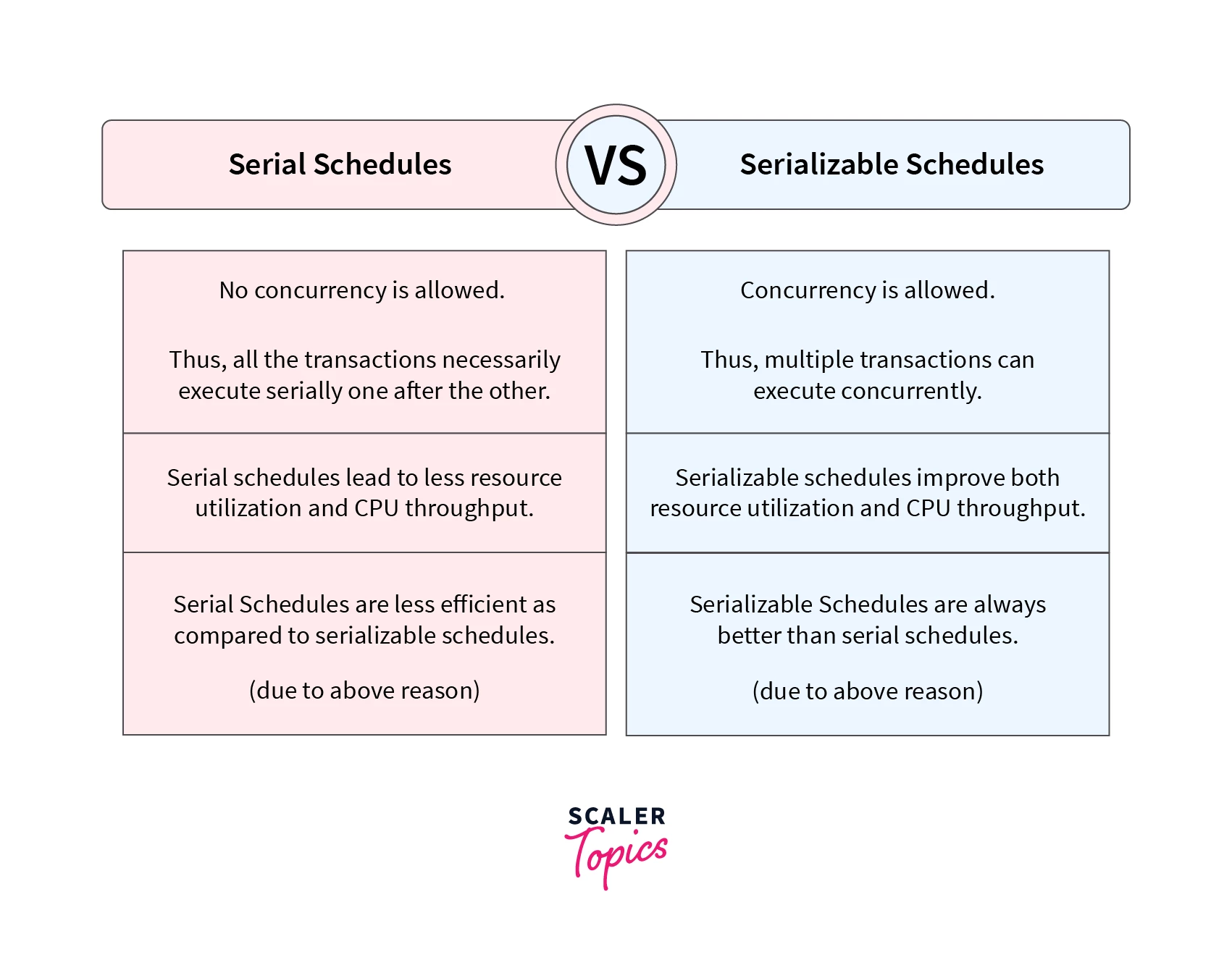
Difference between Serial Schedule and Serializable Schedule
Types of Serializability:
- Conflict Serializability
- View Serializability
-
Conflict Serializability
A schedule is called conflict serializable if it can be transformed into a serial schedule by swapping non-conflicting operations. An operations pair become conflicting if all conditions satisfy:
- Both belong to separate transactions.
- They have the same data item.
- They contain at least one write operation.
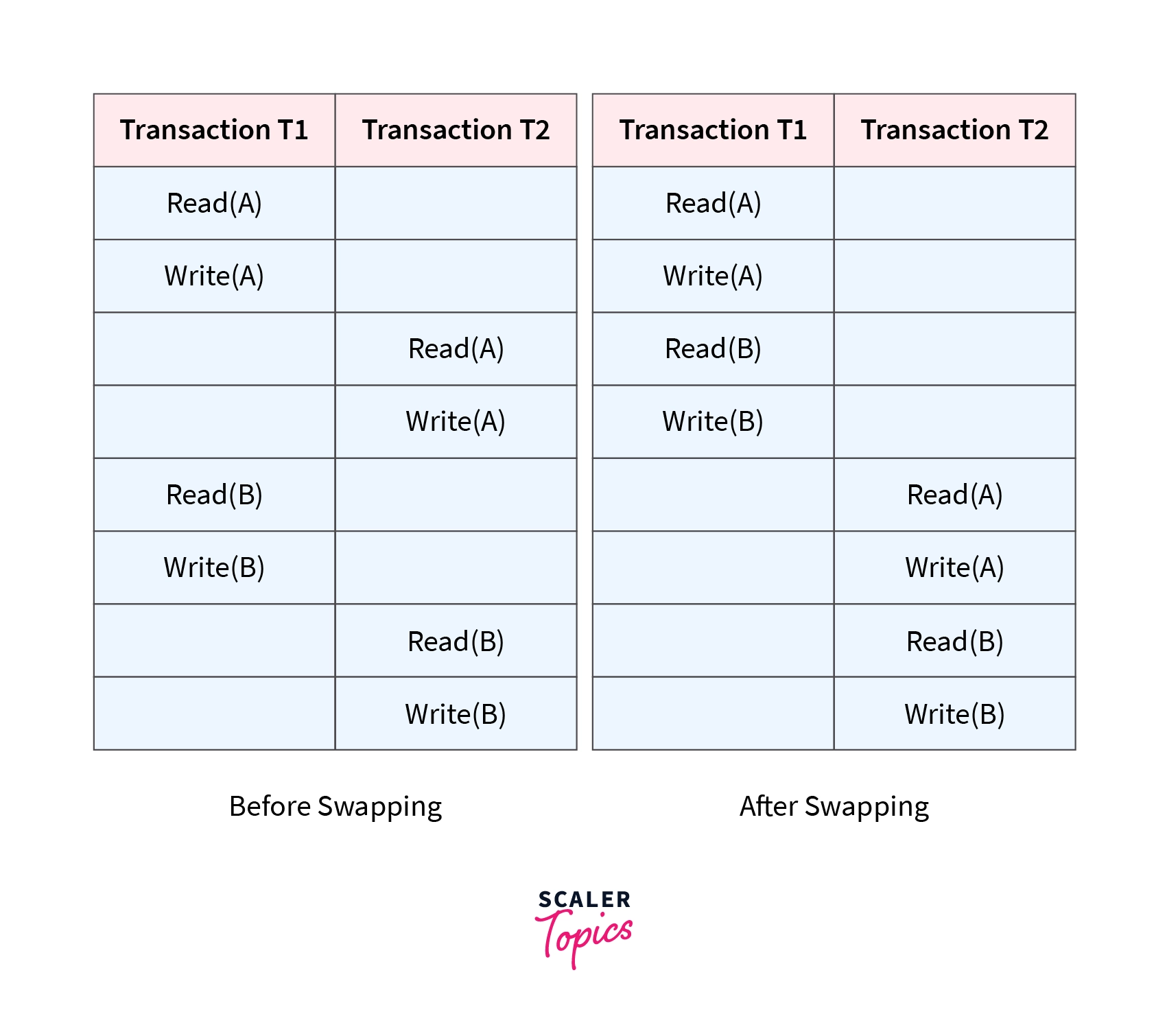 In this schedule, Write(A)/Read(A) and Write(B)/Read(B) are called as conflicting operations. This is because all the above conditions hold true for them. Thus, by swapping(non-conflicting) 2nd pair of the read/write operation of 'A' data item and 1st pair of the read/write operation of 'B' data item, this non-serial Schedule can be converted into a serializable Schedule. Therefore, it is conflict serializable.
In this schedule, Write(A)/Read(A) and Write(B)/Read(B) are called as conflicting operations. This is because all the above conditions hold true for them. Thus, by swapping(non-conflicting) 2nd pair of the read/write operation of 'A' data item and 1st pair of the read/write operation of 'B' data item, this non-serial Schedule can be converted into a serializable Schedule. Therefore, it is conflict serializable.
-
Turn Learning into Career Growth
1200+Hiring Partners89%Placement Rate11,000+Placements147%Avg Salary Increment2.5XCareer Growth₹23 LPAAvg Post-Scaler Salary1200+Hiring Partners89%Placement Rate11,000+Placements147%Avg Salary Increment2.5XCareer Growth₹23 LPAAvg Post-Scaler SalaryView Serializability
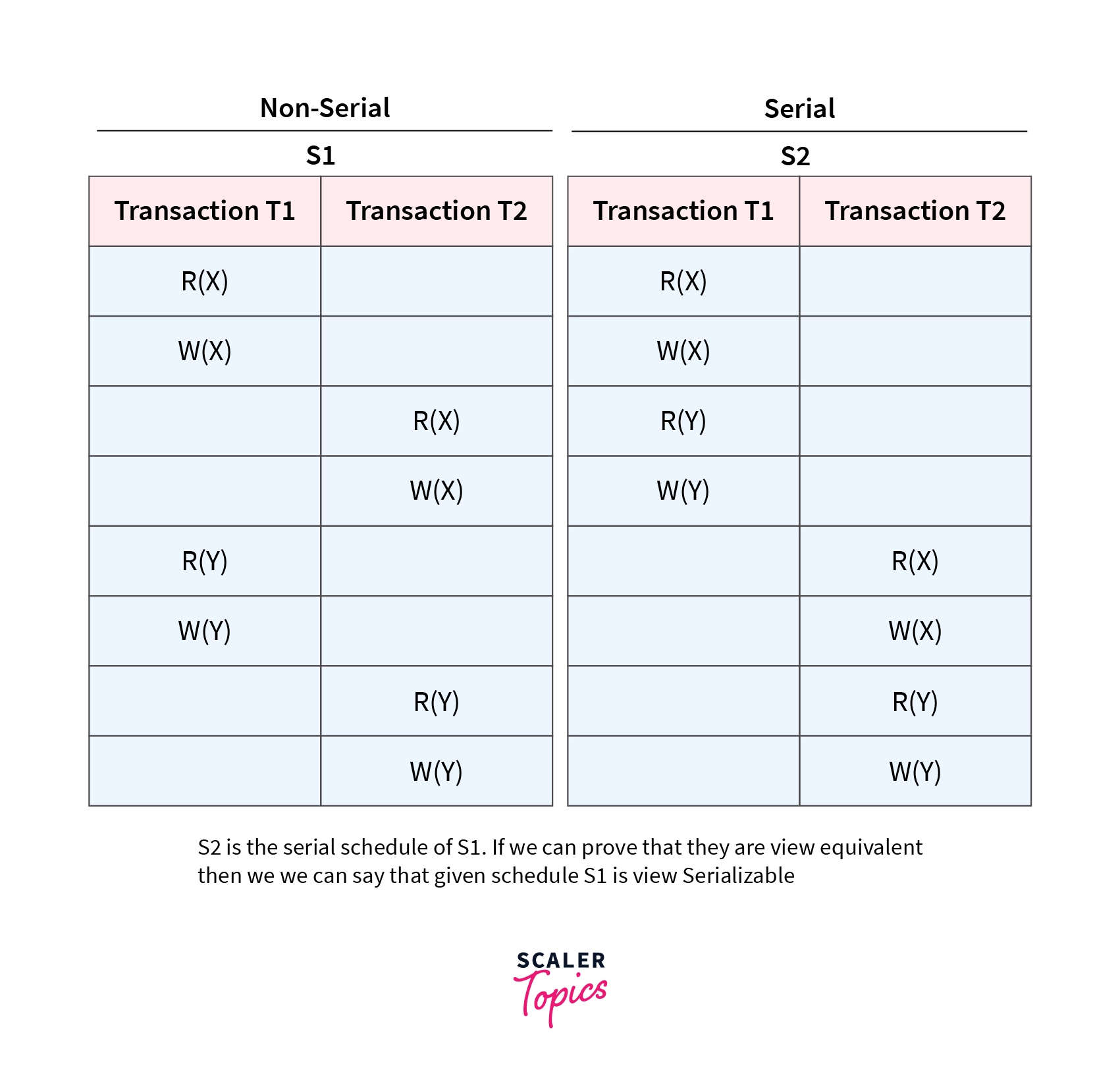
A schedule is viewed serializable if it is view equivalent to a serial schedule. If a schedule is conflict serializable, then it will be view serializable. The view serializable which does not conflict with serializable, contains blind writes.
Non-Serializability in DBMS
A non-serial schedule that is not serializable is called a non-serializable schedule. Non-serializable schedules may/may not be consistent or recoverable. Non-serializable Schedule is divided into types:
- Recoverable Schedule
- Non-recoverable Schedule
Recoverable Schedule
A schedule is recoverable if each transaction commits only after all the transactions from which it has read have committed. In other words, if some transaction Ty reads a value that has been updated/written by some other transaction Tx, then the commit of Ty must occur after the commit of Tx.
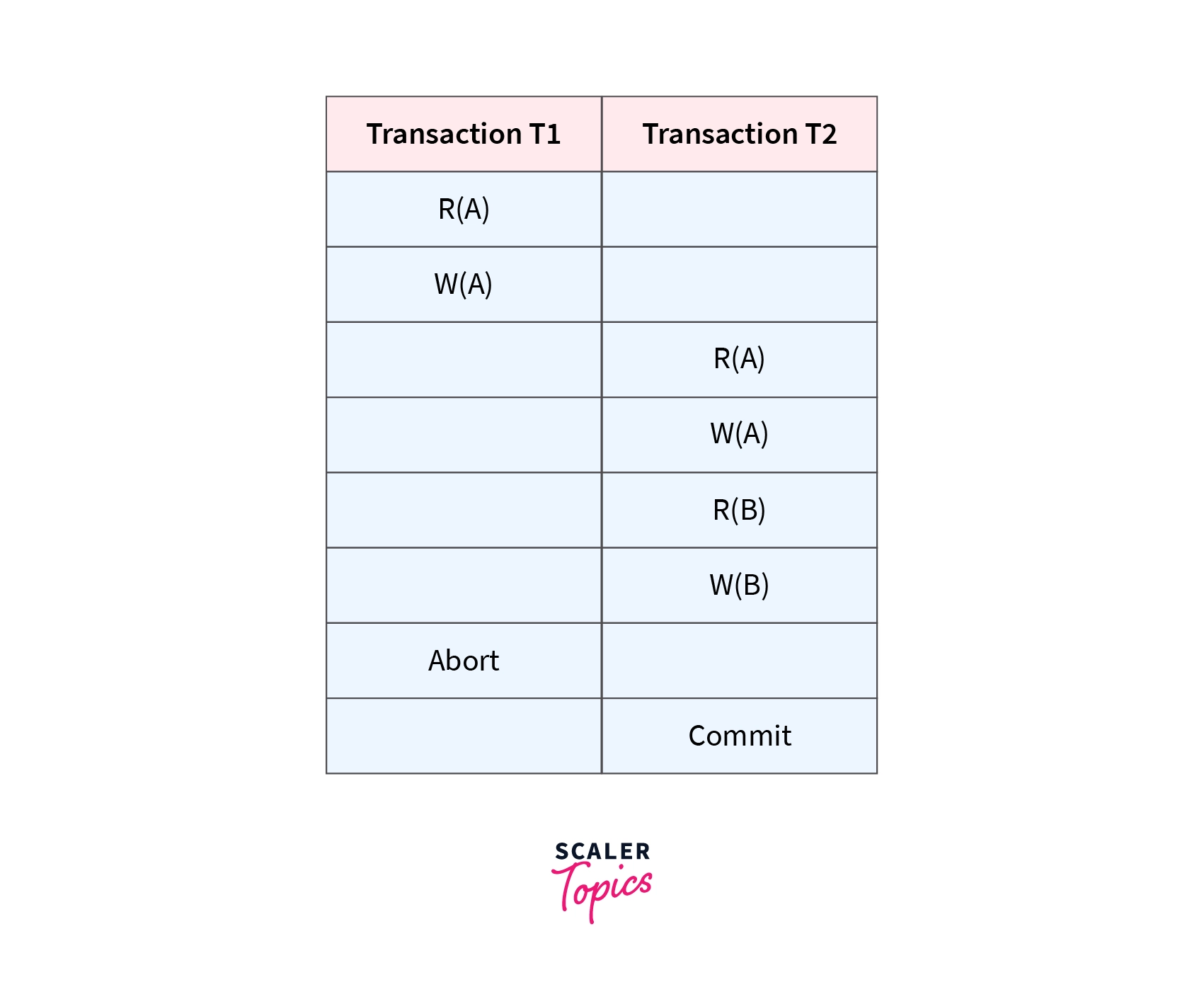 The schedule shown above is Recoverable since T1 commits before T2, which makes the value read by T2 correct.
The schedule shown above is Recoverable since T1 commits before T2, which makes the value read by T2 correct.
Recoverable schedules are further categorized into 3 types:
- Cascading Schedule
- Cascadeless Schedule
- Strict Schedule
Cascading Schedule
If in a schedule, several other dependent transactions are forced to rollback/abort because of the failure of one transaction, then such a schedule is called a Cascading Schedule or Cascading Rollback or Cascading Abort. It simply leads to the wastage of CPU time.
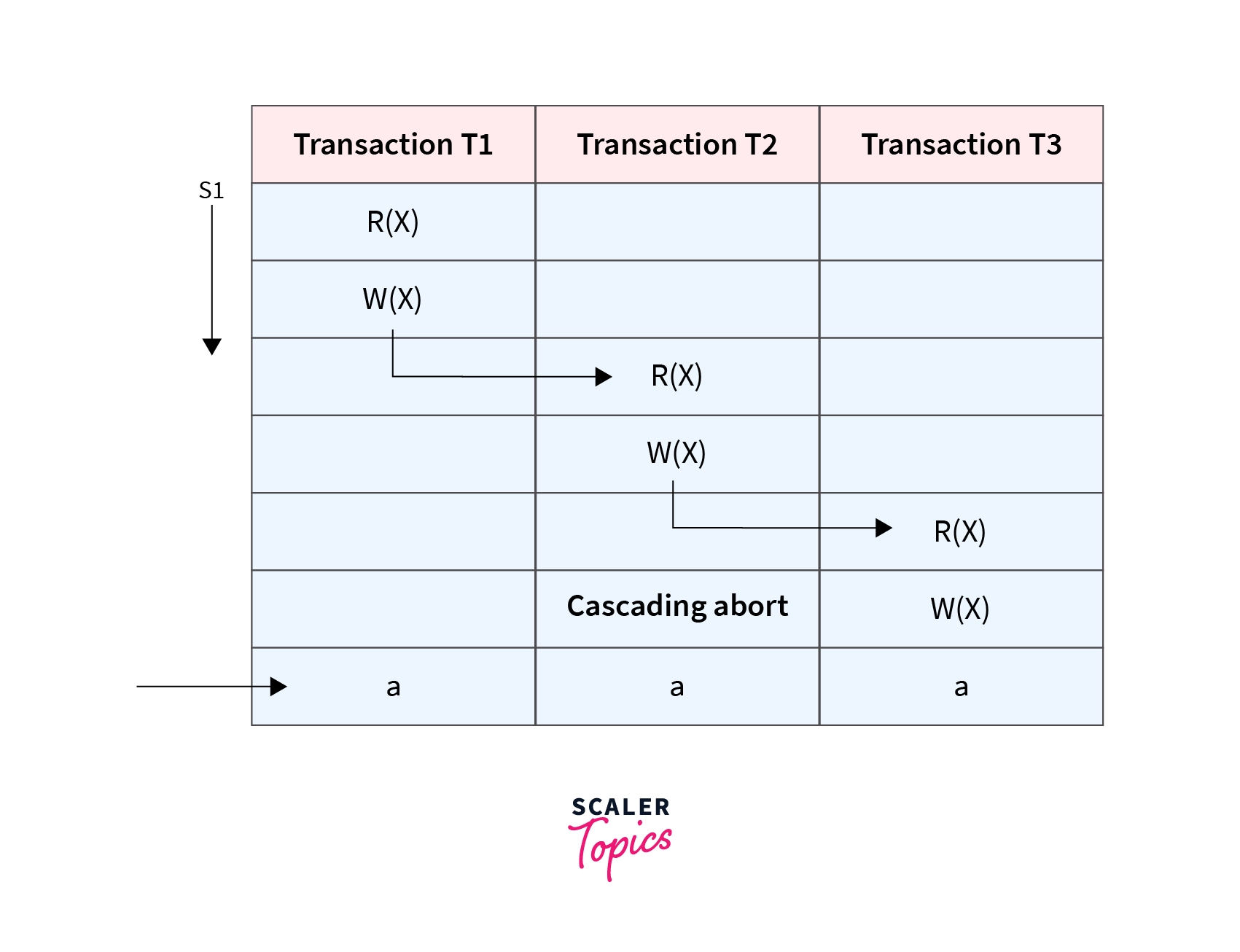
Here, Transaction T2 depends on transaction T1, and transaction T3 depends on transaction T2. Thus, in this Schedule, the failure of transaction T1 will cause transaction T2 to roll back, and a similar case for transaction T3. Therefore, it is a cascading schedule. If the transactions T2 and T3 had been committed before the failure of transaction T1, then the Schedule would have been irrecoverable.
Cascadeless Schedule
If in a schedule, a transaction is not allowed to read a data item until and unless the last transaction that has been written is committed/aborted, then such a schedule is called a Cascadeless Schedule. It avoids cascading rollback and thus saves CPU time. To prevent cascading rollbacks, it disallows a transaction from reading uncommitted changes from another transaction in the same Schedule. In other words, if some transaction Ty wants to read a value that has been updated or written by some other transaction Tx, then only after the commit of Tx, the commit of Ty must read it. Look at the example shown below.
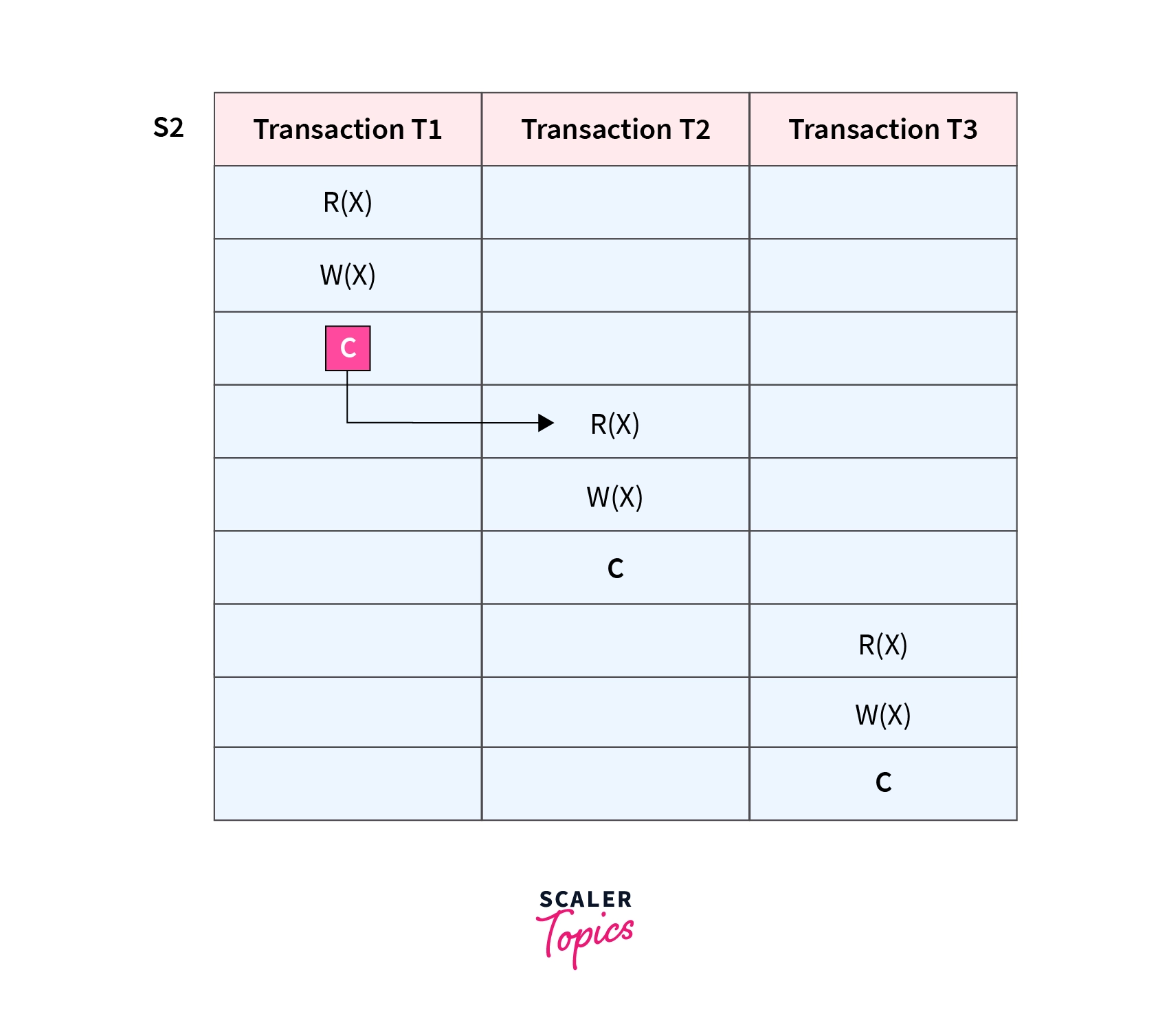
Here, the updated value of X is read by transaction T2 only after the commit of transaction T1. Hence, the Schedule is a Cascadeless schedule.
Strict Schedule
If in a schedule, until the last transaction that has written it is committed or aborted, a transaction is neither allowed to read nor write data item, then such a schedule is called as Strict Schedule. Let's say we have two transactions Ta and Tb. The write operation of transaction Ta precedes the read or write operation of transaction Tb, so the commit or abort operation of transaction Ta should also precede the read or write of Tb. A strict Schedule allows only committed read and write operations. This Schedule implements more restrictions than a cascadeless schedule. Consider an example shown below.
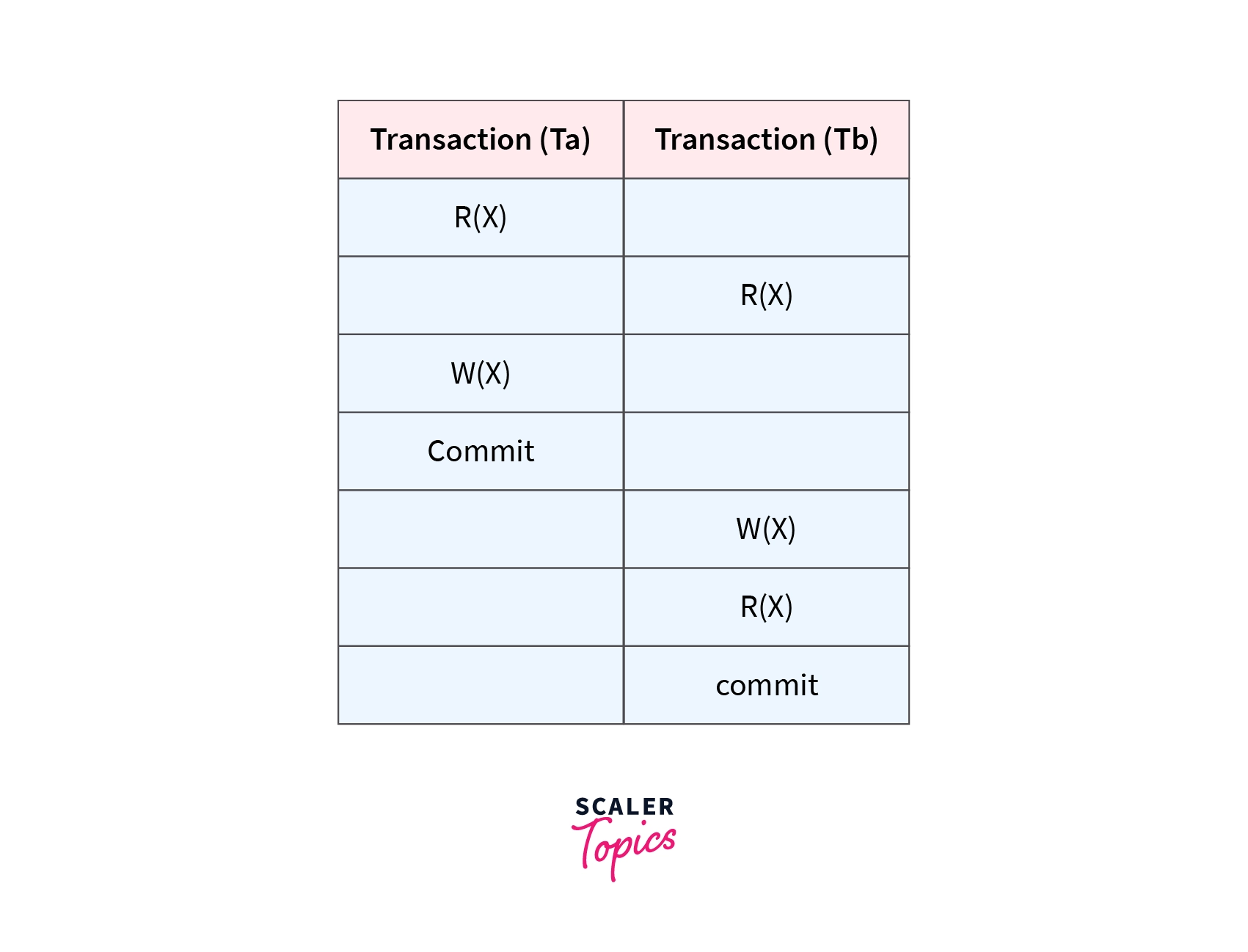
Here, transaction Tb reads/writes the written value of transaction Ta only after the transaction Ta commits. Hence, the Schedule is a strict Schedule.
Non-Recoverable Schedule
If a transaction reads the value of an operation from an uncommitted transaction and commits before the transaction from where it has read the value, then such a schedule is called a Non-Recoverable schedule.
A non-recoverable schedule means when there is a system failure, we may not be able to recover to a consistent database state. If the commit operation of Ti doesn't occur before the commit operation of Tj, it is non-recoverable.
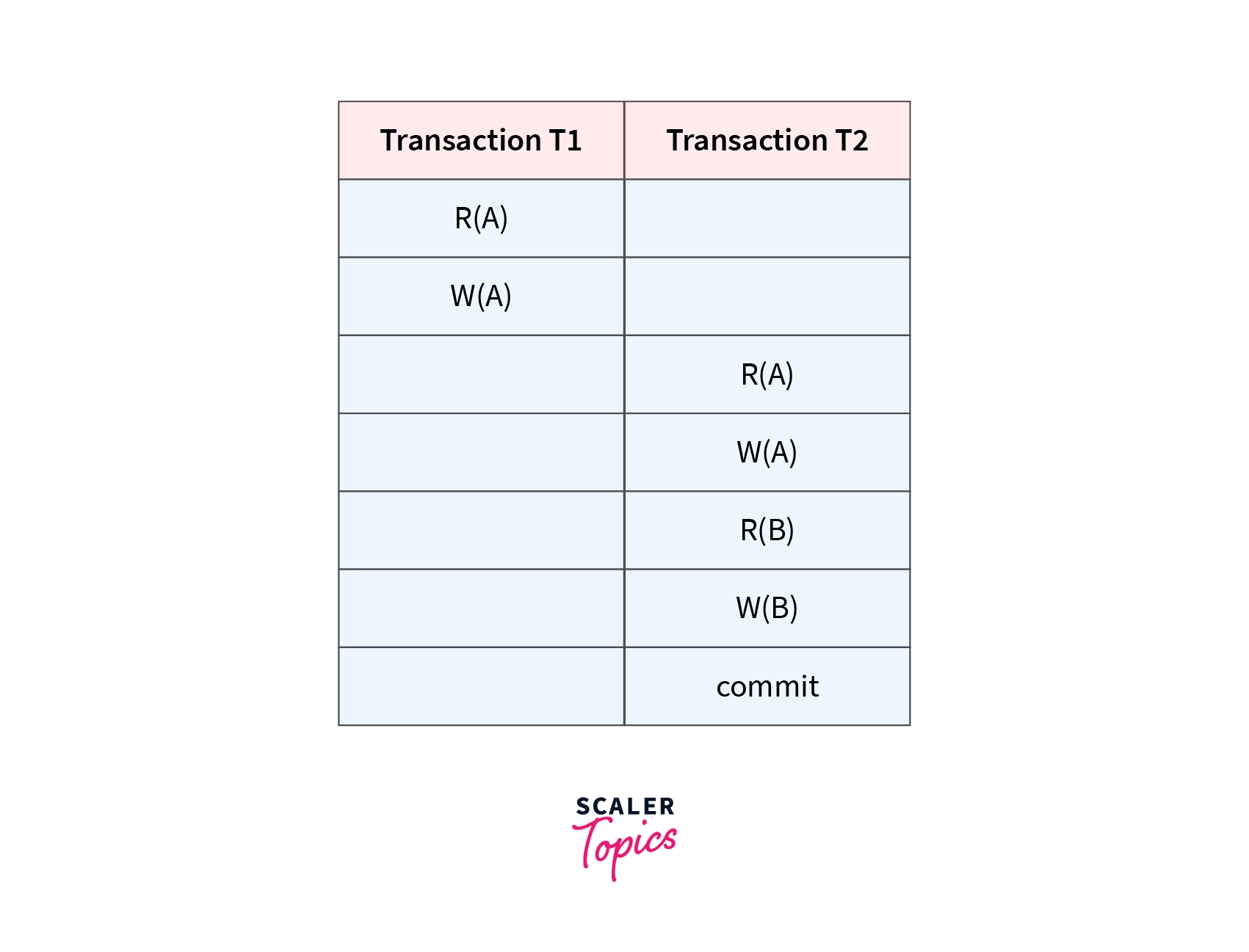
Consider the following Schedule involving two transactions T1 and T2. T2 read the value of A written by T1, and committed. T1 might later abort/commit; therefore the value read by T2 is wrong, but since T2 committed, this Schedule is non-recoverable.
Conclusion
-
Schedules in DBMS - A series of operations from one transaction to another transaction is known as a Schedule. It is used to preserve the order of the operation in each individual transaction.
-
Types of schedules -
- Serial Schedule: The serial schedule is a type of Schedule where one transaction is executed completely before starting another transaction.
- Non-serial Schedule: In a Non-serial schedule, multiple transactions execute concurrently/simultaneously.
-
Total number of non-serial schedules = Total number of schedules – Total number of serial schedules.
-
A schedule is called conflict serializable if it can be transformed into a serial schedule by swapping non-conflicting operations.
-
A schedule is viewed as serializable if it is view equivalent to a serial schedule. If a schedule is conflict serializable, then it will be view serializable.