ELMo NLP
Overview
ELMo is a deeply contextualized word representation that models the intricate aspects of word use, such as syntax and semantics. ELMo NLP follows a neural network architecture where word vectors are computed on top of a two-layer bidirectional language model (biLM). Each of these layers has two passes
- forward
- backward
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Introduction
Embeddings from Language Models (ELMo), which demonstrated state-of-the-art performance on many common tasks like question-answering, sentiment analysis, and named-entity extraction, was introduced in the 2018 publication "Deep Contextualized Word Embeddings". It has been demonstrated that ELMo can produce performance gains of up to roughly 5%. But why is this concept considered so revolutionary? Let's look at it in detail, starting with answering the question - What is ELMo NLP?
What is ELMo NLP?
What is ELMo? ELMo is a strong computational model that transforms words into numbers in addition to being a Muppet. This crucial step enables machine learning models—which require inputs of numbers rather than words—to be trained on textual data.
ELMo is a deeply contextualized word representation that models the intricate aspects of word use, such as syntax and semantics, as well as how these uses vary across language settings (i.e., to model polysemy). These word vectors are pre-trained on a sizable text corpus and are learned functions of the internal states of a deep bidirectional language model (biLM). They are simple to incorporate into current models and considerably advance state of the art for a variety of difficult NLP issues, such as sentiment analysis, question answering, and textual entailment.
There exists a plethora of modules that serve these purposes. What makes ELMo NLP so good? There are a few primary points that stand out in ELMo NLP:
- ELMo NLP accounts for the context of words
- It is trained on a large text corpus
- It is open-source.
Let's talk about these points in detail and check out why they're important and what makes ELMo NLP significant.
The Need for ELMo NLP
-
The context of a word is uniquely accounted for by ELMo:
The exact spelling of a word is all that is used to construct an embedding in earlier language models like GloVe, Bag of Words, and Word2Vec. They don't take into account how the word is used. These language models, for instance, would provide the identical embedding for "trust" in the following instances:- I can't trust you.
- They have no trust left for their friend.
- I invested in a trust fund.
However, ELMo's embeddings are context-sensitive and can provide various embeddings for the same word depending on the surrounding words and the word's context. It would provide several responses for "trust" in these instances because it would understand that the term is being used in various contexts. Since ELMo's embeddings now have access to more information, thanks to this special ability, performance is likely to improve. BERT is a comparable pre-trained transformer-based model for language modeling that also takes context into account.
-
ELMo was trained on a lot of data:
You're probably well aware of the power of big data, whether you're a seasoned machine learning researcher or simply a casual observer. Even the "small" version of the ELMo model has a training set of 1 billion words. The original ELMo model was trained on a corpus of 5.5 billion words. It's a lot of information! ELMo has acquired extensive linguistic expertise as a result of being trained on such a large amount of data, and it will perform well on a variety of datasets. -
ELMo NLP can be used by anyone:
The culture of making research open-source is one of the most significant elements that has fueled the development of machine learning as a field. Researchers can facilitate easy use and expansion of current concepts by making code and datasets open-source. ELMo adheres to this ethic by being largely open-source. It has a webpage with links for downloading the small, medium, and original versions of the model in addition to some basic details about it. For a quick copy of ELMo, anyone wishing to use it should visit this page. Additionally, the code is available on GitHub and has a rather comprehensive README that explains how to utilize ELMo.
Let us also take a look at how ELMo NLP improves the performance of existing baseline models.
| Task | Previous SOTA | Performance | Baseline | ELMo + Baseline | Increase (Absolute / Relative) |
|---|---|---|---|---|---|
| SQuAD | Liu et al. (2017) | 84.4 | 81.1 | 85.8 | 4.7 / 24.9 % |
| SNLI | Chen et al. (2017) | 88.6 | 88.0 | 88.7 +- 0.17 | 0.7 / 5.8% |
| SRL | He et al. (2017) | 81.7 | 81.4 | 84.6 | 3.2 / 17.2 % |
| Coref | Lee et al. (2017) | 67.2 | 67.2 | 70.4 | 3.2 / 9.8% |
| NER | Peters et al. (2017) | 91.93 +-0.19 | 90.15 | 92.22 +- 0.10 | 2.06 / 21% |
| SST-5 | McCann et al. (2017) | 53.7 | 51.4 | 54.7 +- 0.5 | 3.3 / 6.8 % |
ELMo has demonstrated state-of-the-art performance on massive datasets in NLP, including SQuAD, NER, and SST, by combining context-aware word embeddings and big data. Since ELMo has been mentioned more than 4,500 times, it is clear that it is a significant development in the field and has completely changed how we approach computational linguistics tasks like sentiment analysis and question-answering.
Now that we're convinced, let's dive into the architecture of ELMo NLP.
Turn Learning into Career Growth
ELMo NLP Architecture
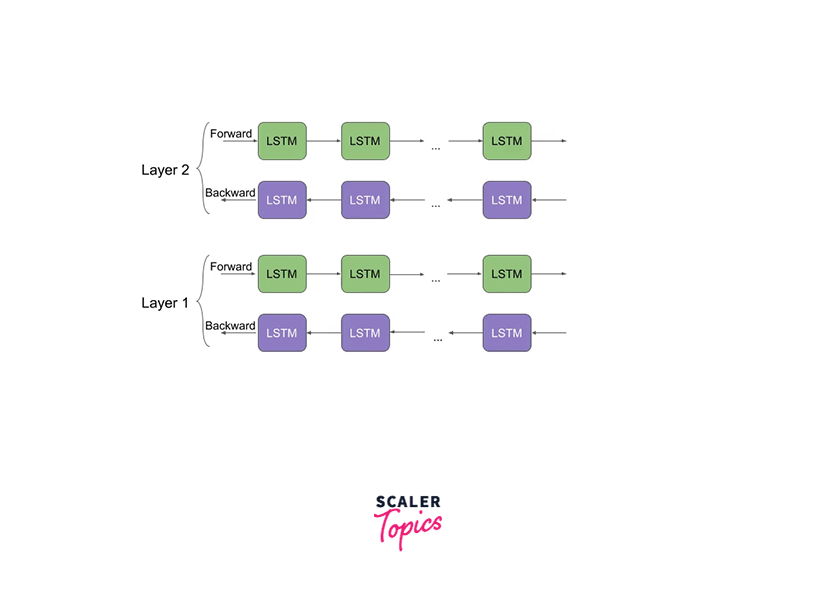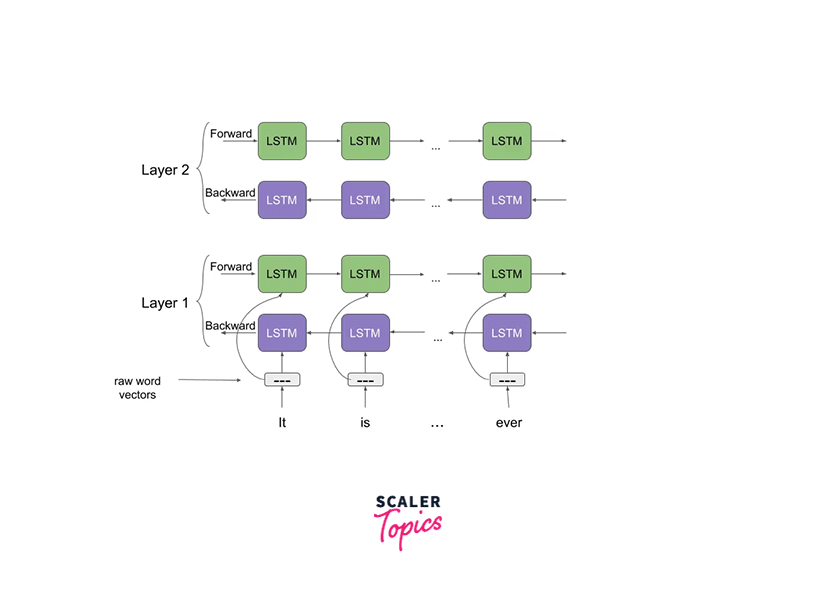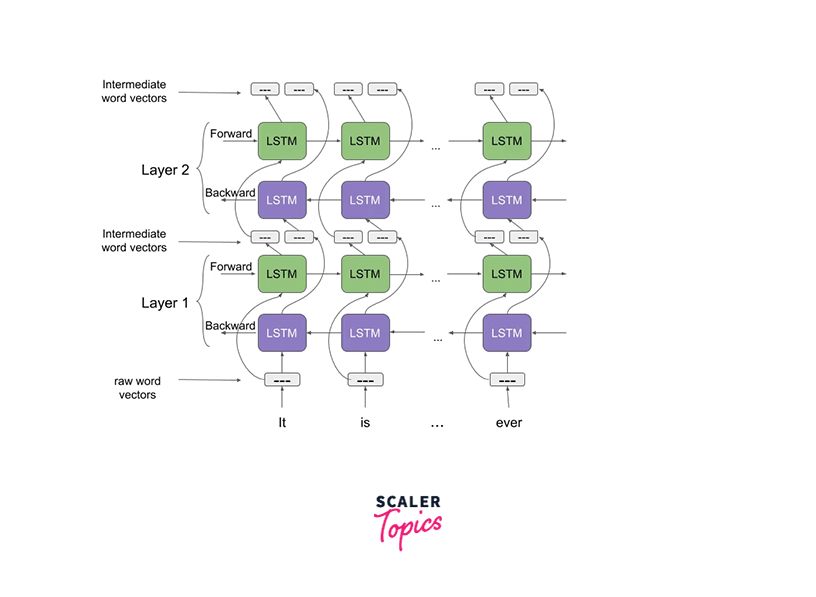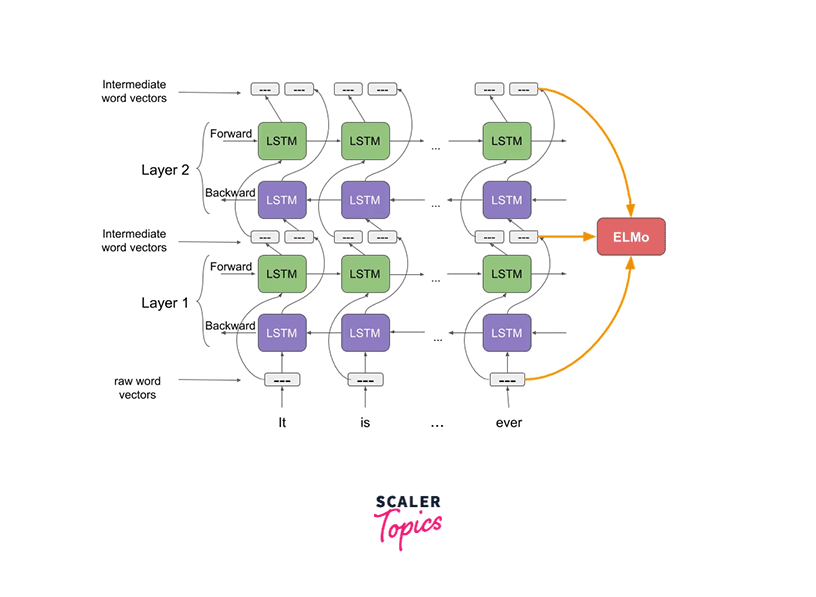
Above is an image that shows the architecture of the neural network architecture of ELMo NLP. ELMo word vectors are computed on top of a two-layer bidirectional language model (biLM). Now each of these layers has two passes - the forward pass and the backward pass.
This architecture, as shown above, uses a character-level convolutional neural network that creates representations of words of an input text string to raw word vectors. These raw word vectors then act as an input to the first layer of our bidirectional language model. Coming to the two-pass architecture, the first pass - the forward pass contains information about a certain word and the context (words before the current word) of that word. The second pass (backward pass) contains information about the word and the context (words after) of the current word.
The intermediate word vectors comprise this pair of information from the forward and backward passes. The next layer of the bidirectional language model receives these intermediate word vectors. The weighted sum of the two intermediate word vectors and the raw word vectors makes up the final representation (ELMo).
The bidirectional language model captures the internal structure of the word because its input is computed from characters rather than words. Without even considering the context in which words like beauty and beautiful are frequently used, the biLM (bidirectional language model) will be able to determine that they are linked in some way. Sounds amazing!
Features of ELMo NLP
Regarding ELMo NLP's features, most of the advantages were listed above while discussing the need for ELMo NLP. However, some of the features that stand out in ELMo NLP are:
- Contextual:
Each word's representation is based on the overall context in which it is used. - Deep:
All deep pre-trained neural network layers are combined to create word representations. - Character-based:
Because ELMo representations are entirely character-based, the network can use morphological cues to create reliable representations for tokens that were not observed during training.
Now that you know all about the basics of ELMo NLP, let's create a small project - a similar question finder using ELMo NLP.
Building a Similar Question Finder with ELMo
To get started with a basic project with ELMo NLP in Google Colab, you need to install TensorFlow. Write down the following code to do so:
Post this, you can get started with the project. First, we're going to import all the required libraries. Now, for creating the question embeddings, we are going to make use of ELMo NLP, however, to find similarities between the questions, we will use 'cosine similarity'. To know more about similarity metrics, you can refer to the article on Text Similarity in NLP by Scaler Topics.
Note:
To run this code in Google Colab, you must disable eager execution of TensorFlow as follows - tf.disable_eager_execution.
You must be wondering why we require TensorFlow to run ELMo NLP code. It serves up a ton of pre-trained models for use with TensorFlow while saving you a ton of time. Fortunately for us, ELMo is one of these models. We can import a fully trained model in just a few lines of code.
There, you've imported the ELMo NLP model. By putting trainable=True we can finetune some parameters of the ELMo NLP module. You only need to pass a list of strings in the object elmo to convert any sentence into an ELMo vector.
Output:
- The first dimension of this tensor represents the number of training samples.
- The longest string in the input list of strings is represented by its maximum length in the second dimension.
- The length of the ELMo vector is the third dimension.
We will now extract the ELMo vectors, and then, to arrive at the vector representation of an entire question, we will have to take the mean of the ELMo vectors of constituent terms or tokens of the questions. For this purpose, we're going to create a function.
Now that we have our function ready to calculate vectors, we can define a small corpus of questions for which we want to calculate our similarity. You can take your own set of questions to try out the results of your similar question finder.
The next steps would be to calculate the embeddings and compute similarity using cosine similarity. We will first create a list to store those embeddings and check out their shapes.
Now, to compute the similarity, we will feed these embeddings to a cosine similarity function we imported from sklearn.
There! You've completed your similar question finder. Here's the complete code and output.
Output:
Conclusion
- In this article, we covered one of the prominent modules in natural language processing - ELMo NLP, which stands for Embeddings from Language Models.
- A few primary features of ELMo NLP are that it accounts for the context of words, is trained on a large text corpus nd is open source.
- The architecture of ELMo NLP includes a character-level convolutional neural network in which word vectors are computed on top of a two-layer bidirectional language model. Each layer contains two passes - forward and backward.
- The forward pass takes into account the words that are before the current word and the backward pass takes into account the word that is after the current word.
- Post this, we also reviewed a mini-project using ELMo NLP on a similar question finder where we used tensorflow to load the ELMo NLP module and cosine similarity for finding similarities.