S3 Glacier Select
Overview
Legacy data archival solutions like the on-premise tape libraries restrict the data retrieval response rate and hence are considered unsuitable for rapid analytics or processing which requires weeks for accessing the data stored. Hence, with the AWS S3 Glacier Select, data can be retrieved within minutes via simple SQL queries, achieving drastic performance increases by receiving only the required data filtered through SQL statements. The amount of data that Amazon S3 transfers reduce which eventually helps to cut down on the cost and latency to retrieve this data.
What is Amazon S3 Glacier Select?
With AWS S3 Glacier (S3 Glacier) we can securely, reliably along with offer durable service for its low-cost data archiving and long-term backup. This way you can store the data and exercise effective data cost effectively for months, years, or even decades.
The below diagram shows how Amazon S3 Glacier Select works:
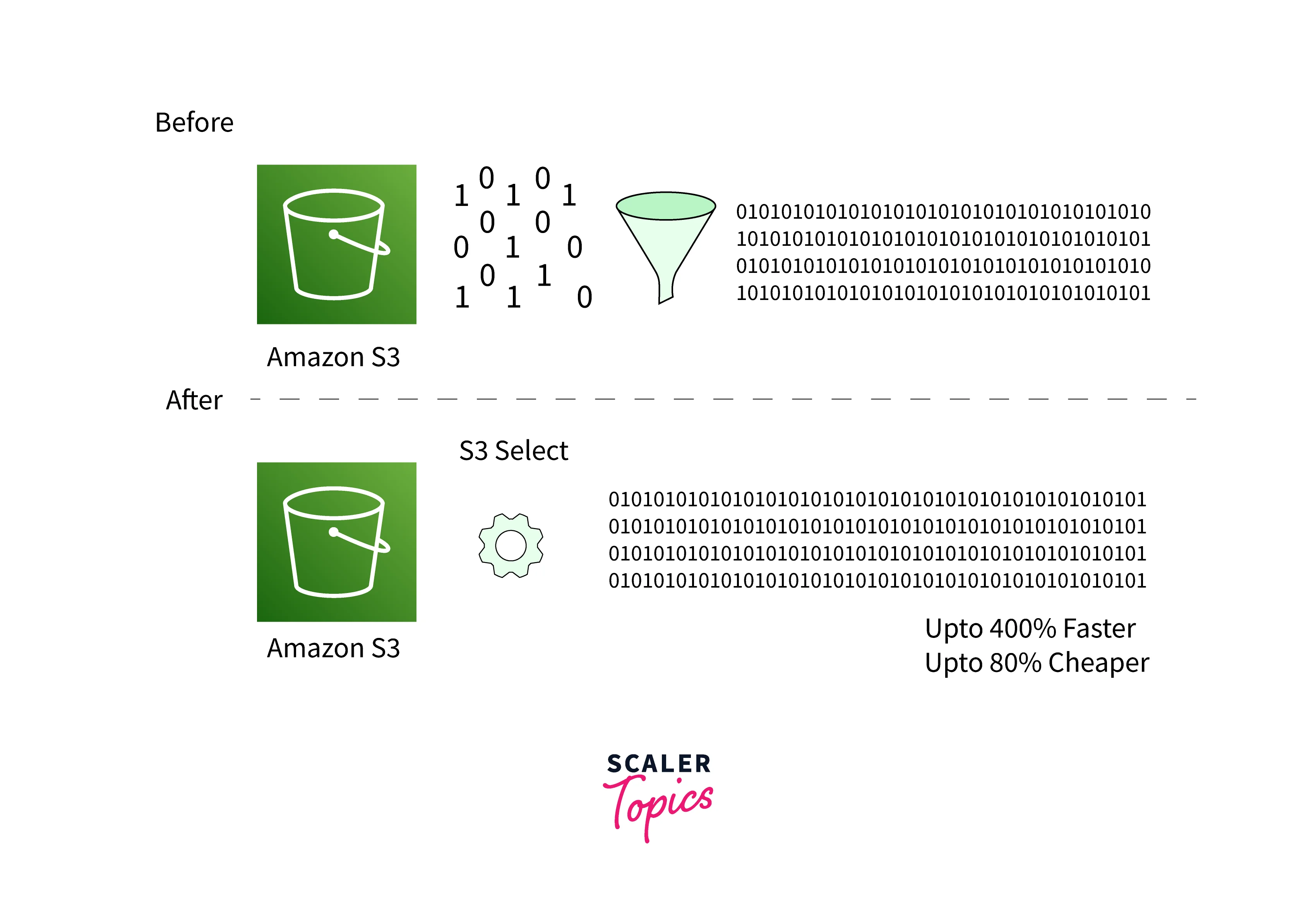
By implementing AWS S3 Select, you can enable applications to retrieve data (only subset) from an object via simple SQL expressions. This way we can achieve drastic performance increases(400% improvement) by filtering the data through SQL statements. The amount of data that Amazon S3 transfers reduce which eventually helps to cut down on the cost and latency to retrieve this data. AWS Glacier Select retrieves the data via the job along with offering an additional set of parameters that can be utilized while passing in an initiate job request.
The Amazon S3 Glacier Select works on objects as it supports a subset of SQL with a format like CSV, JSON, or Apache Parquet format. Objects compressed with GZIP or BZIP2 (for CSV and JSON objects only), and server-side encrypted objects can also be retrieved. We need to pass easy and simple SQL expressions to Amazon S3 as a part of the request. These SQL queries can be operated using Amazon SDKs, the SELECT Object Content REST API, the Amazon Command Line Interface (Amazon CLI), or the Amazon S3 console.
Below shows an example of how you can retrieve the first column containing data in CSV format from an object.
Below shows an example of how you can also process the data retrieval request via a simple SQL statement.
Several highly regulated industries companies such as Financial Services, Healthcare, and others, are implementing the AWS S3 Glacier Select for writing the data directly to the Amazon Glacier by satisfying compliance needs (SEC Rule 17a-4 or HIPAA). When the data is no longer needed for accessing regularly then AWS S3 can support the lifecycle policies for storage cost saving by moving into the AWS Glacier.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Requirements for Using S3 Glacier Select
The requirements for using Amazon S3 Glacier Select are listed below:
-
It's always recommended to use the https along with providing the encryption key in the request, whenever the object that you are querying is encrypted with a customer-provided encryption key (SSE-C).
-
Always have the 's3:GetObject' permission for the object that you shall be querying for.
Limits for Using S3 Glacier Select
The limitations that must be kept in mind while working and implementing the Amazon S3 Glacier Select are as listed below:
- You can only emit the nested JSON output format for your data when you implement the Amazon S3 Glacier Select.
- 256 KB is the maximum defined length of a SQL expression.
- No modification or change is allowed for the S3 Glacier Select Flexible Retrieval, S3 Glacier Select Deep Archive, or REDUCED_REDUNDANCY storage classes.
- 1 MB is the maximum length of a record provided either in the input or result.
Some additional limitations that can somehow also apply when using Amazon S3 Glacier Select having the Parquet objects (data type) are listed below:
- 512 MB is the maximum uncompressed row group size.
- The output format must be defined as either CSV or JSON. It must be noted that AWS S3 Glacier Select doesn't support Parquet output.
- The data types specified in the object's schema must be used.
- When you select a repeated field, helps to return only the last value.
- By implementing and using the GZIP or Snappy, the Amazon S3 Glacier Select supports only columnar compression. The whole-object compression is not supported by Amazon S3 Glacier Select for Parquet objects.
Constructing a Request
Once you start using the AWS S3 Glacier Select, you may need to start constructing the request. Here you need to provide details of the object which is getting queried using an InputSerialization object. You use the OutputSerialization object to provide details about how you want the results to be returned. For this, you could also include the SQL expression to filter the request.
QuickNote: InputSerialization can be defined as the format of the data(which needs to be quired) in the object. OutputSerialization can be defined as the format of the data that you shall receive in response to the Amazon S3 request.
With the SelectObjectContent, you can filter the contents ( or elements) of an Amazon S3 object using the easy structured query language (SQL) expression. You need to provide the data serialization format (such as JSON, CSV, or Apache Parquet) of the object. Then the AWS S3 implements this format to parse the object data into records, and in response obtains the records which matched the defined SQL expression. Mandatorily always defined the data serialization format for the response you should be receiving.
For example, Suppose you want to receive a record from an object with data stored in JSON format by using the select request. Here, the OutputSerialization shall point to the Amazon S3 to return the output in CSV format.
Different queries in the Expression element can be as follows:
Filter using record keys by string comparison:
Define functions in the SQL queries:
Sample request: Case 1-JSON object
Output:
Sample request: Case 2-CSV object
Output:
Sample request: Case 3-Parquet object






Errors While Using Amazon Glacier Select
While working with Amazon S3 Glacier Select, you sometimes might end up encountering an error along with the associated error message when an issue comes up, while you are expecting any query.
SELECT Object Content returns a few of those listed below:
| Error Code | Description | HTTP Status Code | SOAP Fault Code Prefix |
|---|---|---|---|
| Busy | The service is unavailable. Try again later. | 503 | Client |
| CastFailed | An attempt to convert from one data type to another using CAST failed in the SQL expression. | 400 | Client |
| ColumnTooLong | The length of a column in the result is greater than maxCharsPerColumn of 1 MB. | 400 | Client |
| IllegalSqlFunctionArgument | An illegal argument was used in the SQL function. | 400 | Client |
| InternalError | An internal error occurred. | 500 | Client |
| InvalidColumnIndex | The column index in the SQL expression is not valid. | 400 | Client |
| UnsupportedSqlStructure | We encountered an unsupported SQL structure. Check the SQL Reference. | 400 | Client |
For more information on the various error codes and their detailed descriptions, please visit the SelectObjectContentErrorCodeList in the Amazon Simple Storage Service API Reference.
SQL Reference for Amazon S3 Select
Let us, deep dive, into how the SQL reference contains the description of the SQL elements supported by Amazon S3 Glacier Select. Below the topic, we shall cover to understand how the data is retrieved easily via the SQL expressions.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
SELECT Command
The SELECT SQL command is only supported by Amazon S3 Glacier Select. The ANSI standard clauses supported for the SELECT command are listed below:
- SELECT list
- FROM clause
- WHERE clause
- LIMIT clause
Let us, deep dive, into each to get. better understanding:
SELECT list:
To obtain the output, you can use the SELECT list that helps to list the names of the columns, functions, and expressions. The output result of the query is represented by the list.
FROM clause:
Below listed form of the FROM clause is supported by AWS S3 Glacier Select:
By the standard SQL, the FROM clause when used creates the (filtered by WHERE clause) rows that are projected in the SELECT list.
For JSON objects following forms of the FROM clause are used:
WHERE clause:
The syntax followed for the WHERE clause:
LIMIT Clause:
The syntax followed by the LIMIT clause:
Reserved Keywords
The list of reserved keywords(including the function names, data types, operators, etc.,) required to execute the SQL queries to query object content for Amazon S3 Select is given below:
SQL Functions
Several SQL functions supported by AWS S3 Glacier select are listed below:
-
Aggregate Functions:
-
Conditional Functions:
-
Conversion Functions:
-
Date Functions:
-
String Functions:
Turn Learning into Career Growth
Conclusion
-
The AWS S3 Glacier Select data can be retrieved within minutes via simple SQL queries, achieving drastic performance increases(400% improvement) by receiving only the required data filtered through SQL statements.
-
Only 40 MB of the data can be returned via Amazon S3 console where if the scenario requires more amount of data then Amazon CLI or the API is recommended.
-
The SELECT list helps to list the names of the columns, functions, and expressions. The WHERE clause filters the rows based on the defined condition. The LIMIT clause when you want to limit the number of records that a query shall obtain based on the number you specify.
-
By the standard SQL, the FROM clause when used creates the (filtered by WHERE clause) rows that are projected in the SELECT list.