Glossary of DBMS

You may be studying DBMS because it is a college topic or because you are interested in learning it for a variety of reasons. Whatever the source of your interest, having all of the vocabulary you need to master this subject in one location would be a blessing. This is the one-stop glossary for all things DBMS.
1 - tier architecture
In this form of DBMS architecture, the user is in direct touch with the database, i.e. they can directly access and modify the original database. It is typically utilized in the creation of local applications where developers may make direct modifications to the database.
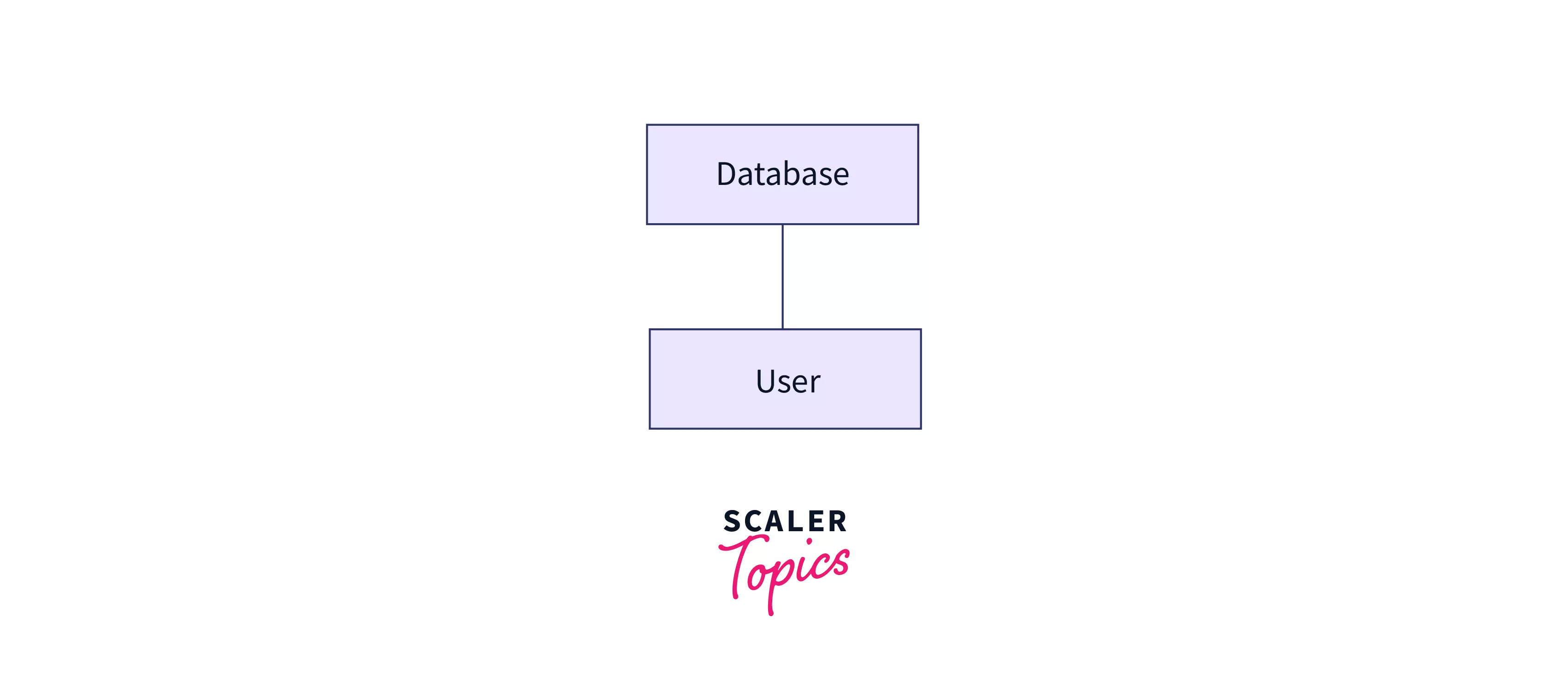
2 - tier architecture
Also known as a simple client-server architecture, this structure has 2 major components - a server that holds the database and a client on which programs run and can directly connect with the server. All UIs and programmes run on the client side, while the server side is in charge of providing capabilities like as query processing and transaction management.
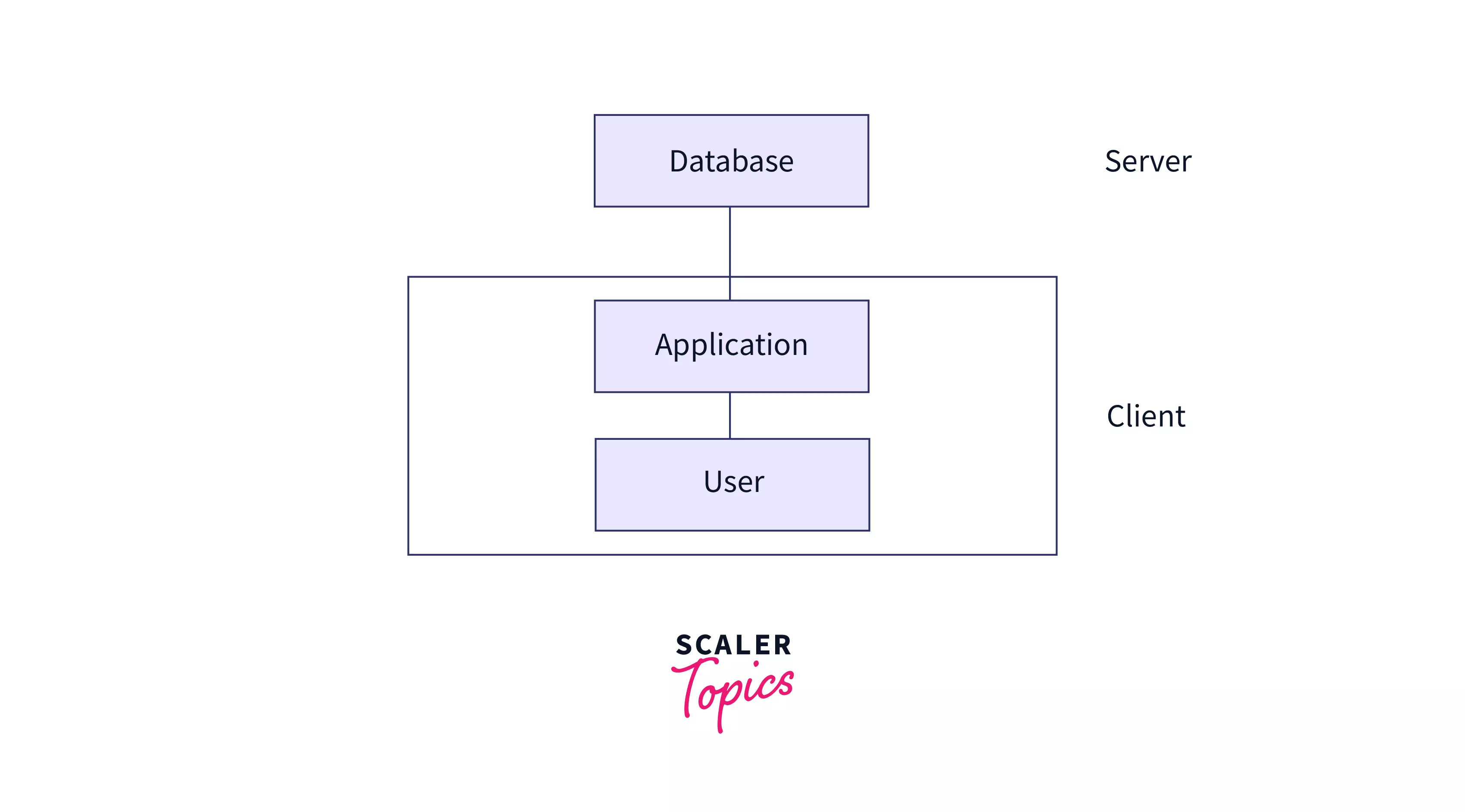
3 - tier architecture
A 3-tier architecture is an embodiment of a client-server system with a middle layer that holds code that defines business rules and consolidates access to various transaction servers. Unlike, 1-tier and 2-tier architectures, the client cannot interface directly with the database systems under this structure. Beyond the application server, the end user is unaware of the presence of the database.
ACID Properties in DBMS
It is necessary that the database remains intact before and after a transaction. ACID in ACID property is an abbreviation that represents the four properties of a safe transaction: atomicity, consistency, isolation, and durability.
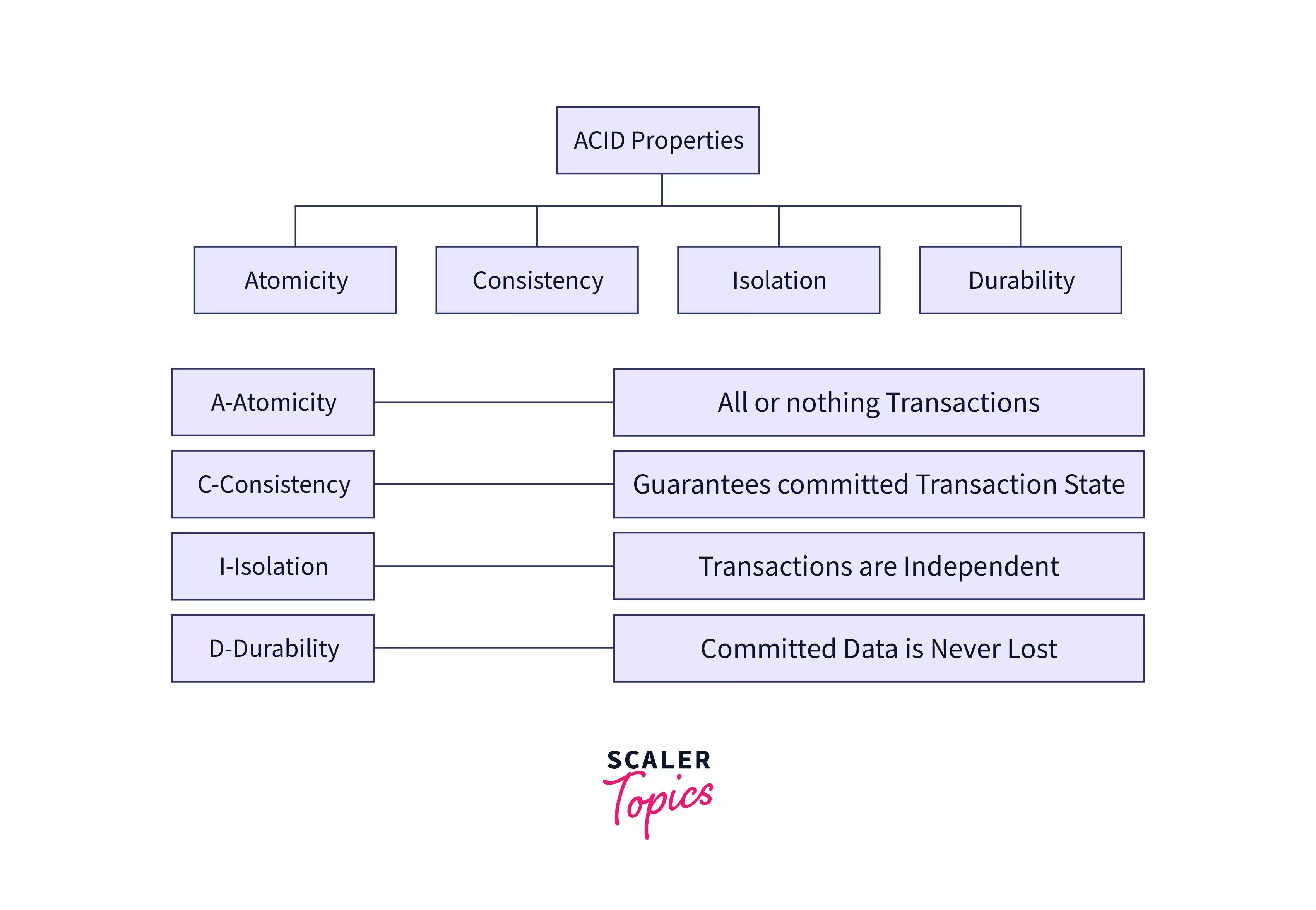
a. Atomicity - As the name suggests, this property requires every part of a transaction to be completely executed, i.e., for a successful transaction, either all operations in a transaction succeed together, or fail together. For example, if you were to order a parcel on Amazon and have shared your building number, street, and city on the portal for delivery purposes. The whole address will be considered as atomic. For successful delivery (transaction), Amazon must share the entire address with the delivery partner. If only a part of it (e.g. street name) is shared, it will be a non-atomic transaction. Check out this article to read more about Atomicity in DBMS.
In the example given below, we have 2 transactions: T1 of debit from Account A that has $50 in it and T2 of credit to Account B that has $100 in it. In Case 1, T1 succeeds but T2 fails. Thus, the transaction is non-atomic and thus fails. In Case 2, T1 and T2 both succeed in maintaining atomicity. Thus, the transaction is successfully completed.
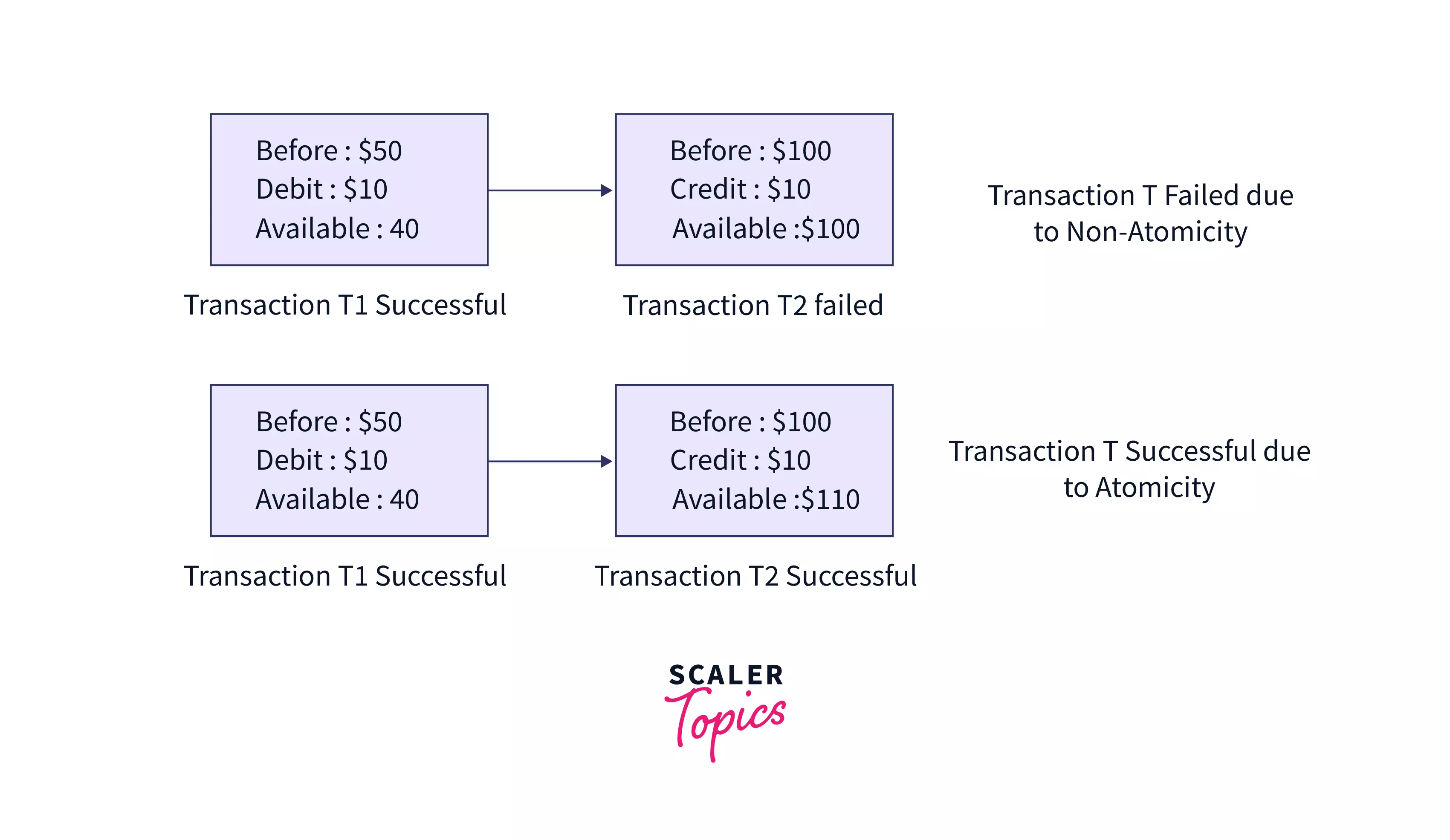
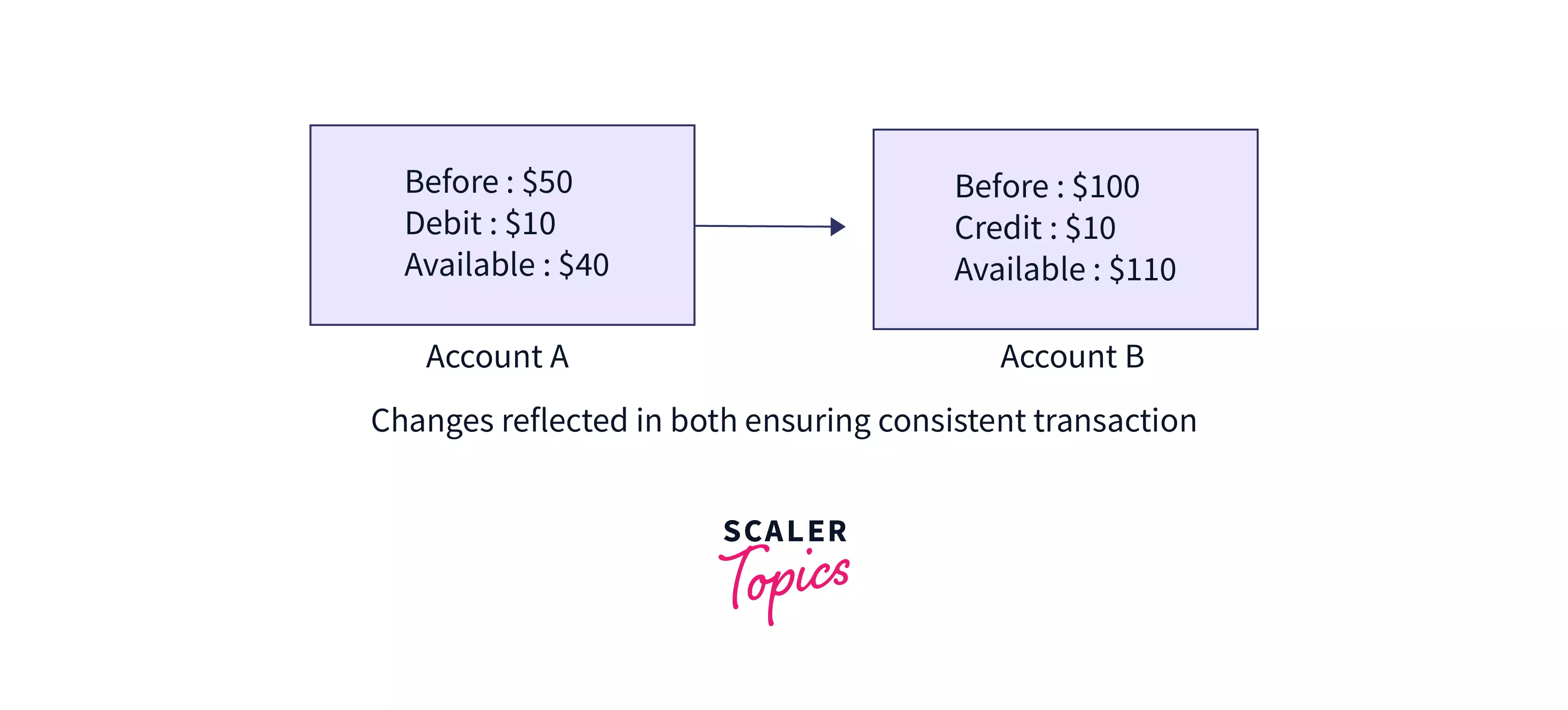
b. Consistency – This means that the integrity of the data in consideration needs to be preserved, i.e. all data must be consistent before and after the transaction.
For Example: Consider a game of Chinese Whispers. A message is passed around as every person whispers it to the next in line until it reaches the last person. The last person then tells out the message loud. If the final message is the same as that passed by the first, the transaction can be considered as consistent. If there is a mismatch somewhere in the line, we will witness inconsistency. Given below is an example of inconsistency in a game of Chinese Whispers.

Consider an example of a consistent transaction as given in the figure.
c. Isolation – This property ensures that multiple transactions can occur simultaneously in isolation, i.e. without interfering in each other's operations.
d. Durability - This property states that when a transaction is committed, all changes are permanently preserved even if hardware or system failure occurs.
Aggregation or Aggregate Function
A term used for a number of SQL operations that work on the selected rows. SUM, COUNT, MIN, MAX, and AVERAGE are common examples of aggregate functions. Learn more about Aggregation in DBMS.
Alias
A temporary name is given for a table or a column for ease of access by the user. This is commonly used when referring to the same table more than once, like in a self-join. The following image shows an example of how aliases can be used for columns and tables for ease of use.

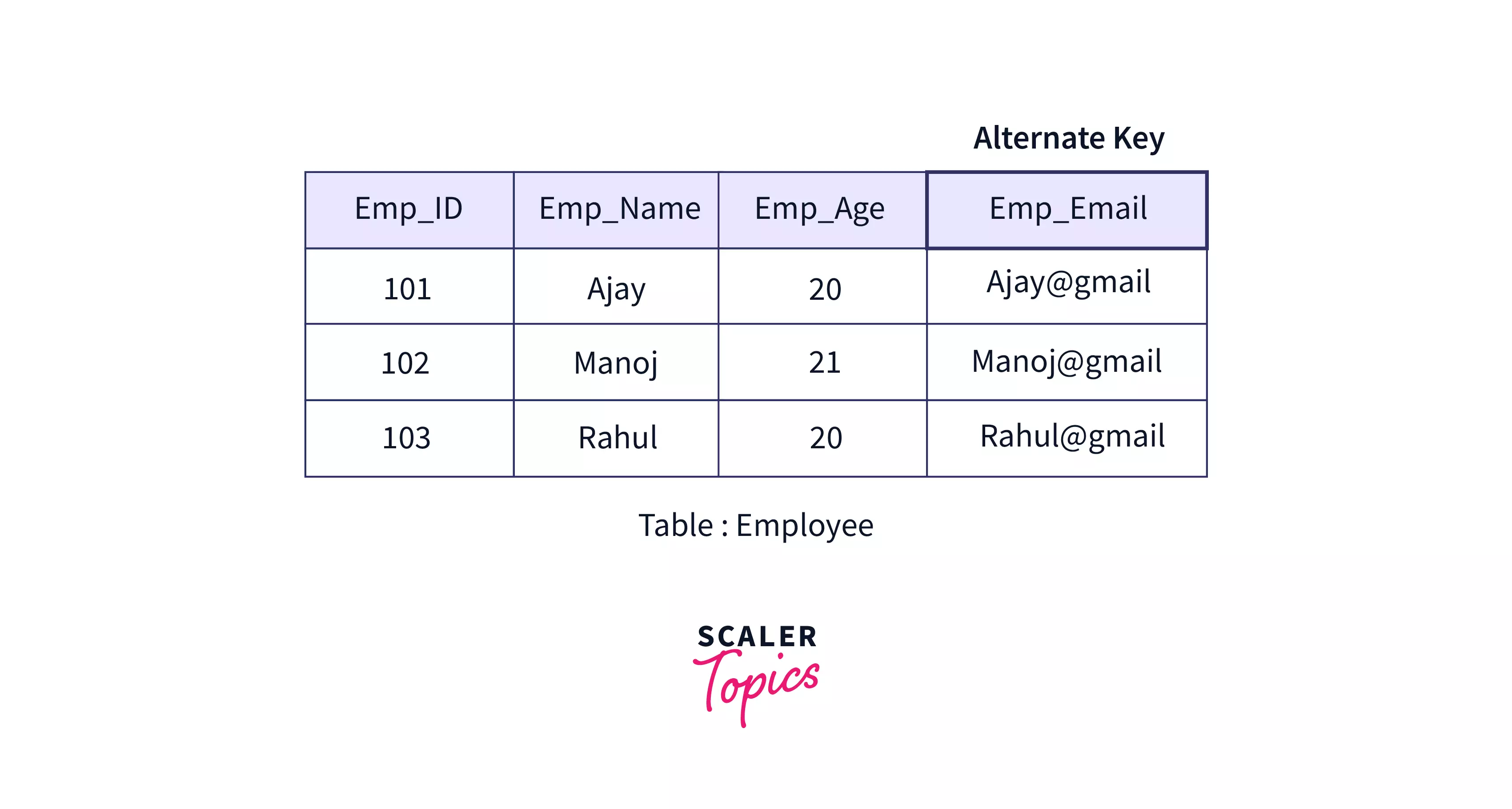
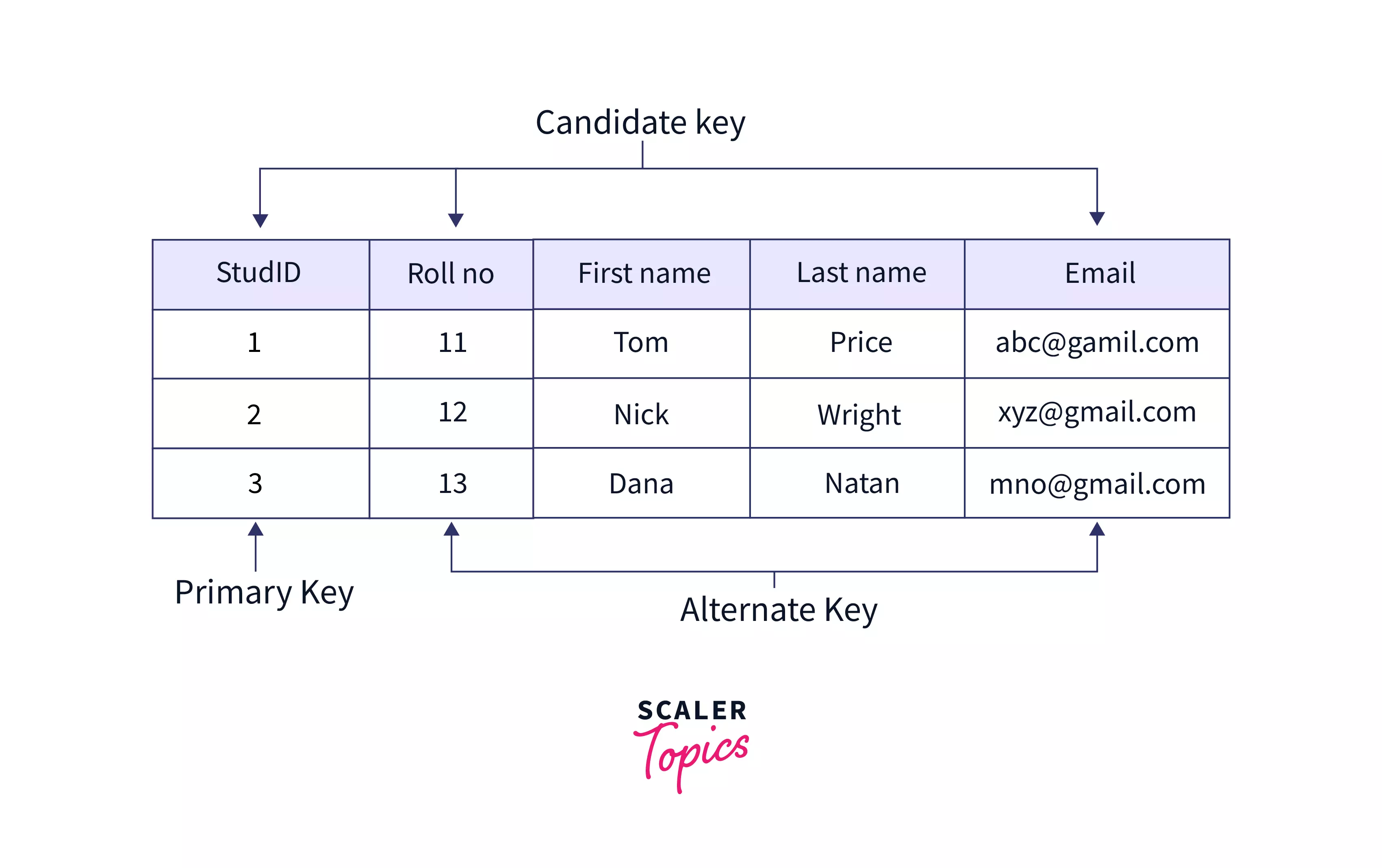
Alternate Key
An alternate key is a key that is a candidate but not the primary key. Consider the following example of an employee table that has Emp_ID as the primary key. Here Emp_EmailID will also be unique for every employee and although it can be used to identify every row in the table, it is not the primary key. Hence, Emp_EmailID is an alternate key.
Anomalies
Anomalies occur when something abnormal happens. In DBMS, these are considered as taboos. Once this occurs, they cause a lot of problems in the future. They are usually caused when there is redundancy in information and are often caused when the tables that make up the database suffer from poor construction.
There are various types of anomalies:
a. Update anomaly: An update anomaly is caused when data is updated at one instance and not at others.
b. Insert anomaly: An Insert Anomaly is caused when attributes cannot be inserted into the database without the presence of other attributes. This usually occurs when a child is inserted without a parent.
c. Delete anomaly: A Delete Anomaly is caused when the deletion of one attribute causes the deletion of some other attributes.
To overcome these anomalies in DBMS, we need to normalize the data.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
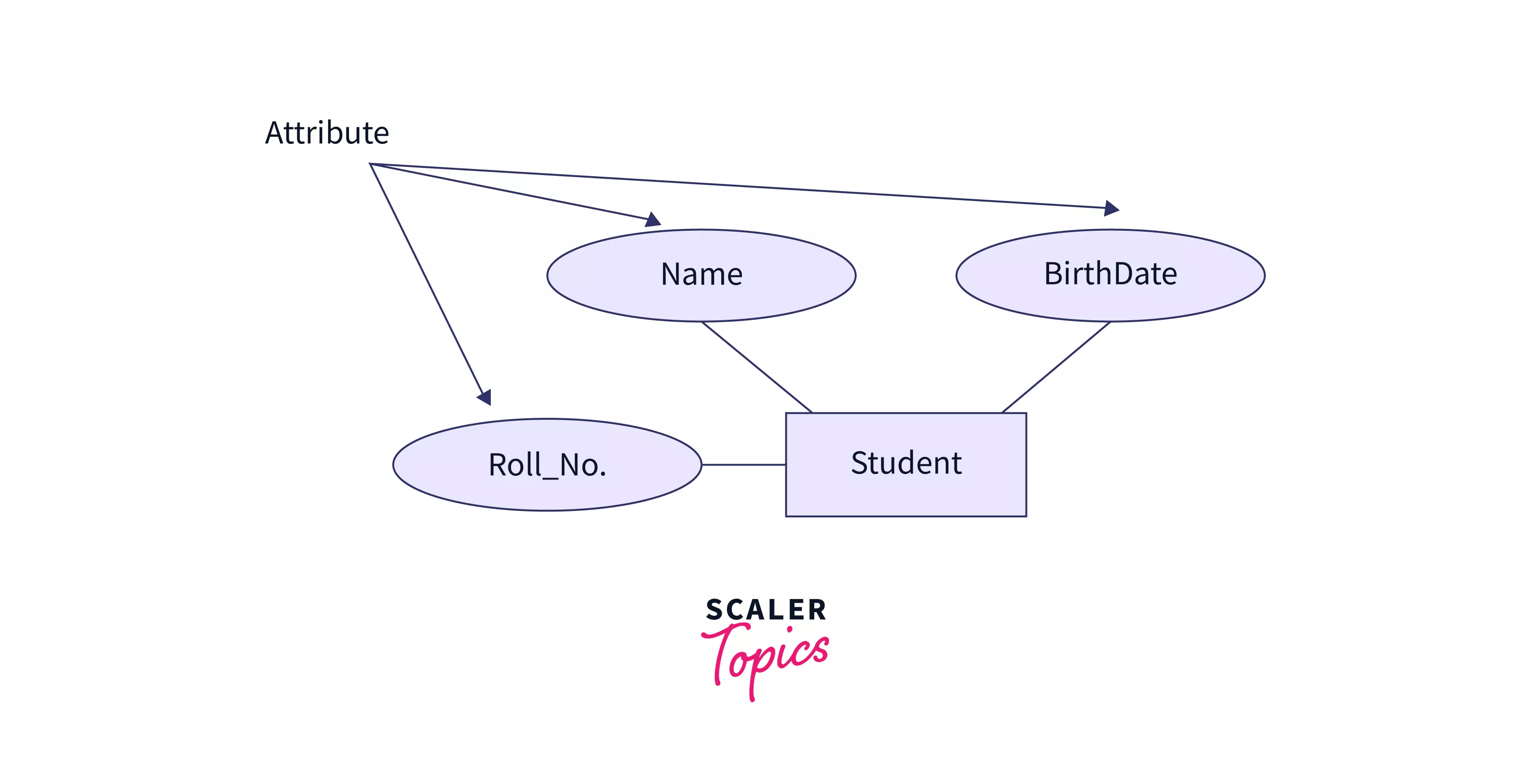
Attribute
A column in a table or relation is called an attribute. They are the properties/features that define a relation. Eg: In a student table, Name, Roll_No, and BirthDate are attributes.
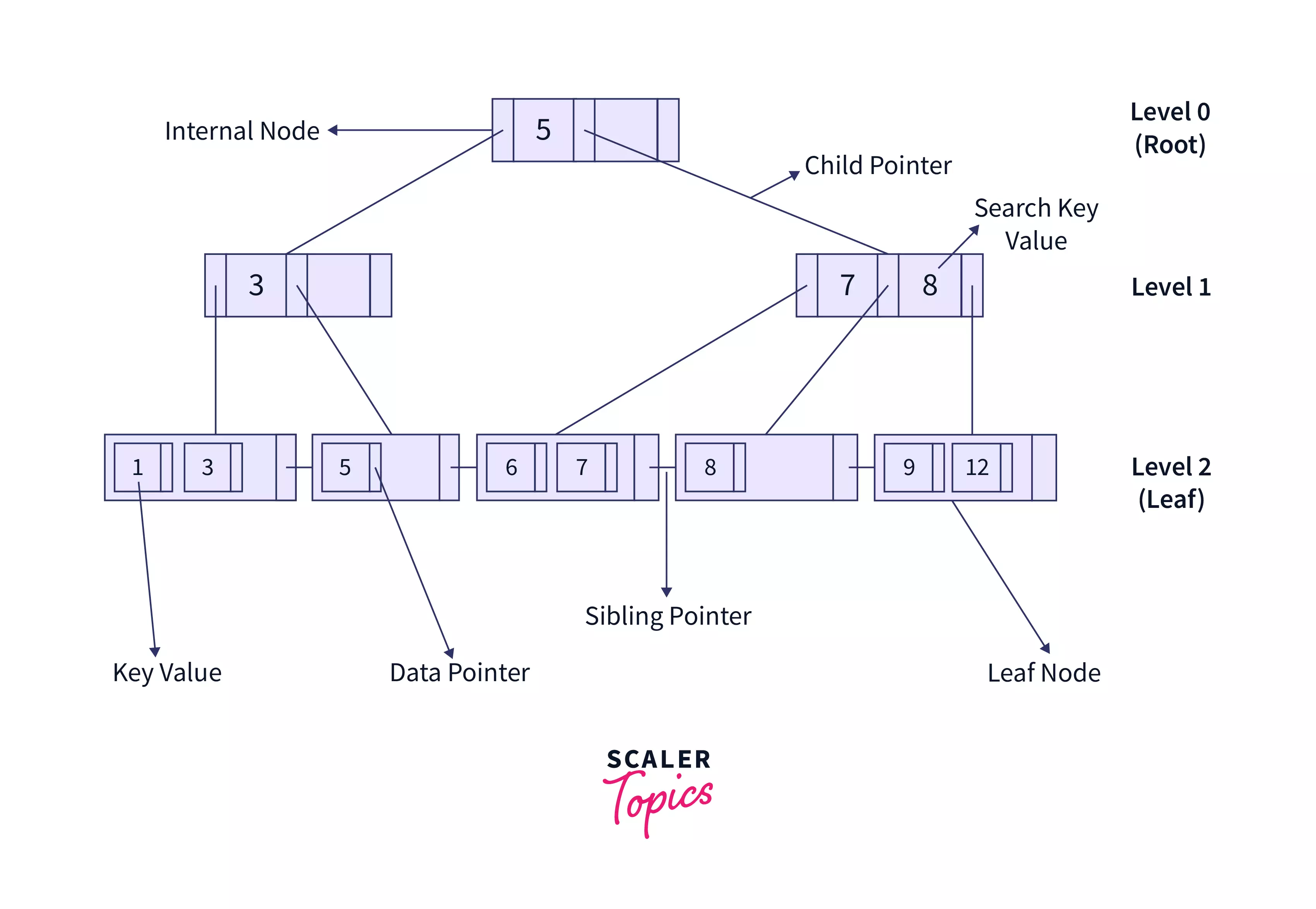
B+ Tree
A B+ tree in DBMS is an advanced form of a B-tree that eases insertion, deletion, and search of elements due to its balanced nature. Unlike a B-tree, it stores data pointers only at leaf nodes. Due to their structure, DBMS querying is based on these. The following diagram shows the structure of a B+ Tree.
Boyce-Codd Normal Form (BCNF)
A kind of normalization technique that is based on functional dependencies. All these dependencies must be explicitly shown through candidate keys. It is an extension to 3NF and takes some additional constraints into consideration too. Learn more about BCNF in DBMS.
Candidate Key
Set of columns with unique values in a table that can uniquely identify a row is called a candidate key. To learn more about the Candidate key in DBMS, click here.
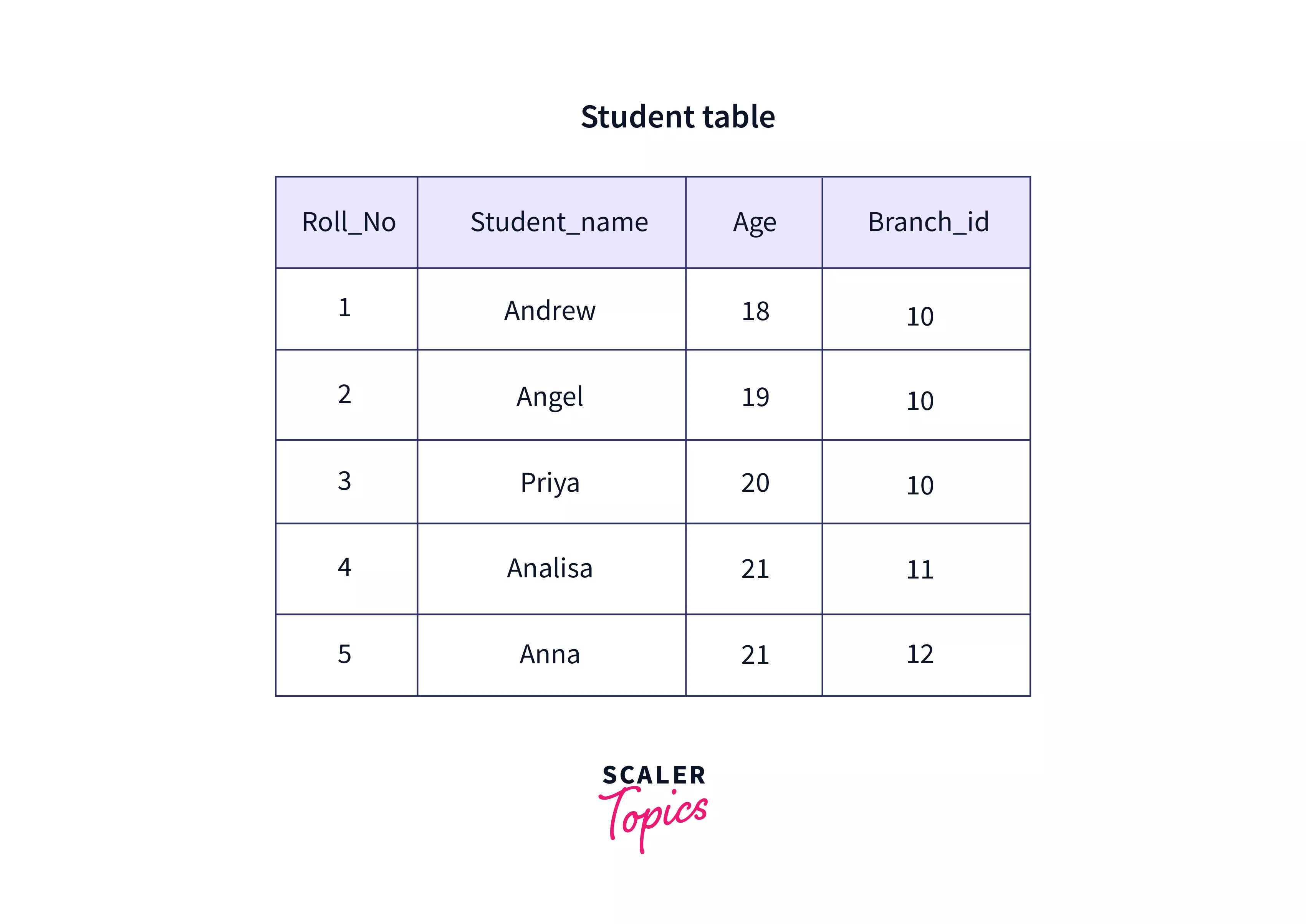
Cardinality
It is a numerical value that represents the number of rows present in a table or relation. In the table given below, the cardinality is 5.
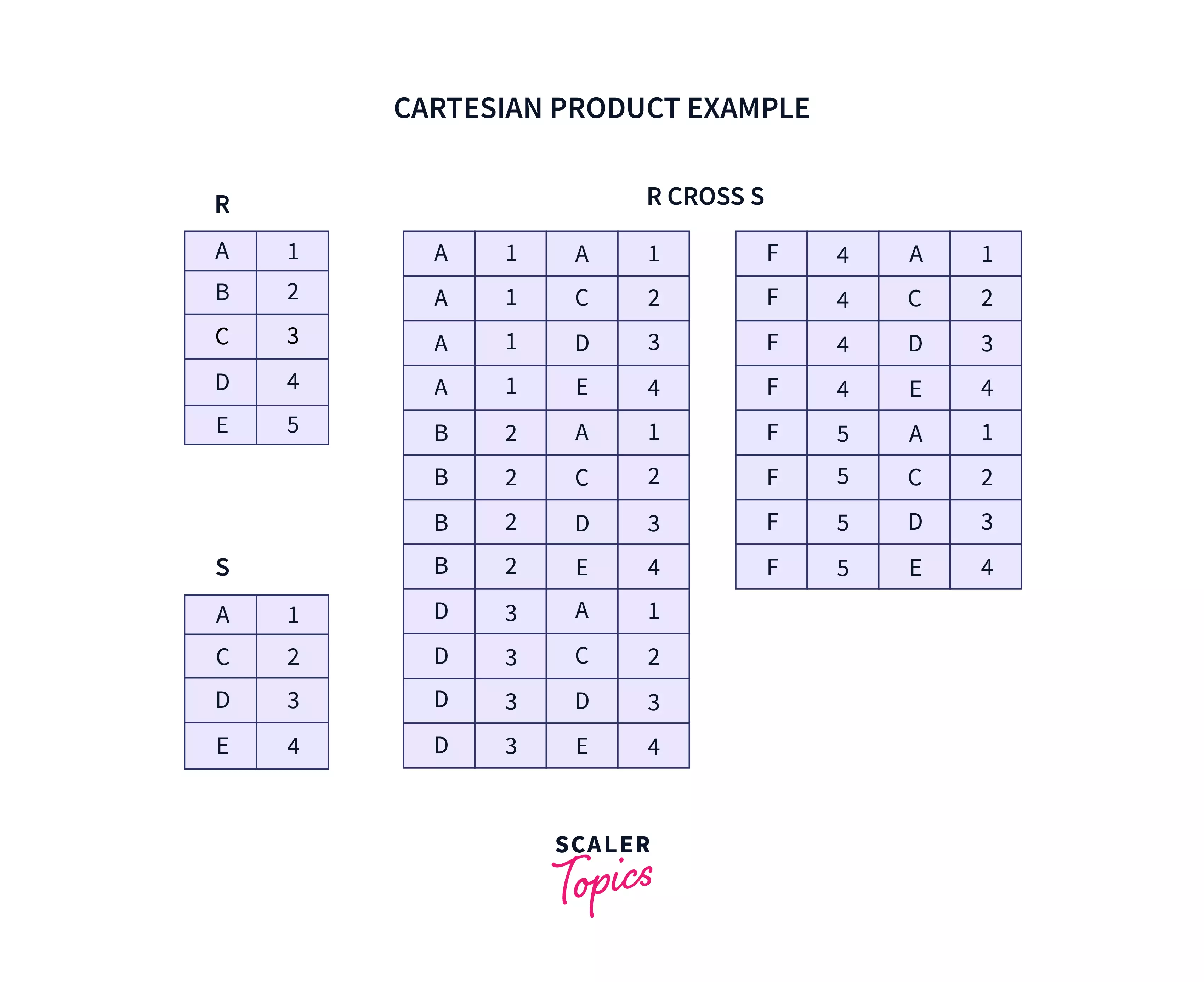
Cartesian Product / Cross Join
Cartesian product or Cross Join returns a number of rows equal to a number of rows in the first table multiplied by the number of rows in the second table. At the same time, it contains the number of columns equal to a number of columns in the first table added by a number of columns in the second table. The following example shows how a cartesian product can be obtained for 2 tables R and S.
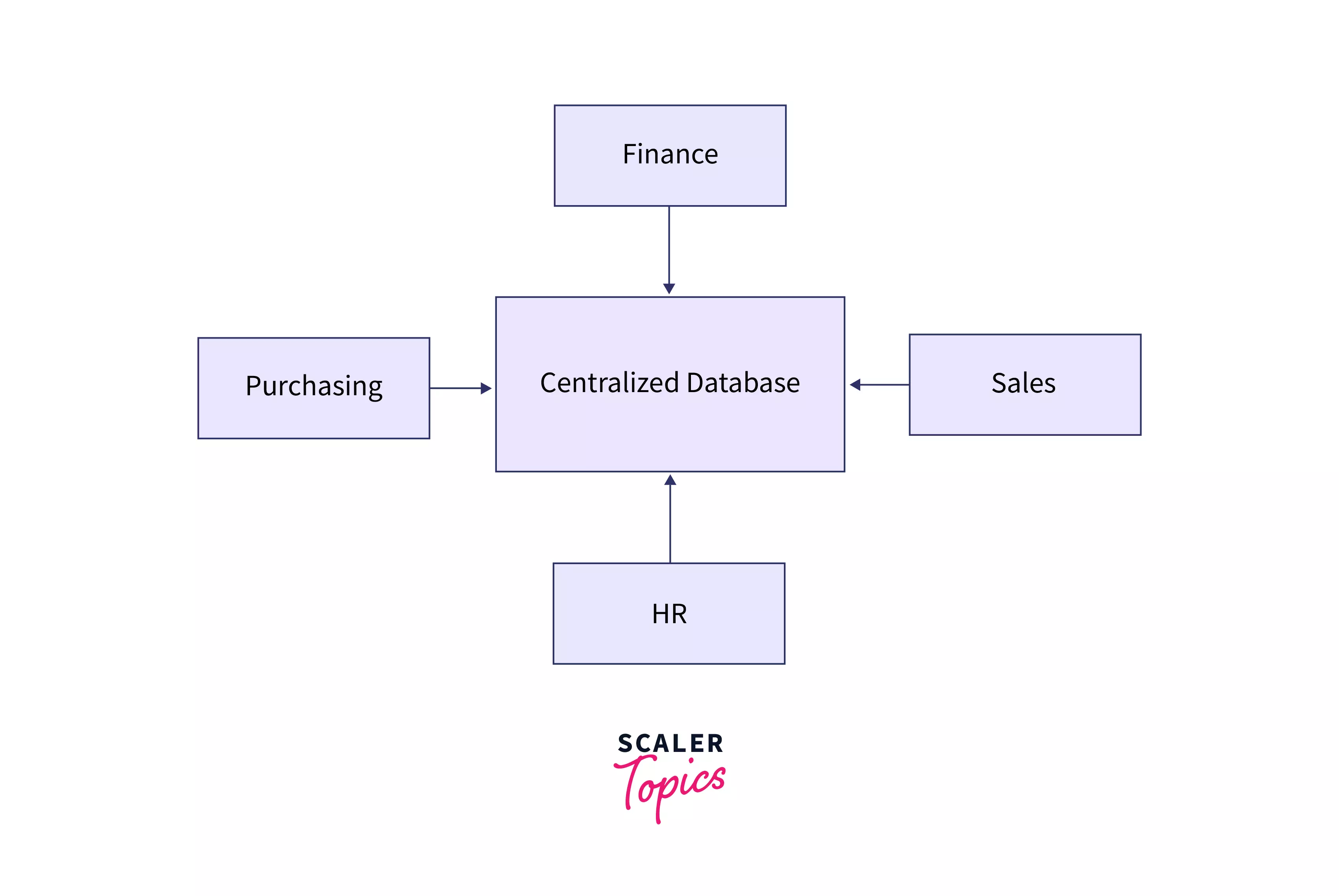
Centralised Database
A database that is stored at a single/centralized location and further accessed and modified from it. The access can be done using LAN/WAN/MAN. These are commonly used in offices, colleges, government offices, etc. As shown in the below diagram, various departments within the same company access the same centralized database for various purposes.
Cloud Database
A database that is developed and accessible via a cloud platform. It performs many of the same responsibilities as a traditional database but with the extra benefit of flexibility provided by cloud computing. To implement the database, users install software on a cloud infrastructure.
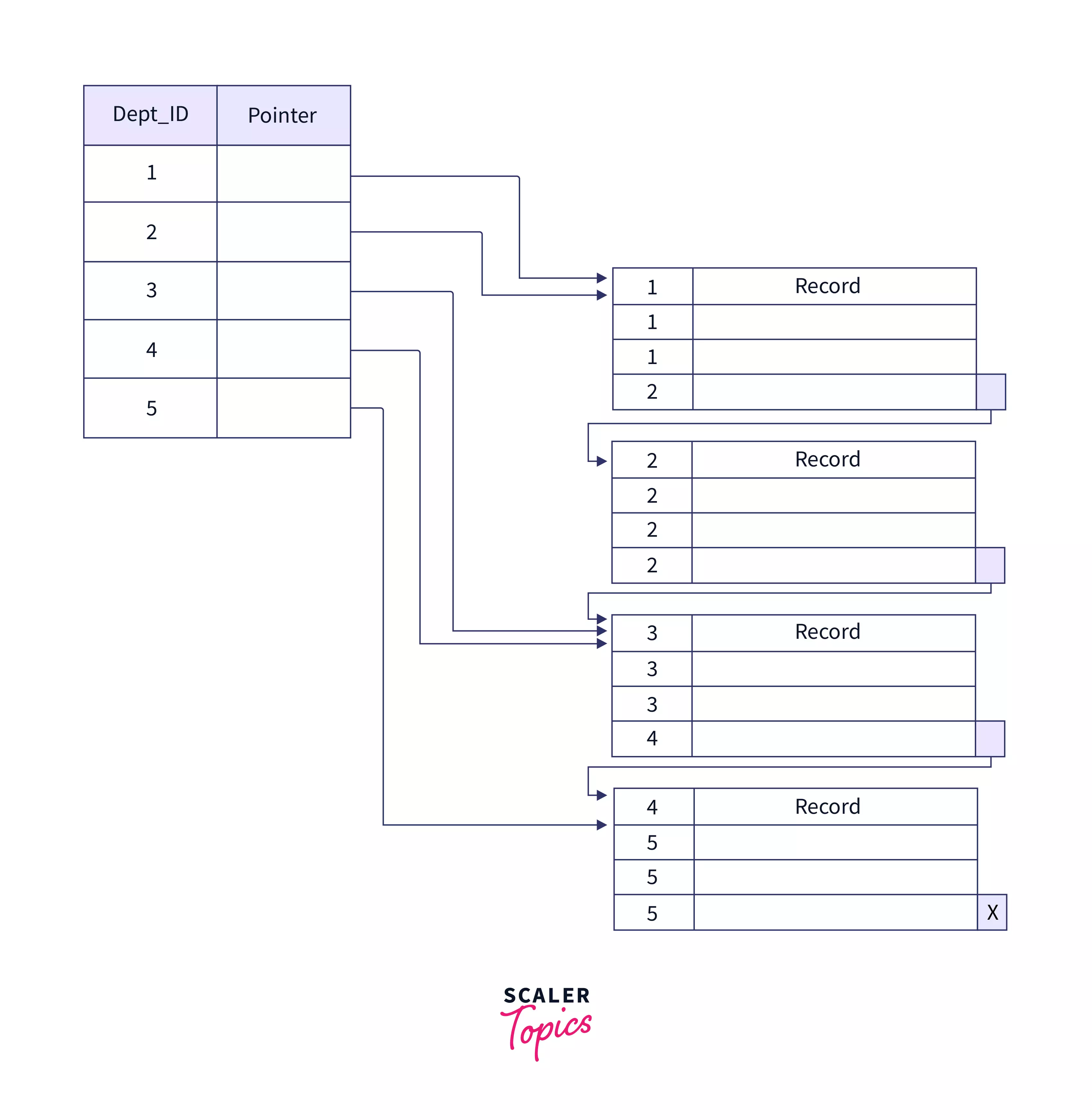
Clustering Index
An index that reorders the order in which records in a table are physically stored on disk. It is built around non-primary key columns that may or may not be unique for each record. Records with similar characteristics are grouped, and indexes for these groups are created. It sorts and saves the data rows in the table or view according to their key values. It is basically a sorted replica of the data in the indexed columns.
Consider a teacher's table consisting of Dept_ID that is being used as a clustered index. There will be a lot of teachers who belong to the same department. Thus, Dept_ID can be used to identify various teacher records belonging to the same department as shown below.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Codd Rules
12 principles developed in 1993 by Dr. E.F. COdd which resulted in the redefinition of the requirements for OLAP (Online analytical processing) tools. The rules are as summarized below:
- Multi-dimensional conceptual view of the database
- Concept of transparency
- Concept of accessibility
- Consistent reporting performance
- Client-server architecture
- Generic dimensionality
- Dynamic sparse matrix handling
- Multi-user support
- Unrestricted cross-dimensional operations
- Intuitive data manipulation
- Flexible reporting
- Unlimited dimensions and aggregation levels
Commercial Database
Paid/commercialized versions of massive databases built specifically for people who wish to access the material for assistance. These databases are subject-specific, and it is not feasible to save such a large amount of data. Commercial links allow access to such databases.
Commit
You commit when you are sure of something. In DBMS, a commit marks the successful completion of a transaction. A commit means that you are telling the SQL server that all the changes that you made to the database should be permanent.
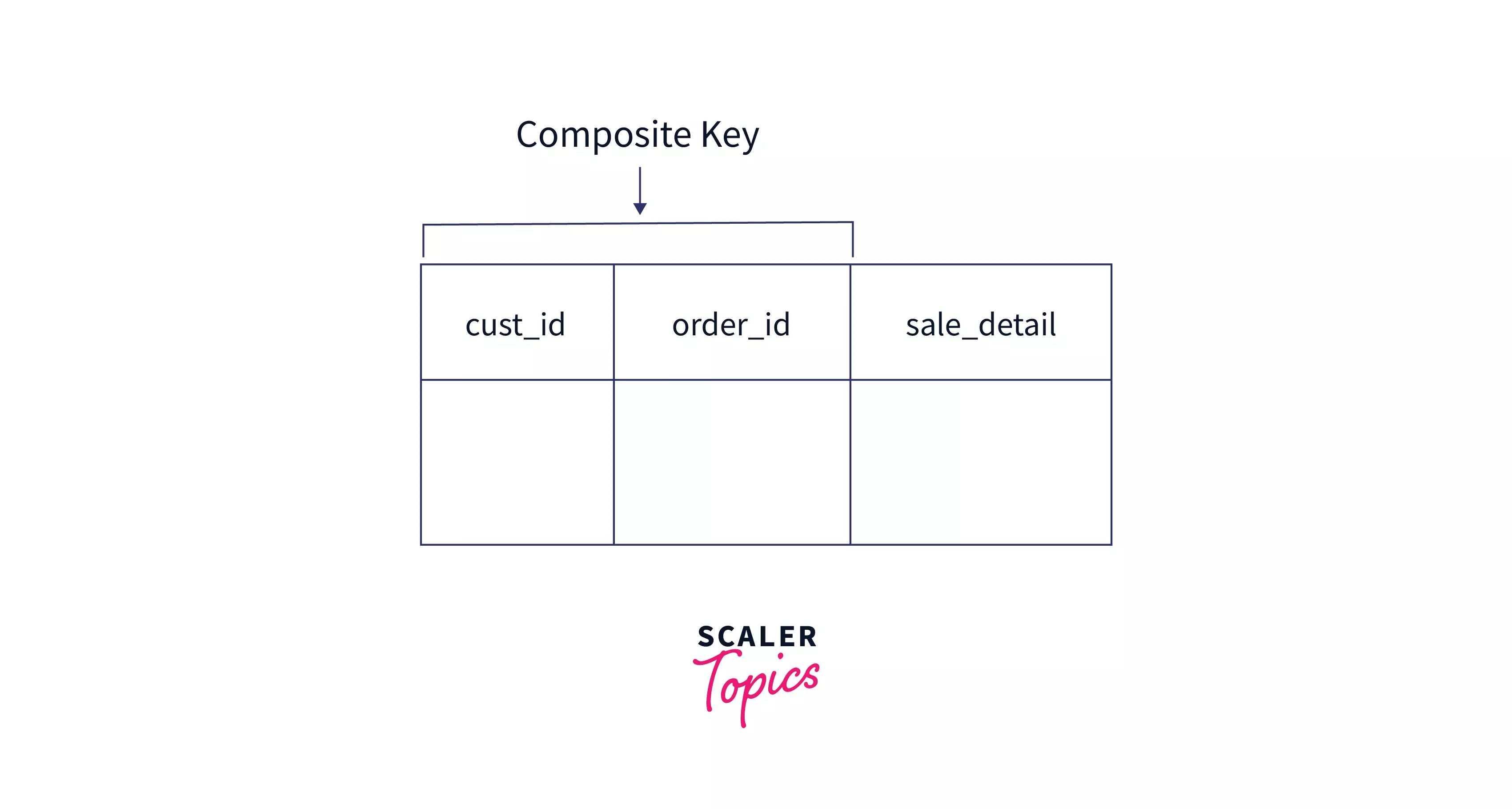
Composite Key
A composite key is a primary key that consists of more than one column, i.e. when 2 or more columns can be combined in a way that their combination is unique across rows and it acts as a primary key. It indicates a many-to-many relationship between the columns.
Concurrency Control in DBMS
Concurrency control is a process in DBMS that ensures that if 2 operations are simultaneously occurring, they won't interfere with each other. It ensures the data integrity of the database.
Conditional Join
Using conditional join, you can join a single column from a table with one or more columns from another based on a condition.
Conflict Serializability
This concept helps recognize non-serial schedules that maintain consistency. A non-serial schedule is said to be conflict serializable if on some swapping non-conflict operations it can be transformed into a serial one. Check out this article to learn more about Conflict Serializability in DBMS.
Constraint
Constraint is a rule/condition that is forced on data to alter the result obtained. There can be constraints in the Select operation in SQL that determines which rows are displayed.
Data
Raw facts and figures, or unorganized facts that need to be compiled to form meaningful information.
Data Mining
Digging deep into and searching databases for unknown patterns and information that can provide valuable insights.
Data Models
These portray a logical representation of the structure of the database, showing different entities, attributes, and their relationships with one another. The Entity-Relationship Model and Relationship Model are the most commonly used data models in DBMS.
Data Storages
In a DBMS, data records are stored on files that are further stored on disks. The storage is done in a way so that access to data is easy.
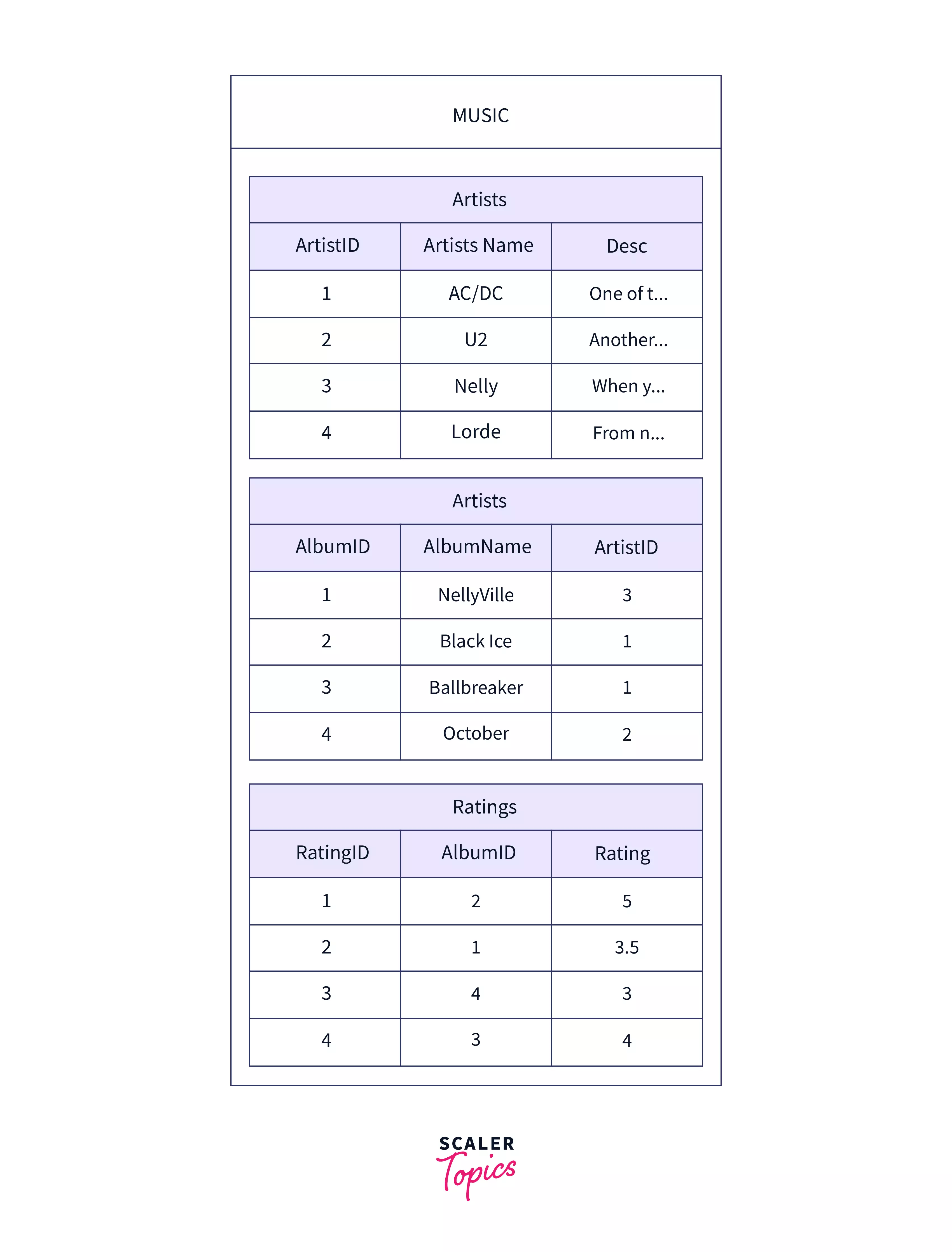
Database
A collection of related tables that contain data stored in a uniform and standardized manner. The tables usually consist of data for a particular application. For example, a school database can have students, teachers, and faculty tables that contain details of the respective groups. The following example shows a music database with tables Artists, Albums, and Ratings.
Database Management System (DBMS)
Software that is used to manage (define, store data, support queries, give reports, etc.) databases. Eg: Oracle, MySQL, etc.
DBMS Architecture
Database architecture is a graphical depiction of a database management system (DBMS) design. It aids in the design, development, implementation, and upkeep of the database management system. A DBMS architecture enables the database system to be divided into discrete components that may be adjusted, changed, replaced, and altered individually.
Data Control Language (DCL)
A component of SQL, DCL is a computer language that is used to manage database privileges. All database activities, such as creating sequences, views, or tables, need the use of privileges.
Data Definition Language (DDL)
A language that allows the user to specify data and how it relates to other kinds of data. Data Definition language statements interact with the database table structure. For example: Create, Alter, Delete, and Drop
Deadlocks
A deadlock in DBMS creates an undesirable scenario in which two or more transactions wait forever for each other to release locks. Deadlock is one of the most dreaded DBMS problems since it brings the entire system to a standstill. Consider Transactions`` T1 and T2. T1 has a lock on some rows in Table A and wants to update rows in Table B while T2 has a lock on rows in Table B and wants to update rows in Table A. Both of these will indefinitely wait for each other to release their locks, thus causing a deadlock.
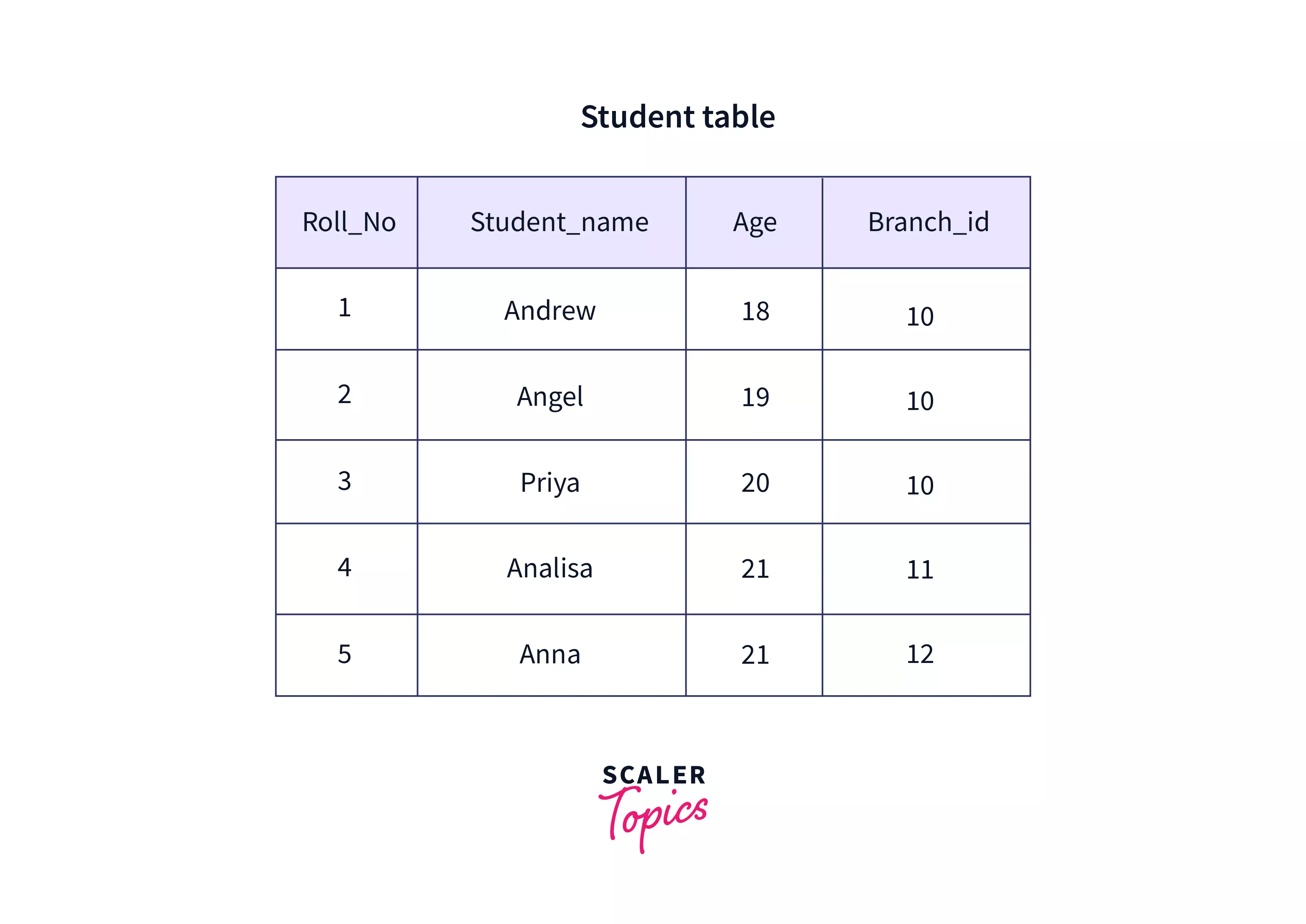
Degree
It is a numerical value that gives the total number of attributes in a relation (table). In the table given below, the degree is 4.
Deletion Time
Total time taken to find a particular item, delete it and then update the database.
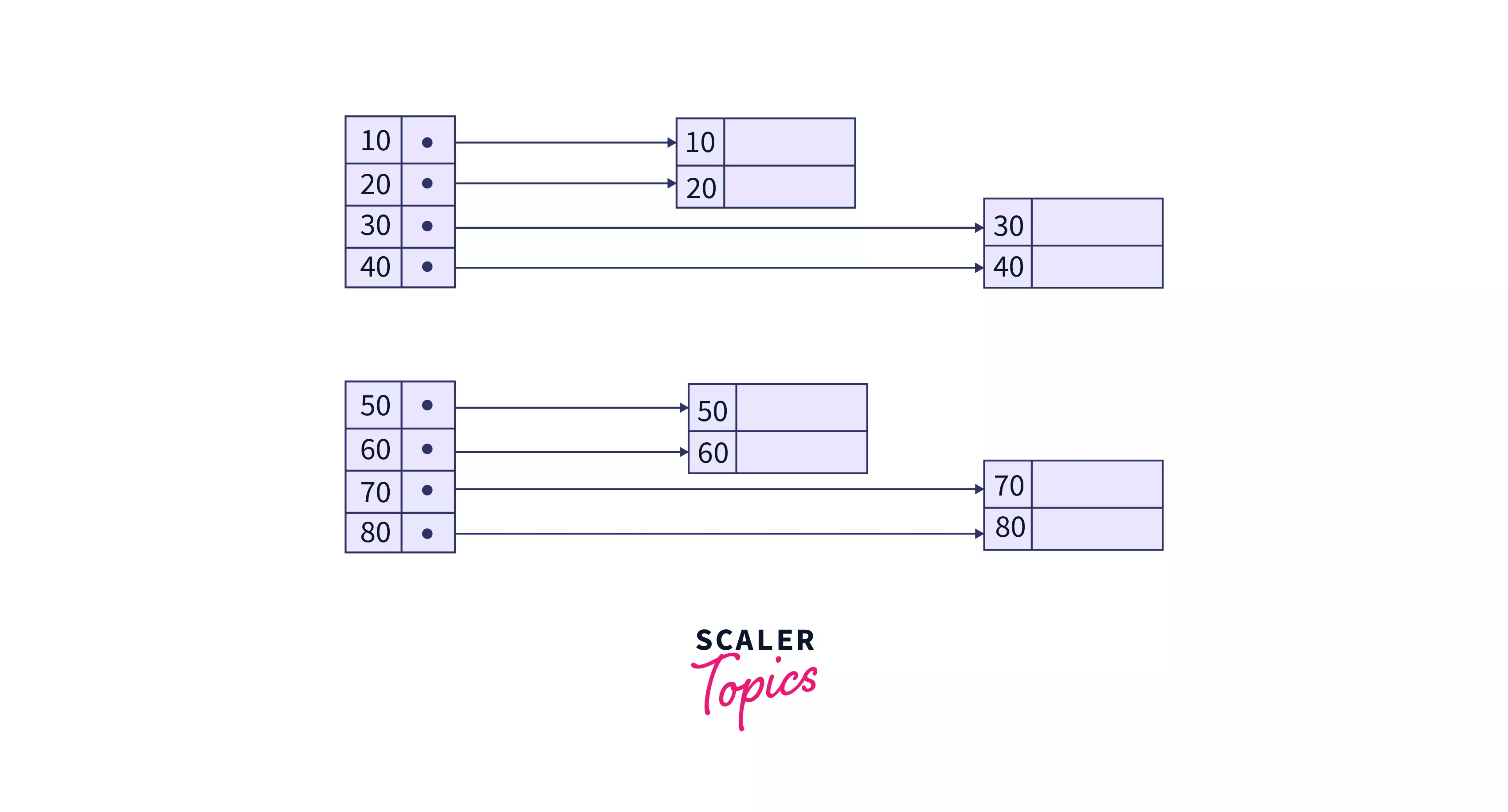
Dense Index
A record in DBMS is produced for each search key value in the database. Method entries in this Indexing contain a search key value and a pointer to the actual record on the disk. This allows the user to search more quickly, but it requires more storage space to store index information.
Distributed Database
Multiple independent databases that run on two or more linked computers and share data across a network are called distributed databases. The databases are typically housed across many physical locations. Each database is managed by its own database management system (DBMS).
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Data Manipulation Language (DML)
This is a programming language used to insert or modify or manipulate the data present in a database. It includes common SQL statements such as SELECT, INSERT, UPDATE,DELETE, etc. Read more about DML in DBMS.
Domain
It is a unique set of values that define the values that can be used for a particular attribute`. Eg: the Days_of_week attribute's domain will have 7 values namely Sunday, Monday, Tuesday, Wednesday, Thursday, Friday, and Saturday. Learn more about Domain in DBMS.
Domain Constraints
Domain constraints specify a valid set of values for an attribute. Domain data types include string, character, integer, time, date, currency, and so on. The attribute's value must be available in the relevant domain.
Domain Relational Calculus
In this, the filtering of records is done based on domain values.
Data Query Language (DQL)
This language is used for creating, processing, and executing queries.
End-user Database
The end user is typically indifferent about the transactions or processes that take place at various levels and is primarily concerned with the product, which might be software or an application. As a result, this is a shared database that is particularly created for end users, such as managers at various levels. This database contains a summary of all information.
Entity
Entity is an item that we take into consideration that could be a living or non-living being, place, object, etc. These are usually objects in the real word that we are tracking.
Entity Integrity Constraints
According to the entity integrity requirement, the primary key value cannot be null. This is due to the fact that the primary key is used to identify particular rows in a relation, and if the primary key contains a null value, we cannot identify those rows. Other than the primary key field, a table can have a null value.
Entity-Relationship Diagram (ERD)
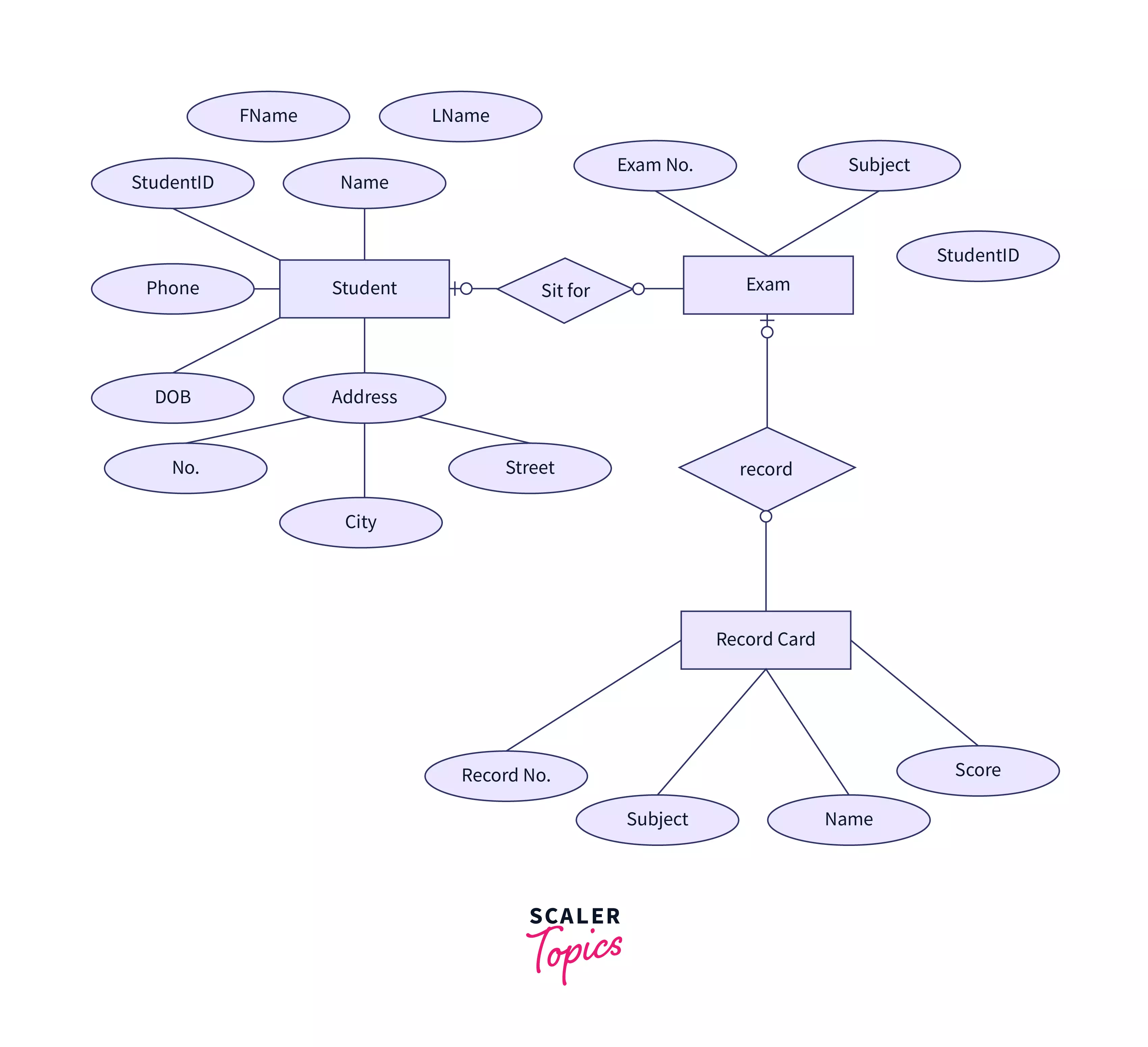
An entity relationship diagram (ERD) depicts the relationships between entity sets in a database. In this respect, an entity is an object - a data component. An entity set is a group of entities that are related in some manner. Attributes can be assigned to these entities to determine their properties. The following graph shows an example of an ERD for a student information system. Entities (Student, Exam, and Record Card) are displayed in rectangles, attributes (Eg: name, Fname, etc.) are displayed in ovals while the relationships (sit for, record) are represented as rhombuses. The primary key is identified using an underline on the attribute that is the primary key.
Equi Join
It performs a join operation against equality or matching column(s) values of the associated tables. An equal sign (=) is used to compare the values in the columns of the tables in consideration.
Fifth Normal Form (5NF)
A relation is in 5NF if it is in 4NF, does not have any join dependencies, and joining is lossless.
First Normal Form (1NF)
When there are no repeated groups inside a table, it is in 1NF. Each cell can only have one value.
Foreign Key
A column in one table that serves as the main key in another table. It is not necessary that it be a primary key in the first table.
Fourth Normal Form (4NF)
A relation is in 4NF if it is in Boyce Codd normal form and does not have any multi-valued dependencies. Read more about 4NF in DBMS.
Full Outer Join
A join that matches all rows from both tables that match, as well as all rows from the left table that do not match and all rows from the right table that do not match. Infrequently used and much more rarely accessible.
Function
A procedure that is intended to carry out a given computation. The distinction between a function and a subroutine is that a function returns a specified value while a subroutine does not (not including the parameters).
Functional Dependency
As the title suggests, functional dependency in DBMS is a relationship between table features that are reliant on each other. It aids in the prevention of data redundancy as well as the detection of faulty designs. Functional Dependency is denoted by the symbol ->. Eg: A->B
Graph Database
A graph-oriented database, often known as a graph database, is a form of NoSQL database that stores, maps, and queries relationships using graph theory. Graph databases are mostly used to examine connectivity. Companies, for example, may utilise a graph database to gather data about clients from social media.
Heterogeneous Database
Databases that have diverse Operating systems, underlying hardware and application methods at different locations.
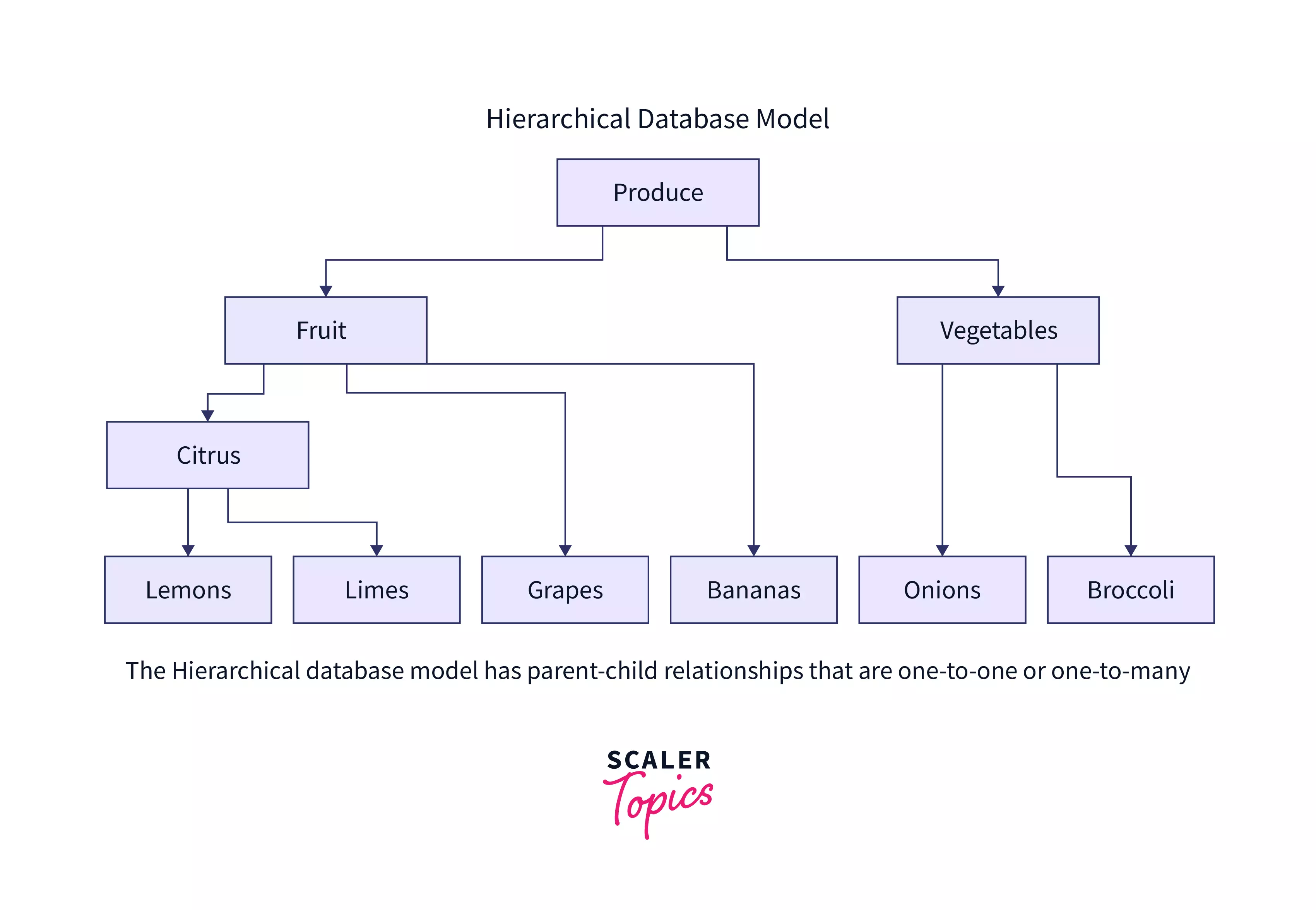
Hierarchical Database
A hierarchical database is a database management system (DBMS) that stores data in a tree-like structure. In such a structure, a single parent node can have numerous child nodes. It stores data in the form of records and connects them through links. Each record has fields, and each field has only one value. It arranges data in hierarchies such that data may be searched quickly from top to bottom.
Homogeneous Database
Databases that share the same underlying hardware, operating systems, and application procedures is called homogenous databases.
Indexing
If you are to identify or sequentially call out students in a class, you could use their roll numbers. It would help you to uniquely identify them and ensure that there is no duplicity. In DBMS, the index serves this purpose. The index is a sorted list of key values from the table in consideration along with pointers to the attributes in the row. Indexing optimizes the database by helping in faster searches and data retrieval.
Indexing Attributes
The sequential attributes that are used for indexing (i.e. identifying rows) are called indexing attributes.
Information
Processed data is known as information. Unlike data, information is well-structured and gives us valuable insights into the application in consideration.
Inner Join
A join condition in SQL that gives rows from two tables only if the attributes in the columns match exactly. Rows that have no match are not displayed.
Insertion Time
The time taken to locate a space for the insertion and then perform the insertion of the element.
Integrity Constraints
A collection of rules used to ensure the quality of information. Integrity constraints in DBMS require that data insertion, updating, and other activities be carried out in such a way that data integrity is not jeopardized. As a result, the integrity constraint is utilized to protect the database against inadvertent damage.
Intersection
The intersection operator returns the common data values between the intersected data sets. For the intersection operator to operate, the two data sets that are intersected must be similar. Any duplicates are eliminated before showing the result.
Irrecoverable Schedule
If a transaction in a schedule executes a dirty read operation from an uncommitted transaction and commits before the transaction from which the value was read, the schedule is known as an Irrecoverable Schedule.
Join
A Join in DBMS is a binary operation that is used to assist you in combining data from two or more DBMS tables. In DBMS, tables are linked together using primary and foreign keys.
Join Dependency
Join dependency in DBMS is a constraint that is met if and only if the relation in question is the join of a given number of projections.
Key Constraints
A key constraint states that an entity set can have multiple keys but only one of them will be called the primary key. This primary key can contain a unique and non-null value.
Keys
Keys are used to identify rows/entities uniquely. They aid in building relationships between data in different tables.
Left Outer Join
An outer join that includes all of the rows from the left table, even if the right table has no matching rows. Nulls are used to represent missing values.
Lossless Decomposition
The lossless decomposition ensures that joining relations results in the same relation that was decomposed. If natural joins of all the decompositions produce the original relation, the relation is said to be lossless decomposition.
Metadata
The description of the data tables and columns, or data about data. Typically stored in the data dictionary. Read more about Metadata in DBMS.
Method
It is an operation that can be performed by classes. An AddNewStudent function in a student class can be used to add new student objects and their related details.
Multi-level Index
The size of the indices develops in tandem with the growth of the database. There is an urgent requirement to maintain index records in main memory in order to speed up search operations. Multi-level indices are used to serve the purpose.
Multivalued Dependence
Multivalued dependence is a full constraint in a relation between two sets of attributes that occurs when there are numerous independent multivalued characteristics in a single table. It necessitates the presence of specific tuples in a relation.
Natural Join
Natural Join executes selection assuming equality on the attributes that exist in both relations and removes the duplicates. It does not use any comparison operators. The only criteria to satisfy this is that there should be at least one common attribute between the two relations.
Turn Learning into Career Growth
Network Database
A network database is created when the details of numerous members may be connected to the files of multiple owners and vice versa. A network database is distinguished by the need that all connections be indexed.
Non-Serial Schedules
A non-serial schedule is one that permits the interleaving of operations. It comprises a large number of different orders in which the system can carry out the separate activities of the transactions.
Non-Trivial Functional Dependency
A non-trivial dependency, exists when A->B holds true but B is not a subset of A.
Normalization
The process of designing a standardized set of tables to store data effectively, reduce redundancy, and assure data integrity. Click here to learn more about Normalization in DBMS.
NoSQL Database
NoSQl Databases are used for massive volumes of dispersed data. Some large data performance concerns are well addressed by relational databases; however, similar issues are easily controlled by NoSQL databases. They are particularly efficient at evaluating enormous amounts of unstructured data that may be stored on several cloud virtual servers.
Objected-Oriented Database
An object-oriented database combines the concepts of object-oriented programming and relational databases. For development, such databases make use of an object-oriented programming language. It is a database system that stores objects together with their features and methods. It allows object relations, including inheritance. The object-oriented database is structured around objects and data rather than actions or logic.
Online Analytical Processing (OLAP)
OLAP makes use of a database to analyse data. The emphasis is on data retrieval. The basic objectives are to offer appropriate response times, ensure security, and make it simple for users to obtain the information they want.
Online Transaction Processing (OLTP)
OLTP makes use of a database to process transactions. It is made up of multiple insert and update operations and can handle hundreds of concurrent accesses. The key objectives are high-speed data storage, dependability, and data integrity. Airline reservations, internet banking, and retail purchases are a few examples.
Outer Join
In an outer join, the table preserves each entry in this sort of join even if no other matching record exists. It does not need a matching record in each of the two join tables. Outer Joins are classified into three types: Left Outer Join, Right Outer Join, and Full Outer Join.
Precedence Graph
A precedence graph, also known as a serialization graph or conflict graph, is used to assess the Conflict Serializability of a schedule under the condition that determines the setting of concurrency control in databases.
Primary Index
An ordered data file has a primary index. The data file is sorted based on a key field. In most cases, the key field is the relation's primary key.
Primary Key
One or more columns that uniquely identify a row within a table.
Projection Operator
It returns those columns in a relation that given in the attribute list. The resulting table contains subset of columns.
Query
A command that helps retrieve data from the server. The retrieval can be based on the condition mentioned. Read more about Query in DBMS.
Query Processing
The action of extracting data from a database is known as query processing in DBMS. In query processing, multiple procedures are used to retrieve data from the database. Parsing and translation, optimization, and evaluation are the stages involved.
Recoverability
A transaction may fail to complete owing to a software fault, system crash, or hardware failure. In that instance, the unsuccessful transaction must be undone. However, the value generated by the unsuccessful transaction may have been utilised by another transaction as well. As a result, we must also restore those transactions. This process is referred to as recoverability.
Recoverable Schedule
A Recoverable Schedule exists when a transaction in a schedule executes a dirty read operation from an uncommitted transaction and its commit operation is postponed until the uncommitted transaction either commits or rolls back.
Referential Integrity Constraints
A data integrity constraint that states that data may only be inserted into a foreign key column if it already exists in the base table. To learn more about referential integrity constraints click here.
Relation
A relation is a table of values. Every row in the table represents a collection of related data values. A relation is called so as it gives the relation between different fields of a row.
Relational Data Model
It depicts the database as a set of relations.
Relational Database
A relational database is one that organises data as a series of tables with rows and columns that have a pre-defined relationship with one another. The most common type of database management system. Tables are used to hold all data. Tables are associated logically by the data they contain.
Relational Decomposition
When a relation in the relational model is not in the acceptable normal form, it must be decomposed. It divides a table into numerous tables in a database. If the connection is not properly decomposed, it may result in difficulties such as information loss.
Relational Model
The relational model in DBMS is the theoretical foundation of relational databases, which are a methodology of organising data through the use of relations, i.e., tables. Each relation has a name and is made up of named attributes or data columns. Each tuple or row has one value for each attribute. The relational model's main strength is the straightforward logical structure that it creates.
Rename Operator
It is used to assign a new name to a relation.
Replication
Data replication is the act of creating numerous copies of data and storing them in separate locations for backup, fault tolerance, and improved overall network accessibility. Data replicas can be kept in the same system, on-site and off-site servers, and cloud-based hosts.
Result Set
When you run a query on a database, you get a result set back. All of the records that satisfy your query are included in the result set. It is possible for a result set to be empty.
Right Outer Join
An outer join that includes all rows from the right table even if no matching rows exist in the left table. Nulls are used to represent missing values.
Rollback
A rollback signifies the failure of a transaction. When you roll back a transaction, you are instructing SQL to discard any database modifications you have made.
Schema
A set of tables that have been brought together for a shared purpose. A schema gives a better description about the kinds of attributes and their data types. To learn more about Schema in DBMS, click here.
Second Normal Form (2NF)
A table is classified as 2NF if every non - key attribute is dependent on the entire key (not just part of it). This problem occurs only when there is a concatenated key.
Secondary Index
Secondary index is one that can be created using either a candidate key with a unique value or a non-key field with duplicate values.
Selection Operator
It returns tuples (records/rows) from a relation that satisfy a criteria. A subset of rows will be included in the resultant table.
Self-Join
A table joined to itself.
Serial Schedules
These are schedules in which a transaction does not start excuting until the currently running transaction has completed. This method is also known as non-interleaved execution.
Serializable Schedules
Serializable schedules are those that ensure that the whole database is always in a consistent state after all successful transactions. The data in the database may or may not become inconsistent when several transactions are conducted. In terms of serializability, A serial schedule always assures serializability since another transaction in a serial schedule will proceed only after the preceding transaction has finished/executed. A serial schedule has no conflicts.
Serialization
Serialization ensures that each transaction is treated individually in isolation, i.e. without interfering with each other's operations.
Set Difference
The set difference operators compare two sets and return the values that are in the first but not in the second.
Space Overhead
The additional space required by index is called space overhead.
Sparse Index
Sparse Index keeps index entries for just a subset of search-key values. It requires less space and has a smaller maintenance cost for insertions and deletions, but it is slower for seeking data than a dense index.
Structured Query Language (SQL)
A structured and well-define programming lnaguage that is used for the purpose of softwares called database management system that consists of data in the form of tables.
States of Transaction
The states that a transaction passes through over its lifespan. These are the states that describe the present status of the transaction as well as how we will proceed with the processing in the transactions. The common states are given as follows:
-
Active State — When the transaction's instructions are being executed, the transaction is in an active state. If all the read and write operations are completed without any failure, the system enters the partially committed state; if any instruction fails, the system enters the failed state.
-
Partially Committed - After all read and write operations are completed, changes are made in main memory or the local buffer. If the modifications are made permanent in the database, the state will change to committed, and if they fail, the state will change to failed.
-
Failed State - When any transaction fails, it enters the failed state.
-
Aborted State — When a transaction fails, it moves from the failed state to the "aborted state," and because modifications are only made to the local buffer or main memory in prior states, these changes are erased or rolled back.
-
Committed State — This is the state in which the modifications to the database are made permanent and the transaction is completed and so ended in the terminated state.
-
Terminated State — If there is no rollback or the transaction originates from the committed state, the system is consistent and ready for a new transaction, and the previous one is terminated.
Super Key
A superkey in DBMS is a collection of one or more keys that identify rows in a database. A Super key may include extraneous features that aren't required for unique identification.
Table
A table is a collection of rows and columns given by a name. It is also known as relation.
Third Normal Form (3NF)
The third normal form is (3NF) A table is in third normal form (3NF) if each non-key column is entirely dependent on the key and nothing else.
Transactions
A transaction in DBMS is a set of database actions that are handled as a single entity. SQL ensures that all or none of the actions within a transaction complete. It guarantees that if something goes wrong in the middle of a transaction, any changes made before to the moment of failure will not be recorded in the database. A transaction is typically initiated with a BEGIN command and terminated with a COMMIT or ROLLBACK command.
Transitive Functional Dependency
In transitive functional dependency, the dependent (on the right) is indirectly dependent on determinant (on the left). i.e. If a → b & b → c, then according to the axiom of transitivity, a → c. This is a transitive functional dependency.
Trivial Functional Dependency
In Trivial Functional Dependency, a dependent (on the right) is always a subset of the determinant (on the left). i.e. If X → Y and Y is the subset of X, then it is called trivial functional dependency
Tuple
It represents a single row in a table, which is a single record. To learn more about tuples in DBMS, Click here.
Union
Union merges two separate query results into a single result in the form of a table. However, if the union is applied to them, the outcomes should be similar. Union eliminates all duplicates from the data and presents just distinct values. If the generated data contains duplicate values, UNION ALL is utilized.
View
A view is an alternative way to present a table. It is often termed as a virtual table, since it is not physically stored but is a representation of records from various tables. A view is a useful way to give a name to a complex query that is commonly used.
View Serializability
If a schedule is equivalent to a serial schedule, it is said to be view serializable. Every conflict serializable schedule is view serializable.
Wait-Die
If a transaction demands a resource that is locked by another transaction, the DBMS simply compares the timestamps of the two transactions and permits the older transaction to wait until the resource is free for execution. Checks whether TS (T1) TS (T2) – if T1 is the older transaction and T2 has held some resource, it permits T1 to wait until the resource is ready for execution. T2 is terminated and resumed later with a random delay but with the same date if T1 is an earlier transaction that has held some resource with it and if T2 is waiting for it.
Wound-Wait
If an older transaction demands a resource that is being held by a younger transaction, the older transaction compels the younger transaction to stop the transaction and release the resource. The younger transaction is repeated a minute later but with the same timestamp. If the younger transaction requests a resource that an older one is holding, the younger transaction is told to wait until the older one releases it.